 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDentalGPT: Incentivizing Multimodal Complex Reasoning in Dentistry
Dec 12, 2025Reliable interpretation of multimodal data in dentistry is essential for automated oral healthcare, yet current multimodal large language models (MLLMs) struggle to capture fine-grained dental visual details and lack sufficient reasoning ability for precise diagnosis. To address these limitations, we present DentalGPT, a specialized dental MLLM developed through high-quality domain knowledge injection and reinforcement learning. Specifically, the largest annotated multimodal dataset for dentistry to date was constructed by aggregating over 120k dental images paired with detailed descriptions that highlight diagnostically relevant visual features, making it the multimodal dataset with the most extensive collection of dental images to date. Training on this dataset significantly enhances the MLLM's visual understanding of dental conditions, while the subsequent reinforcement learning stage further strengthens its capability for multimodal complex reasoning. Comprehensive evaluations on intraoral and panoramic benchmarks, along with dental subsets of medical VQA benchmarks, show that DentalGPT achieves superior performance in disease classification and dental VQA tasks, outperforming many state-of-the-art MLLMs despite having only 7B parameters. These results demonstrate that high-quality dental data combined with staged adaptation provides an effective pathway for building capable and domain-specialized dental MLLMs.
ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Aug 20, 2025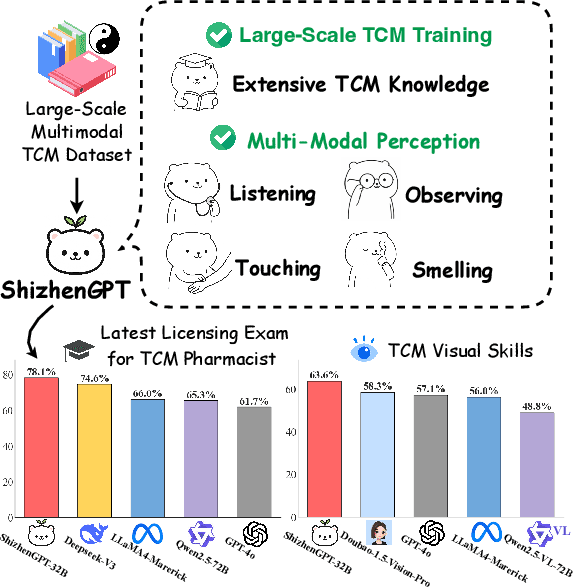
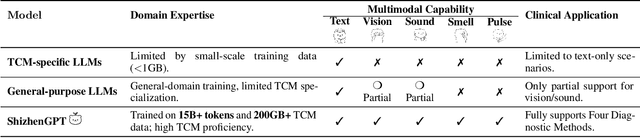
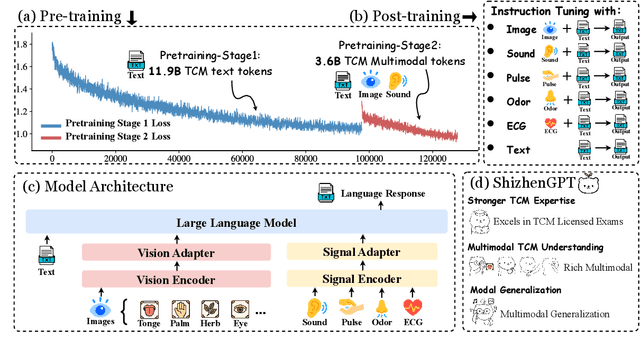
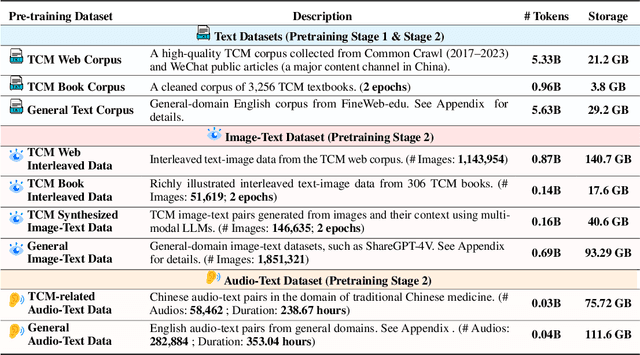
Despite the success of large language models (LLMs) in various domains, their potential in Traditional Chinese Medicine (TCM) remains largely underexplored due to two critical barriers: (1) the scarcity of high-quality TCM data and (2) the inherently multimodal nature of TCM diagnostics, which involve looking, listening, smelling, and pulse-taking. These sensory-rich modalities are beyond the scope of conventional LLMs. To address these challenges, we present ShizhenGPT, the first multimodal LLM tailored for TCM. To overcome data scarcity, we curate the largest TCM dataset to date, comprising 100GB+ of text and 200GB+ of multimodal