 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLDrive: Vision-Augmented Lightweight MLLMs for Efficient Language-grounded Autonomous Driving
Nov 09, 2025Recent advancements in language-grounded autonomous driving have been significantly promoted by the sophisticated cognition and reasoning capabilities of large language models (LLMs). However, current LLM-based approaches encounter critical challenges: (1) Failure analysis reveals that frequent collisions and obstructions, stemming from limitations in visual representations, remain primary obstacles to robust driving performance. (2) The substantial parameters of LLMs pose considerable deployment hurdles. To address these limitations, we introduce VLDrive, a novel approach featuring a lightweight MLLM architecture with enhanced vision components. VLDrive achieves compact visual tokens through innovative strategies, including cycle-consistent dynamic visual pruning and memory-enhanced feature aggregation. Furthermore, we propose a distance-decoupled instruction attention mechanism to improve joint visual-linguistic feature learning, particularly for long-range visual tokens. Extensive experiments conducted in the CARLA simulator demonstrate VLDrive`s effectiveness. Notably, VLDrive achieves state-of-the-art driving performance while reducing parameters by 81% (from 7B to 1.3B), yielding substantial driving score improvements of 15.4%, 16.8%, and 7.6% at tiny, short, and long distances, respectively, in closed-loop evaluations. Code is available at https://github.com/ReaFly/VLDrive.
AdaDrive: Self-Adaptive Slow-Fast System for Language-Grounded Autonomous Driving
Nov 09, 2025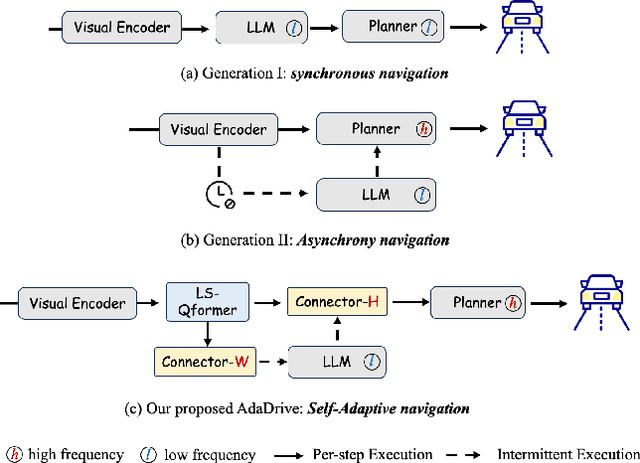
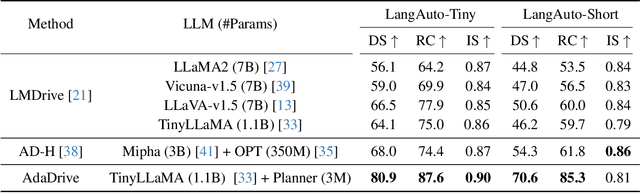
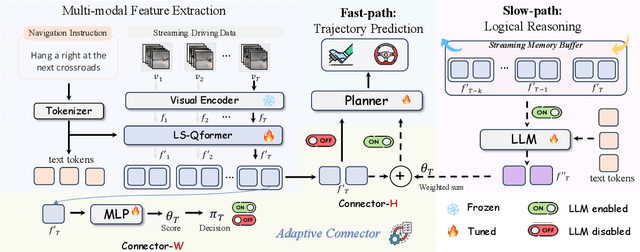
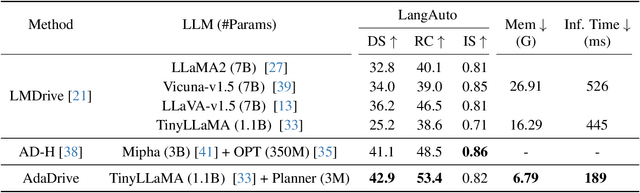
Effectively integrating Large Language Models (LLMs) into autonomous driving requires a balance between leveraging high-level reasoning and maintaining real-time efficiency. Existing approaches either activate LLMs too frequently, causing excessive computational overhead, or use fixed schedules, failing to adapt to dynamic driving conditions. To address these challenges, we propose AdaDrive, an adaptively collaborative slow-fast framework that optimally determines when and how LLMs contribute to decision-making. (1) When to activate the LLM: AdaDrive employs a novel adaptive activation loss that dynamically determines LLM invocation based on a comparative learning mechanism, ensuring activation only in complex or critical scenarios. (2) How to integrate LLM assistance: Instead of rigid binary activation, AdaDrive introduces an adaptive fusion strategy that modulates a continuous, scaled LLM influence based on scene complexity and prediction confidence, ensuring seamless collaboration with conventional planners. Through these strategies, AdaDrive provides a flexible, context-aware framework that maximizes decision accuracy without compromising real-time performance. Extensive experiments on language-grounded autonomous driving benchmarks demonstrate that AdaDrive state-of-the-art performance in terms of both driving accuracy and computational efficiency. Code is available at https://github.com/ReaFly/AdaDrive.
HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
Jun 27, 2024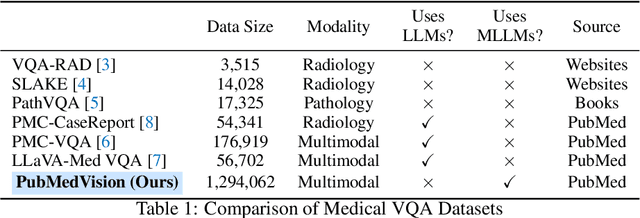
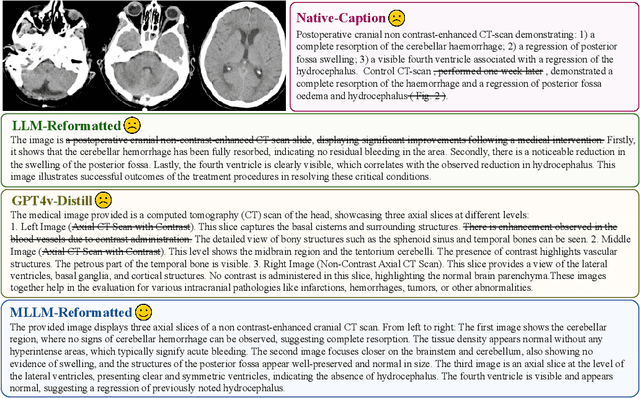
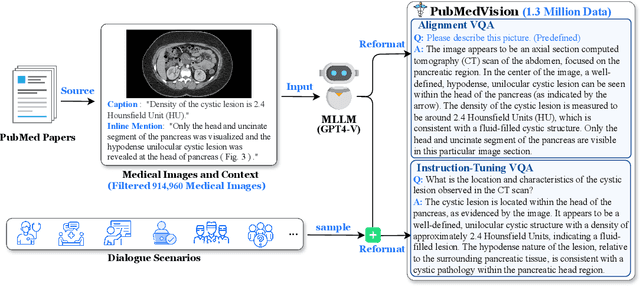
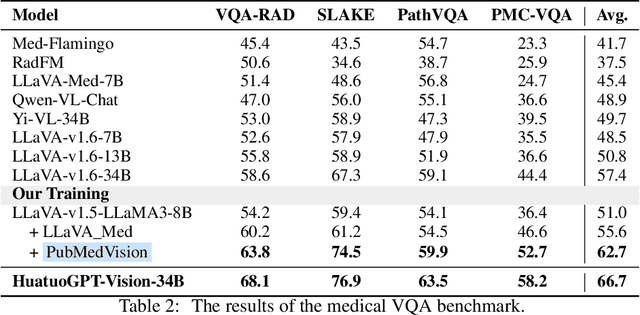
The rapid development of multimodal large language models (MLLMs), such as GPT-4V, has led to significant advancements. However, these models still face challenges in medical multimodal capabilities due to limitations in the quantity and quality of medical vision-text data, stemming from data privacy concerns and high annotation costs. While pioneering approaches utilize PubMed's large-scale, de-identified medical image-text pairs to address these limitations, they still fall short due to inherent data noise. To tackle this, we refined medical image-text pairs from PubMed and employed MLLMs (GPT-4V) in an 'unblinded' capacity to denoise and reformat the data, resulting in the creation of the PubMedVision dataset with 1.3 million medical VQA samples. Our validation demonstrates that: (1) PubMedVision can significantly enhance the medical multimodal capabilities of current MLLMs, showing significant improvement in benchmarks including the MMMU Health & Medicine track; (2) manual checks by medical experts and empirical results validate the superior data quality of our dataset compared to other data construction methods. Using PubMedVision, we train a 34B medical MLLM HuatuoGPT-Vision, which shows superior performance in medical multimodal scenarios among open-source MLLMs.
