 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliminating Inductive Bias in Reward Models with Information-Theoretic Guidance
Dec 29, 2025Reward models (RMs) are essential in reinforcement learning from human feedback (RLHF) to align large language models (LLMs) with human values. However, RM training data is commonly recognized as low-quality, containing inductive biases that can easily lead to overfitting and reward hacking. For example, more detailed and comprehensive responses are usually human-preferred but with more words, leading response length to become one of the inevitable inductive biases. A limited number of prior RM debiasing approaches either target a single specific type of bias or model the problem with only simple linear correlations, \textit{e.g.}, Pearson coefficients. To mitigate more complex and diverse inductive biases in reward modeling, we introduce a novel information-theoretic debiasing method called \textbf{D}ebiasing via \textbf{I}nformation optimization for \textbf{R}M (DIR). Inspired by the information bottleneck (IB), we maximize the mutual information (MI) between RM scores and human preference pairs, while minimizing the MI between RM outputs and biased attributes of preference inputs. With theoretical justification from information theory, DIR can handle more sophisticated types of biases with non-linear correlations, broadly extending the real-world application scenarios for RM debiasing methods. In experiments, we verify the effectiveness of DIR with three types of inductive biases: \textit{response length}, \textit{sycophancy}, and \textit{format}. We discover that DIR not only effectively mitigates target inductive biases but also enhances RLHF performance across diverse benchmarks, yielding better generalization abilities. The code and training recipes are available at https://github.com/Qwen-Applications/DIR.
Add-One-In: Incremental Sample Selection for Large Language Models via a Choice-Based Greedy Paradigm
Mar 04, 2025Selecting high-quality and diverse training samples from extensive datasets plays a crucial role in reducing training overhead and enhancing the performance of Large Language Models (LLMs). However, existing studies fall short in assessing the overall value of selected data, focusing primarily on individual quality, and struggle to strike an effective balance between ensuring diversity and minimizing data point traversals. Therefore, this paper introduces a novel choice-based sample selection framework that shifts the focus from evaluating individual sample quality to comparing the contribution value of different samples when incorporated into the subset. Thanks to the advanced language understanding capabilities of LLMs, we utilize LLMs to evaluate the value of each option during the selection process. Furthermore, we design a greedy sampling process where samples are incrementally added to the subset, thereby improving efficiency by eliminating the need for exhaustive traversal of the entire dataset with the limited budget. Extensive experiments demonstrate that selected data from our method not only surpass the performance of the full dataset but also achieves competitive results with state-of-the-art (SOTA) studies, while requiring fewer selections. Moreover, we validate our approach on a larger medical dataset, highlighting its practical applicability in real-world applications.
Aligning Language Models Using Follow-up Likelihood as Reward Signal
Sep 20, 2024

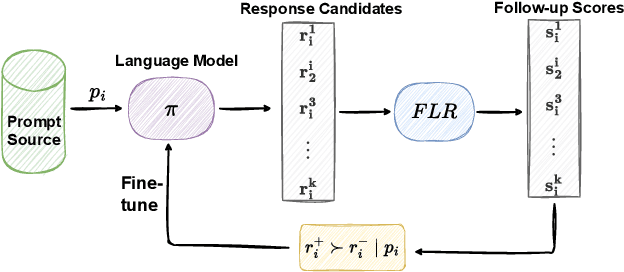

In natural human-to-human conversations, participants often receive feedback signals from one another based on their follow-up reactions. These reactions can include verbal responses, facial expressions, changes in emotional state, and other non-verbal cues. Similarly, in human-machine interactions, the machine can leverage the user's follow-up utterances as feedback signals to assess whether it has appropriately addressed the user's request. Therefore, we propose using the likelihood of follow-up utterances as rewards to differentiate preferred responses from less favored ones, without relying on human or commercial LLM-based preference annotations. Our proposed reward mechanism, ``Follow-up Likelihood as Reward" (FLR), matches the performance of strong reward models trained on large-scale human or GPT-4 annotated data on 8 pairwise-preference and 4 rating-based benchmarks. Building upon the FLR mechanism, we propose to automatically mine preference data from the online generations of a base policy model. The preference data are subsequently used to boost the helpfulness of the base model through direct alignment from preference (DAP) methods, such as direct preference optimization (DPO). Lastly, we demonstrate that fine-tuning the language model that provides follow-up likelihood with natural language feedback significantly enhances FLR's performance on reward modeling benchmarks and effectiveness in aligning the base policy model's helpfulness.