data, including 1.2M images, 200 hours of audio, and physiological signals. ShizhenGPT is pretrained and instruction-tuned to achieve deep TCM knowledge and multimodal reasoning. For evaluation, we collect recent national TCM qualification exams and build a visual benchmark for Medicinal Recognition and Visual Diagnosis. Experiments demonstrate that ShizhenGPT outperforms comparable-scale LLMs and competes with larger proprietary models. Moreover, it leads in TCM visual understanding among existing multimodal LLMs and demonstrates unified perception across modalities like sound, pulse, smell, and vision, paving the way toward holistic multimodal perception and diagnosis in TCM. Datasets, models, and code are publicly available. We hope this work will inspire further exploration in this field.
Towards Assessing Medical Ethics from Knowledge to Practice
Aug 07, 2025The integration of large language models into healthcare necessitates a rigorous evaluation of their ethical reasoning, an area current benchmarks often overlook. We introduce PrinciplismQA, a comprehensive benchmark with 3,648 questions designed to systematically assess LLMs' alignment with core medical ethics. Grounded in Principlism, our benchmark features a high-quality dataset. This includes multiple-choice questions curated from authoritative textbooks and open-ended questions sourced from authoritative medical ethics case study literature, all validated by medical experts. Our experiments reveal a significant gap between models' ethical knowledge and their practical application, especially in dynamically applying ethical principles to real-world scenarios. Most LLMs struggle with dilemmas concerning Beneficence, often over-emphasizing other principles. Frontier closed-source models, driven by strong general capabilities, currently lead the benchmark. Notably, medical domain fine-tuning can enhance models' overall ethical competence, but further progress requires better alignment with medical ethical knowledge. PrinciplismQA offers a scalable framework to diagnose these specific ethical weaknesses, paving the way for more balanced and responsible medical AI.
Large Language Models for Outpatient Referral: Problem Definition, Benchmarking and Challenges
Mar 11, 2025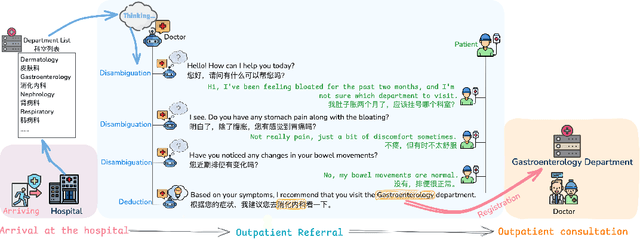
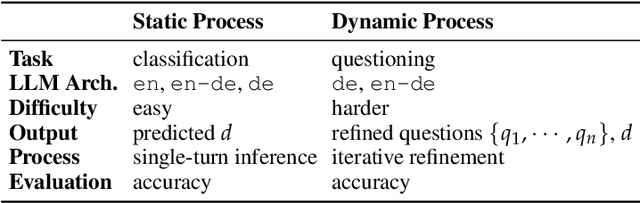
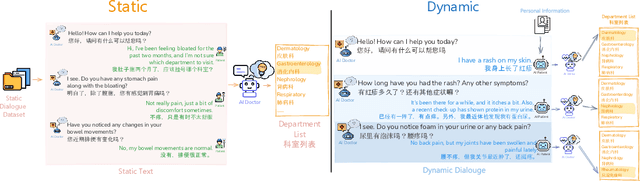
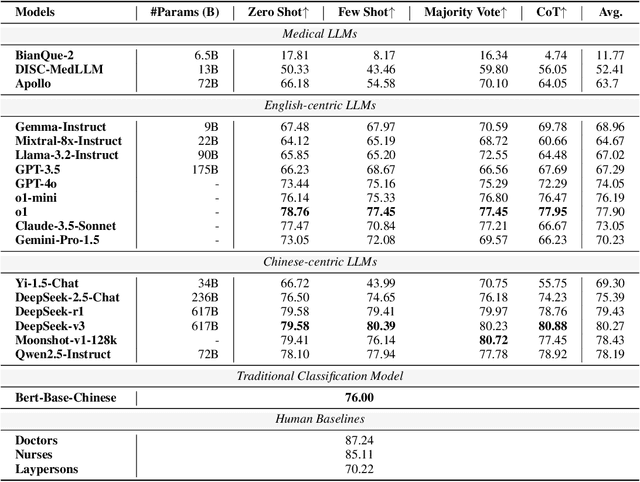