Large Multimodal Agents: A Survey
Feb 23, 2024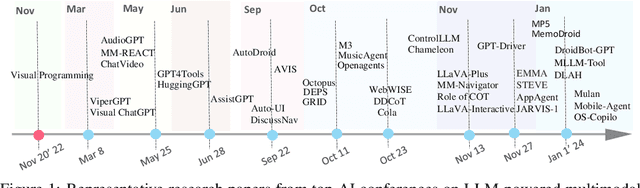
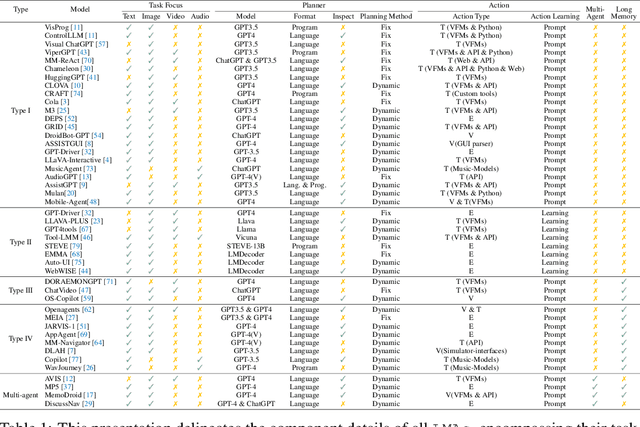
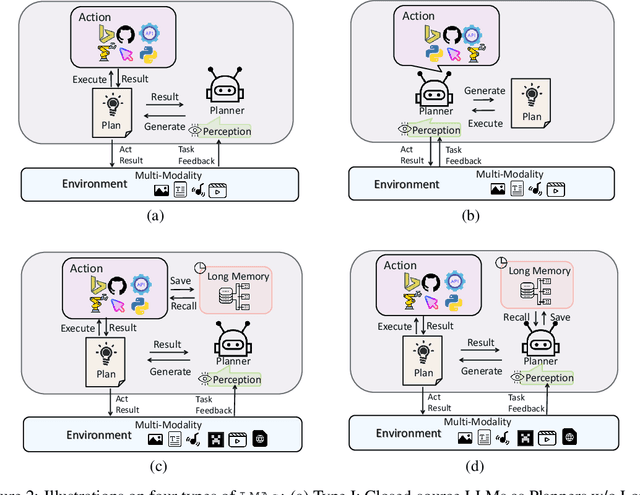
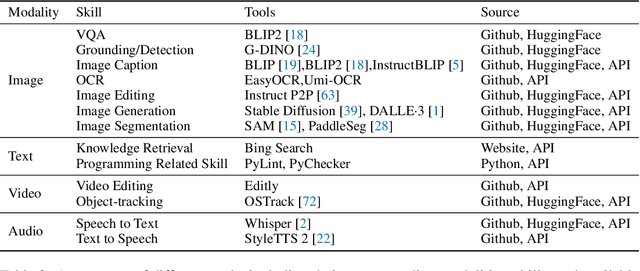
Large language models (LLMs) have achieved superior performance in powering text-based AI agents, endowing them with decision-making and reasoning abilities akin to humans. Concurrently, there is an emerging research trend focused on extending these LLM-powered AI agents into the multimodal domain. This extension enables AI agents to interpret and respond to diverse multimodal user queries, thereby handling more intricate and nuanced tasks. In this paper, we conduct a systematic review of LLM-driven multimodal agents, which we refer to as large multimodal agents ( LMAs for short). First, we introduce the essential components involved in developing LMAs and categorize the current body of research into four distinct types. Subsequently, we review the collaborative frameworks integrating multiple LMAs , enhancing collective efficacy. One of the critical challenges in this field is the diverse evaluation methods used across existing studies, hindering effective comparison among different LMAs . Therefore, we compile these evaluation methodologies and establish a comprehensive framework to bridge the gaps. This framework aims to standardize evaluations, facilitating more meaningful comparisons. Concluding our review, we highlight the extensive applications of LMAs and propose possible future research directions. Our discussion aims to provide valuable insights and guidelines for future research in this rapidly evolving field. An up-to-date resource list is available at https://github.com/jun0wanan/awesome-large-multimodal-agents.
ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model
Feb 18, 2024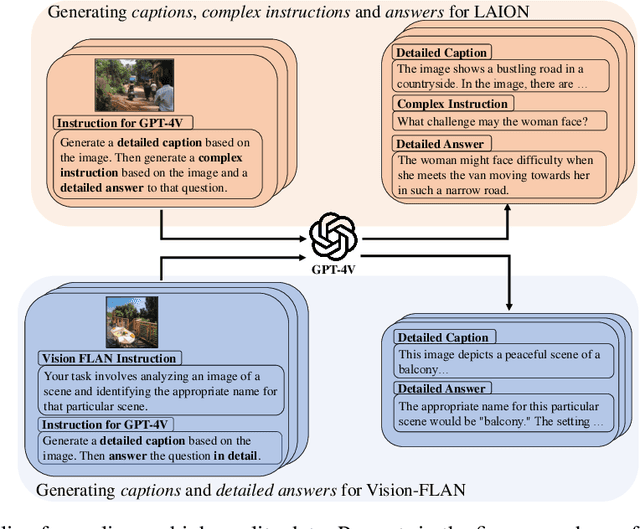
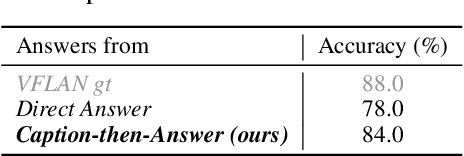

Recent advancements in Large Vision-Language Models (LVLMs) have enabled processing of multimodal inputs in language models but require significant computational resources for deployment, especially in edge devices. This study aims to bridge the performance gap between traditional-scale LVLMs and resource-friendly lite versions by adopting high-quality training data. To do this, a synthetic dataset is created by leveraging GPT-4V's ability to generate detailed captions, complex reasoning instructions and detailed answers from images. The resulted model trained with our data, ALLaVA, achieves competitive performance on 12 benchmarks up to 3B LVLMs. This work highlights the feasibility of adopting high-quality data in crafting more efficient LVLMs. Our online demo is available at \url{https://allava.freedomai.cn}.
Advancing Visual Grounding with Scene Knowledge: Benchmark and Method
Jul 21, 2023



Visual grounding (VG) aims to establish fine-grained alignment between vision and language. Ideally, it can be a testbed for vision-and-language models to evaluate their understanding of the images and texts and their reasoning abilities over their joint space. However, most existing VG datasets are constructed using simple description texts, which do not require sufficient reasoning over the images and texts. This has been demonstrated in a recent study~\cite{luo2022goes}, where a simple LSTM-based text encoder without pretraining can achieve state-of-the-art performance on mainstream VG datasets. Therefore, in this paper, we propose a novel benchmark of \underline{S}cene \underline{K}nowledge-guided \underline{V}isual \underline{G}rounding (SK-VG), where the image content and referring expressions are not sufficient to ground the target objects, forcing the models to have a reasoning ability on the long-form scene knowledge. To perform this task, we propose two approaches to accept the triple-type input, where the former embeds knowledge into the image features before the image-query interaction; the latter leverages linguistic structure to assist in computing the image-text matching. We conduct extensive experiments to analyze the above methods and show that the proposed approaches achieve promising results but still leave room for improvement, including performance and interpretability. The dataset and code are available at \url{https://github.com/zhjohnchan/SK-VG}.
Adaptive Context Selection for Polyp Segmentation
Jan 12, 2023Accurate polyp segmentation is of great significance for the diagnosis and treatment of colorectal cancer. However, it has always been very challenging due to the diverse shape and size of polyp. In recent years, state-of-the-art methods have achieved significant breakthroughs in this task with the help of deep convolutional neural networks. However, few algorithms explicitly consider the impact of the size and shape of the polyp and the complex spatial context on the segmentation performance, which results in the algorithms still being powerless for complex samples. In fact, segmentation of polyps of different sizes relies on different local and global contextual information for regional contrast reasoning. To tackle these issues, we propose an adaptive context selection based encoder-decoder framework which is composed of Local Context Attention (LCA) module, Global Context Module (GCM) and Adaptive Selection Module (ASM). Specifically, LCA modules deliver local context features from encoder layers to decoder layers, enhancing the attention to the hard region which is determined by the prediction map of previous layer. GCM aims to further explore the global context features and send to the decoder layers. ASM is used for adaptive selection and aggregation of context features through channel-wise attention. Our proposed approach is evaluated on the EndoScene and Kvasir-SEG Datasets, and shows outstanding performance compared with other state-of-the-art methods. The code is available at https://github.com/ReaFly/ACSNet.
Lesion-aware Dynamic Kernel for Polyp Segmentation
Jan 12, 2023Automatic and accurate polyp segmentation plays an essential role in early colorectal cancer diagnosis. However, it has always been a challenging task due to 1) the diverse shape, size, brightness and other appearance characteristics of polyps, 2) the tiny contrast between concealed polyps and their surrounding regions. To address these problems, we propose a lesion-aware dynamic network (LDNet) for polyp segmentation, which is a traditional u-shape encoder-decoder structure incorporated with a dynamic kernel generation and updating scheme. Specifically, the designed segmentation head is conditioned on the global context features of the input image and iteratively updated by the extracted lesion features according to polyp segmentation predictions. This simple but effective scheme endows our model with powerful segmentation performance and generalization capability. Besides, we utilize the extracted lesion representation to enhance the feature contrast between the polyp and background regions by a tailored lesion-aware cross-attention module (LCA), and design an efficient self-attention module (ESA) to capture long-range context relations, further improving the segmentation accuracy. Extensive experiments on four public polyp benchmarks and our collected large-scale polyp dataset demonstrate the superior performance of our method compared with other state-of-the-art approaches. The source code is available at https://github.com/ReaFly/LDNet.