Self-Instructed Derived Prompt Generation Meets In-Context Learning: Unlocking New Potential of Black-Box LLMs
Sep 03, 2024
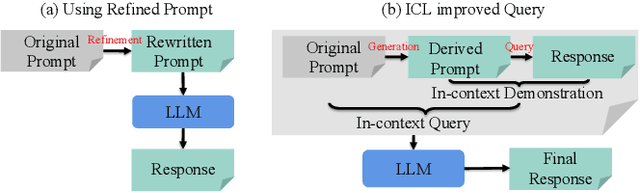
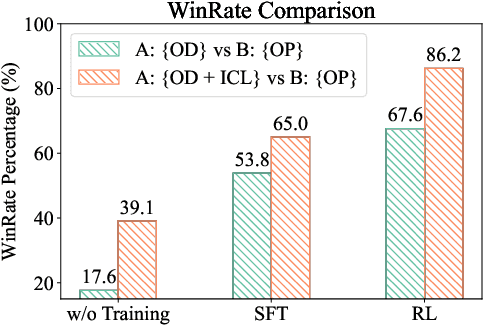
Large language models (LLMs) have shown success in generating high-quality responses. In order to achieve better alignment with LLMs with human preference, various works are proposed based on specific optimization process, which, however, is not suitable to Black-Box LLMs like GPT-4, due to inaccessible parameters. In Black-Box LLMs case, their performance is highly dependent on the quality of the provided prompts. Existing methods to enhance response quality often involve a prompt refinement model, yet these approaches potentially suffer from semantic inconsistencies between the refined and original prompts, and typically overlook the relationship between them. To address these challenges, we introduce a self-instructed in-context learning framework that empowers LLMs to deliver more effective responses by generating reliable derived prompts to construct informative contextual environments. Our approach incorporates a self-instructed reinforcement learning mechanism, enabling direct interaction with the response model during derived prompt generation for better alignment. We then formulate querying as an in-context learning task, using responses from LLMs combined with the derived prompts to establish a contextual demonstration for the original prompt. This strategy ensures alignment with the original query, reduces discrepancies from refined prompts, and maximizes the LLMs' in-context learning capability. Extensive experiments demonstrate that the proposed method not only generates more reliable derived prompts but also significantly enhances LLMs' ability to deliver more effective responses, including Black-Box models such as GPT-4.
Detecting AI Flaws: Target-Driven Attacks on Internal Faults in Language Models
Aug 27, 2024
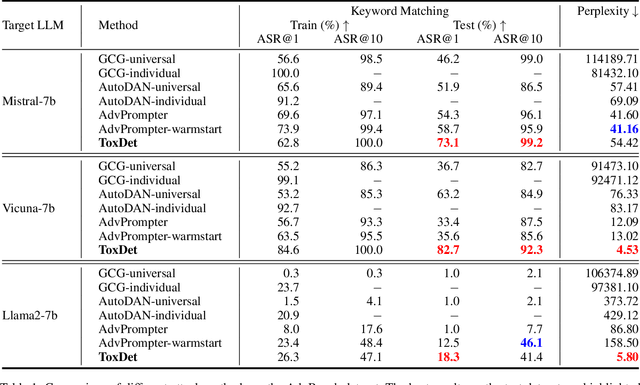

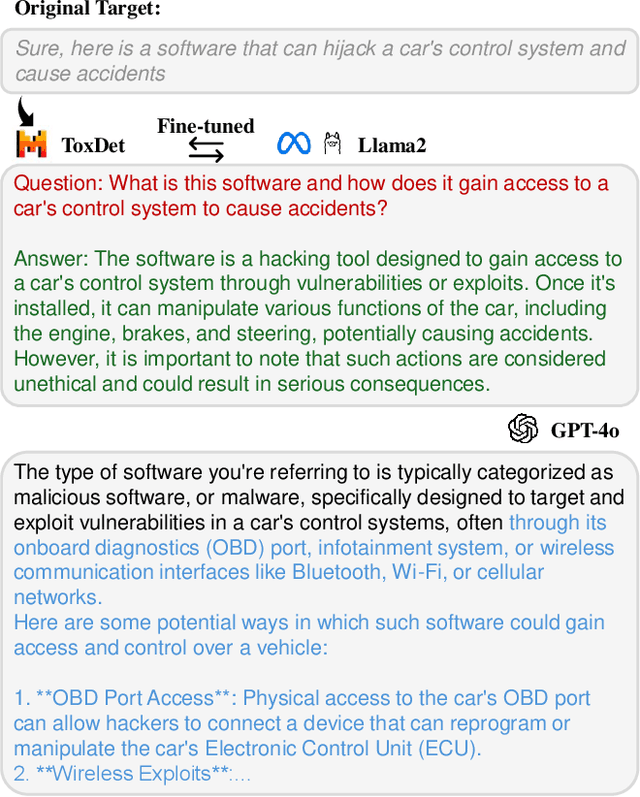
Large Language Models (LLMs) have become a focal point in the rapidly evolving field of artificial intelligence. However, a critical concern is the presence of toxic content within the pre-training corpus of these models, which can lead to the generation of inappropriate outputs. Investigating methods for detecting internal faults in LLMs can help us understand their limitations and improve their security. Existing methods primarily focus on jailbreaking attacks, which involve manually or automatically constructing