Large language models (LLMs) are increasingly applied to outpatient referral tasks across healthcare systems. However, there is a lack of standardized evaluation criteria to assess their effectiveness, particularly in dynamic, interactive scenarios. In this study, we systematically examine the capabilities and limitations of LLMs in managing tasks within Intelligent Outpatient Referral (IOR) systems and propose a comprehensive evaluation framework specifically designed for such systems. This framework comprises two core tasks: static evaluation, which focuses on evaluating the ability of predefined outpatient referrals, and dynamic evaluation, which evaluates capabilities of refining outpatient referral recommendations through iterative dialogues. Our findings suggest that LLMs offer limited advantages over BERT-like models, but show promise in asking effective questions during interactive dialogues.
HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
Jun 27, 2024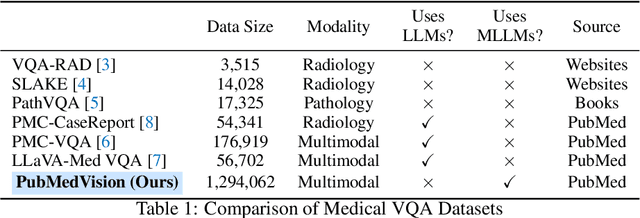
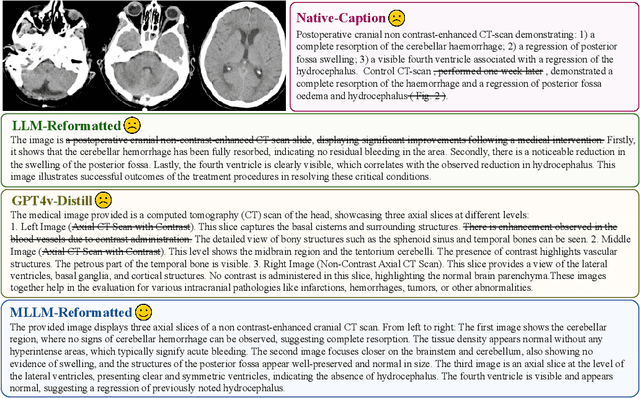
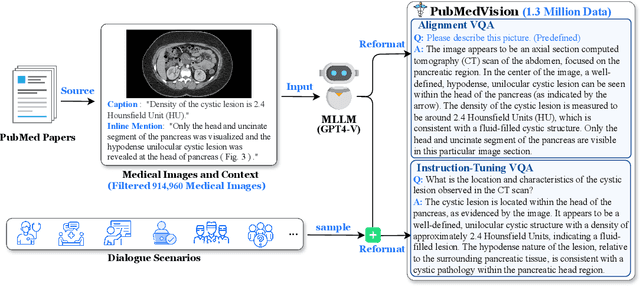
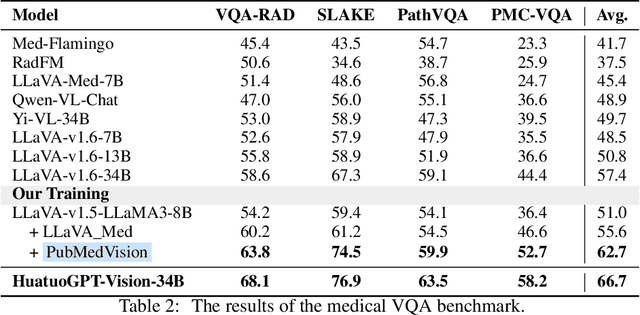
The rapid development of multimodal large language models (MLLMs), such as GPT-4V, has led to significant advancements. However, these models still face challenges in medical multimodal capabilities due to limitations in the quantity and quality of medical vision-text data, stemming from data privacy concerns and high annotation costs. While pioneering approaches utilize PubMed's large-scale, de-identified medical image-text pairs to address these limitations, they still fall short due to inherent data noise. To tackle this, we refined medical image-text pairs from PubMed and employed MLLMs (GPT-4V) in an 'unblinded' capacity to denoise and reformat the data, resulting in the creation of the PubMedVision dataset with 1.3 million medical VQA samples. Our validation demonstrates that: (1) PubMedVision can significantly enhance the medical multimodal capabilities of current MLLMs, showing significant improvement in benchmarks including the MMMU Health & Medicine track; (2) manual checks by medical experts and empirical results validate the superior data quality of our dataset compared to other data construction methods. Using PubMedVision, we train a 34B medical MLLM HuatuoGPT-Vision, which shows superior performance in medical multimodal scenarios among open-source MLLMs.