Self-Supervised Correction Learning for Semi-Supervised Biomedical Image Segmentation
Jan 12, 2023Biomedical image segmentation plays a significant role in computer-aided diagnosis. However, existing CNN based methods rely heavily on massive manual annotations, which are very expensive and require huge human resources. In this work, we adopt a coarse-to-fine strategy and propose a self-supervised correction learning paradigm for semi-supervised biomedical image segmentation. Specifically, we design a dual-task network, including a shared encoder and two independent decoders for segmentation and lesion region inpainting, respectively. In the first phase, only the segmentation branch is used to obtain a relatively rough segmentation result. In the second step, we mask the detected lesion regions on the original image based on the initial segmentation map, and send it together with the original image into the network again to simultaneously perform inpainting and segmentation separately. For labeled data, this process is supervised by the segmentation annotations, and for unlabeled data, it is guided by the inpainting loss of masked lesion regions. Since the two tasks rely on similar feature information, the unlabeled data effectively enhances the representation of the network to the lesion regions and further improves the segmentation performance. Moreover, a gated feature fusion (GFF) module is designed to incorporate the complementary features from the two tasks. Experiments on three medical image segmentation datasets for different tasks including polyp, skin lesion and fundus optic disc segmentation well demonstrate the outstanding performance of our method compared with other semi-supervised approaches. The code is available at https://github.com/ReaFly/SemiMedSeg.
FastSeq: Make Sequence Generation Faster
Jun 08, 2021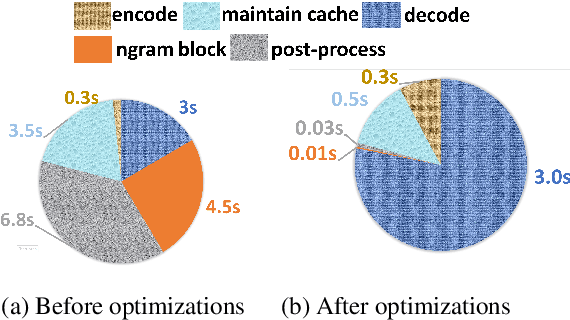
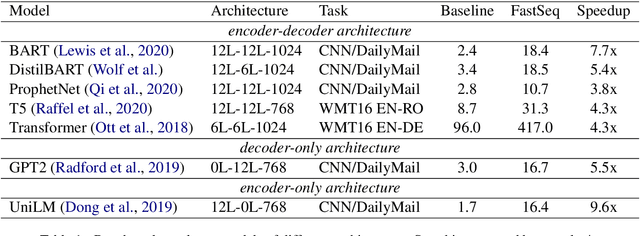
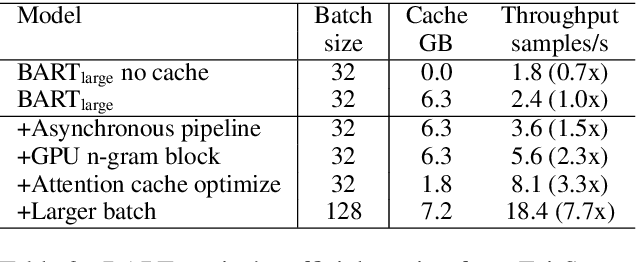
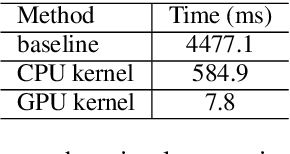
Transformer-based models have made tremendous impacts in natural language generation. However the inference speed is a bottleneck due to large model size and intensive computing involved in auto-regressive decoding process. We develop FastSeq framework to accelerate sequence generation without accuracy loss. The proposed optimization techniques include an attention cache optimization, an efficient algorithm for detecting repeated n-grams, and an asynchronous generation pipeline with parallel I/O. These optimizations are general enough to be applicable to Transformer-based models (e.g., T5, GPT2, and UniLM). Our benchmark results on a set of widely used and diverse models demonstrate 4-9x inference speed gain. Additionally, FastSeq is easy to use with a simple one-line code change. The source code is available at https://github.com/microsoft/fastseq.