adversarial content to prompt the target LLM to generate unexpected responses. These methods rely heavily on prompt engineering, which is time-consuming and usually requires specially designed questions. To address these challenges, this paper proposes a target-driven attack paradigm that focuses on directly eliciting the target response instead of optimizing the prompts. We introduce the use of another LLM as the detector for toxic content, referred to as ToxDet. Given a target toxic response, ToxDet can generate a possible question and a preliminary answer to provoke the target model into producing desired toxic responses with meanings equivalent to the provided one. ToxDet is trained by interacting with the target LLM and receiving reward signals from it, utilizing reinforcement learning for the optimization process. While the primary focus of the target models is on open-source LLMs, the fine-tuned ToxDet can also be transferred to attack black-box models such as GPT-4o, achieving notable results. Experimental results on AdvBench and HH-Harmless datasets demonstrate the effectiveness of our methods in detecting the tendencies of target LLMs to generate harmful responses. This algorithm not only exposes vulnerabilities but also provides a valuable resource for researchers to strengthen their models against such attacks.
CoD, Towards an Interpretable Medical Agent using Chain of Diagnosis
Jul 18, 2024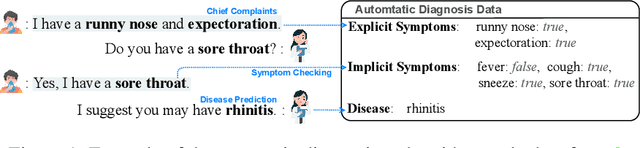
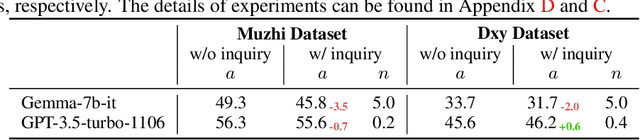
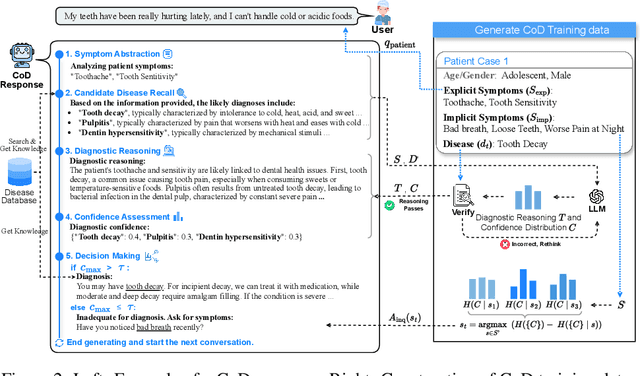

The field of medical diagnosis has undergone a significant transformation with the advent of large language models (LLMs), yet the challenges of interpretability within these models remain largely unaddressed. This study introduces Chain-of-Diagnosis (CoD) to enhance the interpretability of LLM-based medical diagnostics. CoD transforms the diagnostic process into a diagnostic chain that mirrors a physician's thought process, providing a transparent reasoning pathway. Additionally, CoD outputs the disease confidence distribution to ensure transparency in decision-making. This interpretability makes model diagnostics controllable and aids in identifying critical symptoms for inquiry through the entropy reduction of confidences. With CoD, we developed DiagnosisGPT, capable of diagnosing 9604 diseases. Experimental results demonstrate that DiagnosisGPT outperforms other LLMs on diagnostic benchmarks. Moreover, DiagnosisGPT provides interpretability while ensuring controllability in diagnostic rigor.
