 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
Jun 27, 2024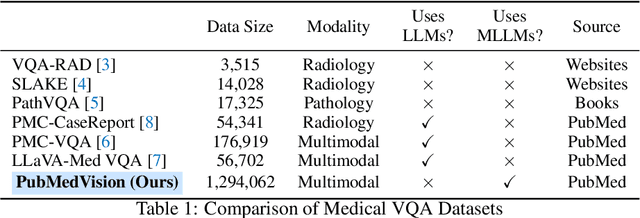
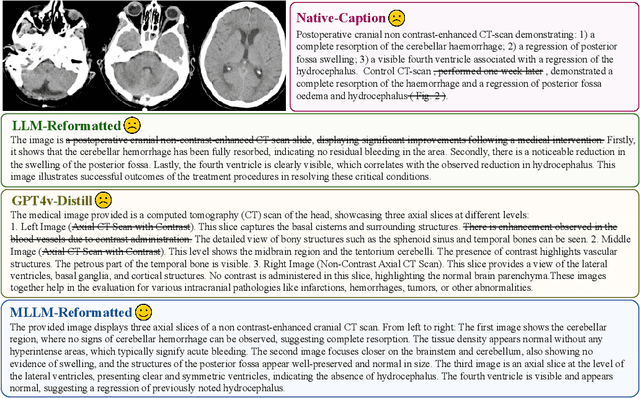
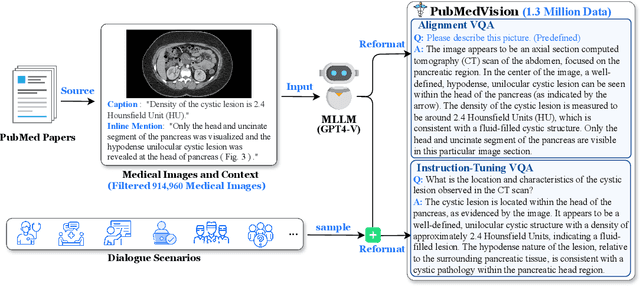
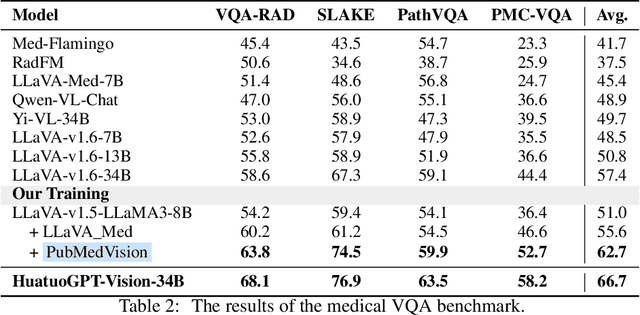
The rapid development of multimodal large language models (MLLMs), such as GPT-4V, has led to significant advancements. However, these models still face challenges in medical multimodal capabilities due to limitations in the quantity and quality of medical vision-text data, stemming from data privacy concerns and high annotation costs. While pioneering approaches utilize PubMed's large-scale, de-identified medical image-text pairs to address these limitations, they still fall short due to inherent data noise. To tackle this, we refined medical image-text pairs from PubMed and employed MLLMs (GPT-4V) in an 'unblinded' capacity to denoise and reformat the data, resulting in the creation of the PubMedVision dataset with 1.3 million medical VQA samples. Our validation demonstrates that: (1) PubMedVision can significantly enhance the medical multimodal capabilities of current MLLMs, showing significant improvement in benchmarks including the MMMU Health & Medicine track; (2) manual checks by medical experts and empirical results validate the superior data quality of our dataset compared to other data construction methods. Using PubMedVision, we train a 34B medical MLLM HuatuoGPT-Vision, which shows superior performance in medical multimodal scenarios among open-source MLLMs.