Weakly Supervised Online Action Detection for Infant General Movements
Aug 07, 2022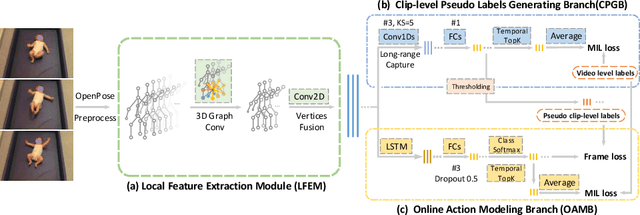
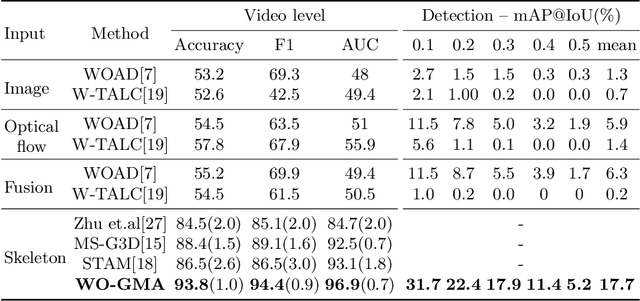
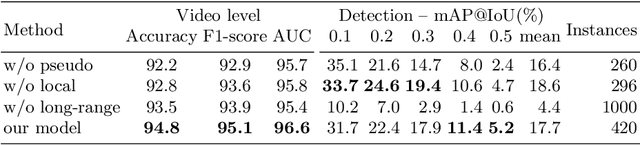
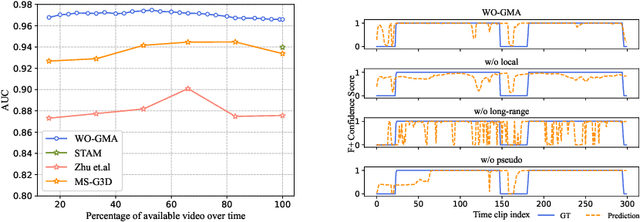
To make the earlier medical intervention of infants' cerebral palsy (CP), early diagnosis of brain damage is critical. Although general movements assessment(GMA) has shown promising results in early CP detection, it is laborious. Most existing works take videos as input to make fidgety movements(FMs) classification for the GMA automation. Those methods require a complete observation of videos and can not localize video frames containing normal FMs. Therefore we propose a novel approach named WO-GMA to perform FMs localization in the weakly supervised online setting. Infant body keypoints are first extracted as the inputs to WO-GMA. Then WO-GMA performs local spatio-temporal extraction followed by two network branches to generate pseudo clip labels and model online actions. With the clip-level pseudo labels, the action modeling branch learns to detect FMs in an online fashion. Experimental results on a dataset with 757 videos of different infants show that WO-GMA can get state-of-the-art video-level classification and cliplevel detection results. Moreover, only the first 20% duration of the video is needed to get classification results as good as fully observed, implying a significantly shortened FMs diagnosis time. Code is available at: https://github.com/scofiedluo/WO-GMA.