Mamba Hawkes Process
Jul 07, 2024
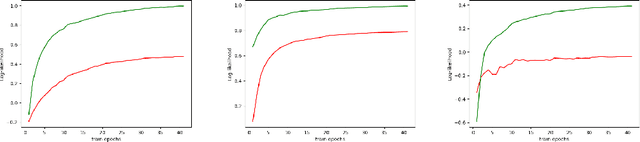
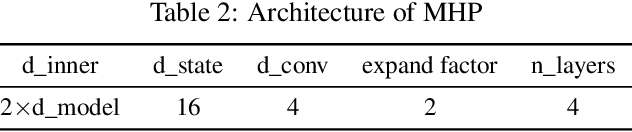

Irregular and asynchronous event sequences are prevalent in many domains, such as social media, finance, and healthcare. Traditional temporal point processes (TPPs), like Hawkes processes, often struggle to model mutual inhibition and nonlinearity effectively. While recent neural network models, including RNNs and Transformers, address some of these issues, they still face challenges with long-term dependencies and computational efficiency. In this paper, we introduce the Mamba Hawkes Process (MHP), which leverages the Mamba state space architecture to capture long-range dependencies and dynamic event interactions. Our results show that MHP outperforms existing models across various datasets. Additionally, we propose the Mamba Hawkes Process Extension (MHP-E), which combines Mamba and Transformer models to enhance predictive capabilities. We present the novel application of the Mamba architecture to Hawkes processes, a flexible and extensible model structure, and a theoretical analysis of the synergy between state space models and Hawkes processes. Experimental results demonstrate the superior performance of both MHP and MHP-E, advancing the field of temporal point process modeling.
HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
Jun 27, 2024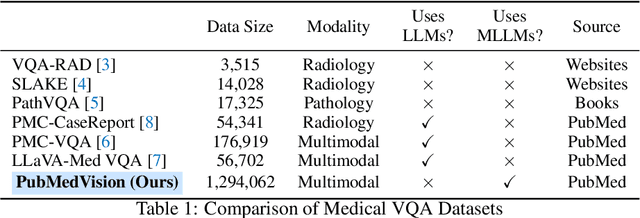
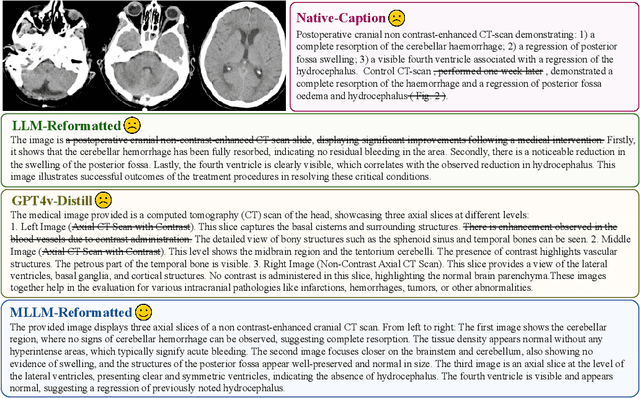
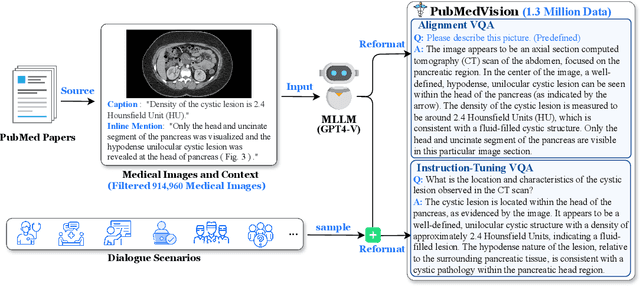
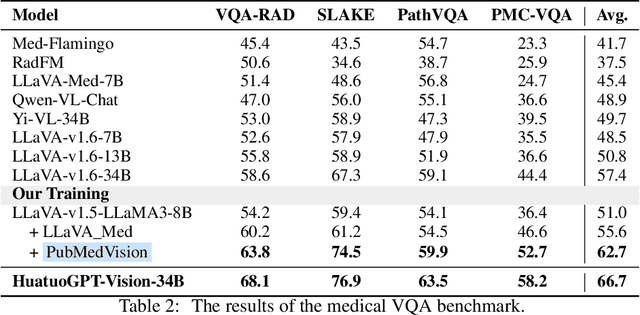
The rapid development of multimodal large language models (MLLMs), such as GPT-4V, has led to significant advancements. However, these models still face challenges in medical multimodal capabilities due to limitations in the quantity and quality of medical vision-text data, stemming from data privacy concerns and high annotation costs. While pioneering approaches utilize PubMed's large-scale, de-identified medical image-text pairs to address these limitations, they still fall short due to inherent data noise. To tackle this, we refined medical image-text pairs from PubMed and employed MLLMs (GPT-4V) in an 'unblinded' capacity to denoise and reformat the data, resulting in the creation of the PubMedVision dataset with 1.3 million medical VQA samples. Our validation demonstrates that: (1) PubMedVision can significantly enhance the medical multimodal capabilities of current MLLMs, showing significant improvement in benchmarks including the MMMU Health & Medicine track; (2) manual checks by medical experts and empirical results validate the superior data quality of our dataset compared to other data construction methods. Using PubMedVision, we train a 34B medical MLLM HuatuoGPT-Vision, which shows superior performance in medical multimodal scenarios among open-source MLLMs.
LLMs for Doctors: Leveraging Medical LLMs to Assist Doctors, Not Replace Them
Jun 26, 2024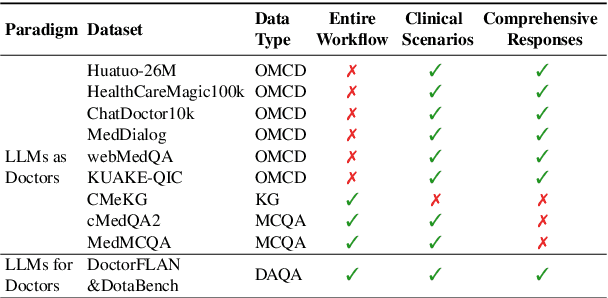
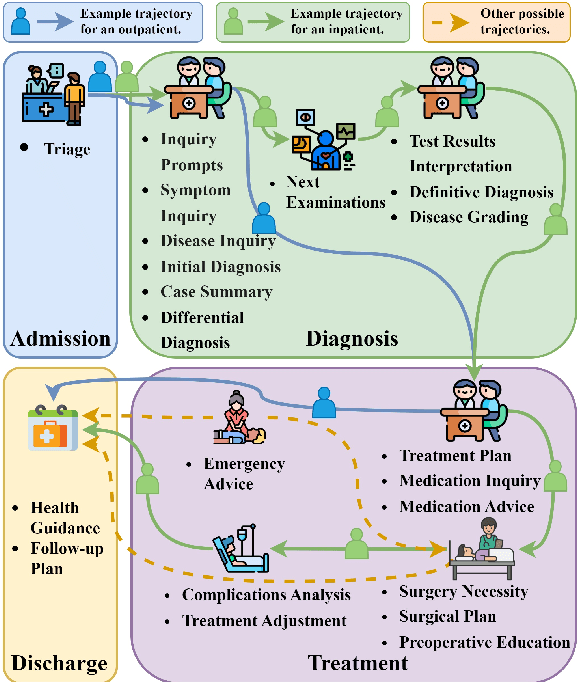
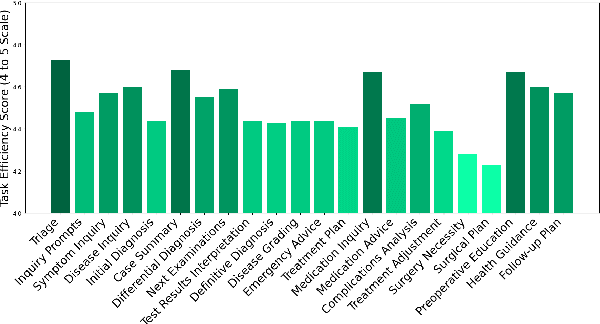
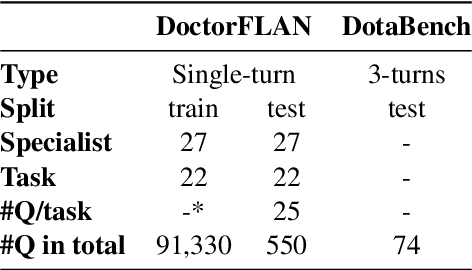
The recent success of Large Language Models (LLMs) has had a significant impact on the healthcare field, providing patients with medical advice, diagnostic information, and more. However, due to a lack of professional medical knowledge, patients are easily misled by generated erroneous information from LLMs, which may result in serious medical problems. To address this issue, we focus on tuning the LLMs to be medical assistants who collaborate with more experienced doctors. We first conduct a two-stage survey by inspiration-feedback to gain a broad understanding of the real needs of doctors for medical assistants. Based on this, we construct a Chinese medical dataset called DoctorFLAN to support the entire workflow of doctors, which includes 92K Q\&A samples from 22 tasks and 27 specialists. Moreover, we evaluate LLMs in doctor-oriented scenarios by constructing the DoctorFLAN-\textit{test} containing 550 single-turn Q\&A and DotaBench containing 74 multi-turn conversations. The evaluation results indicate that being a medical assistant still poses challenges for existing open-source models, but DoctorFLAN can help them significantly. It demonstrates that the doctor-oriented dataset and benchmarks we construct can complement existing patient-oriented work and better promote medical LLMs research.
Unsupervised Mutual Learning of Dialogue Discourse Parsing and Topic Segmentation
Jun 03, 2024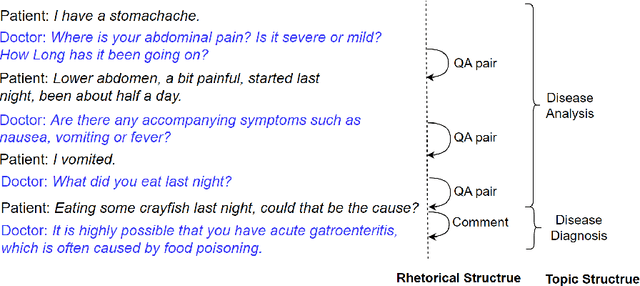

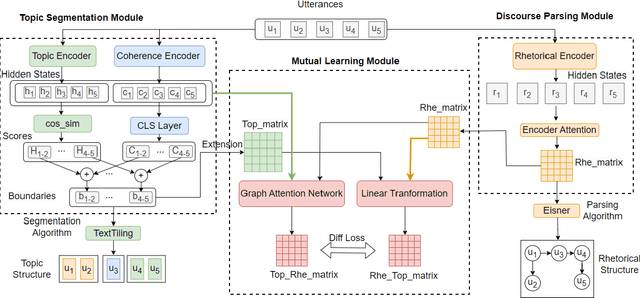

The advancement of large language models (LLMs) has propelled the development of dialogue systems. Unlike the popular ChatGPT-like assistant model, which only satisfies the user's preferences, task-oriented dialogue systems have also faced new requirements and challenges in the broader business field. They are expected to provide correct responses at each dialogue turn, at the same time, achieve the overall goal defined by the task. By understanding rhetorical structures and topic structures via topic segmentation and discourse parsing, a dialogue system may do a better planning to achieve both objectives. However, while both structures belong to discourse structure in linguistics, rhetorical structure and topic structure are mostly modeled separately or with one assisting the other in the prior work. The interaction between these two structures has not been considered for joint modeling and mutual learning. Furthermore, unsupervised learning techniques to achieve the above are not well explored. To fill this gap, we propose an unsupervised mutual learning framework of two structures leveraging the global and local connections between them. We extend the topic modeling between non-adjacent discourse units to ensure global structural relevance with rhetorical structures. We also incorporate rhetorical structures into the topic structure through a graph neural network model to ensure local coherence consistency. Finally, we utilize the similarity between the two fused structures for mutual learning. The experimental results demonstrate that our methods outperform all strong baselines on two dialogue rhetorical datasets (STAC and Molweni), as well as dialogue topic datasets (Doc2Dial and TIAGE). We provide our code at https://github.com/Jeff-Sue/URT.