 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba Learns in Context: Structure-Aware Domain Generalization for Multi-Task Point Cloud Understanding
Mar 21, 2026While recent Transformer and Mamba architectures have advanced point cloud representation learning, they are typically developed for single-task or single-domain settings. Directly applying them to multi-task domain generalization (DG) leads to degraded performance. Transformers effectively model global dependencies but suffer from quadratic attention cost and lack explicit structural ordering, whereas Mamba offers linear-time recurrence yet often depends on coordinate-driven serialization, which is sensitive to viewpoint changes and missing regions, causing structural drift and unstable sequential modeling. In this paper, we propose Structure-Aware Domain Generalization (SADG), a Mamba-based In-Context Learning framework that preserves structural hierarchy across domains and tasks. We design structure-aware serialization (SAS) that generates transformation-invariant sequences using centroid-based topology and geodesic curvature continuity. We further devise hierarchical domain-aware modeling (HDM) that stabilizes cross-domain reasoning by consolidating intra-domain structure and fusing inter-domain relations. At test time, we introduce a lightweight spectral graph alignment (SGA) that shifts target features toward source prototypes in the spectral domain without updating model parameters, ensuring structure-preserving test-time feature shifting. In addition, we introduce MP3DObject, a real-scan object dataset for multi-task DG evaluation. Comprehensive experiments demonstrate that the proposed approach improves structural fidelity and consistently outperforms state-of-the-art methods across multiple tasks including reconstruction, denoising, and registration.
EditEmoTalk: Controllable Speech-Driven 3D Facial Animation with Continuous Expression Editing
Jan 15, 2026Speech-driven 3D facial animation aims to generate realistic and expressive facial motions directly from audio. While recent methods achieve high-quality lip synchronization, they often rely on discrete emotion categories, limiting continuous and fine-grained emotional control. We present EditEmoTalk, a controllable speech-driven 3D facial animation framework with continuous emotion editing. The key idea is a boundary-aware semantic embedding that learns the normal directions of inter-emotion decision boundaries, enabling a continuous expression manifold for smooth emotion manipulation. Moreover, we introduce an emotional consistency loss that enforces semantic alignment between the generated motion dynamics and the target emotion embedding through a mapping network, ensuring faithful emotional expression. Extensive experiments demonstrate that EditEmoTalk achieves superior controllability, expressiveness, and generalization while maintaining accurate lip synchronization. Code and pretrained models will be released.
Large Language Models for Outpatient Referral: Problem Definition, Benchmarking and Challenges
Mar 11, 2025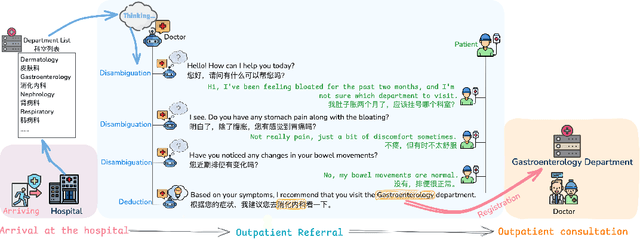
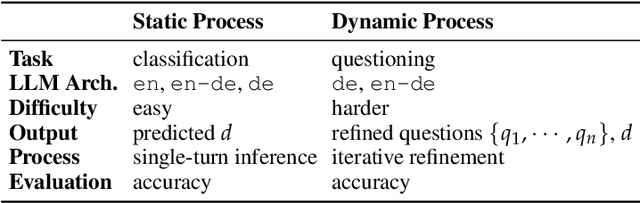
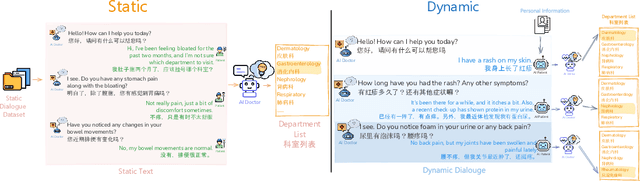
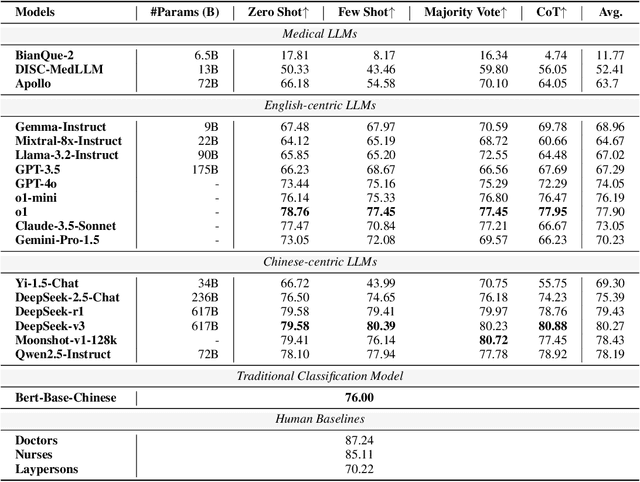
Large language models (LLMs) are increasingly applied to outpatient referral tasks across healthcare systems. However, there is a lack of standardized evaluation criteria to assess their effectiveness, particularly in dynamic, interactive scenarios. In this study, we systematically examine the capabilities and limitations of LLMs in managing tasks within Intelligent Outpatient Referral (IOR) systems and propose a comprehensive evaluation framework specifically designed for such systems. This framework comprises two core tasks: static evaluation, which focuses on evaluating the ability of predefined outpatient referrals, and dynamic evaluation, which evaluates capabilities of refining outpatient referral recommendations through iterative dialogues. Our findings suggest that LLMs offer limited advantages over BERT-like models, but show promise in asking effective questions during interactive dialogues.
PCoTTA: Continual Test-Time Adaptation for Multi-Task Point Cloud Understanding
Nov 01, 2024



In this paper, we present PCoTTA, an innovative, pioneering framework for Continual Test-Time Adaptation (CoTTA) in multi-task point cloud understanding, enhancing the model's transferability towards the continually changing target domain. We introduce a multi-task setting for PCoTTA, which is practical and realistic, handling multiple tasks within one unified model during the continual adaptation. Our PCoTTA involves three key components: automatic prototype mixture (APM), Gaussian Splatted feature shifting (GSFS), and contrastive prototype repulsion (CPR). Firstly, APM is designed to automatically mix the source prototypes with the learnable prototypes with a similarity balancing factor, avoiding catastrophic forgetting. Then, GSFS dynamically shifts the testing sample toward the source domain, mitigating error accumulation in an online manner. In addition, CPR is proposed to pull the nearest learnable prototype close to the testing feature and push it away from other prototypes, making each prototype distinguishable during the adaptation. Experimental comparisons lead to a new benchmark, demonstrating PCoTTA's superiority in boosting the model's transferability towards the continually changing target domain.
DG-PIC: Domain Generalized Point-In-Context Learning for Point Cloud Understanding
Jul 11, 2024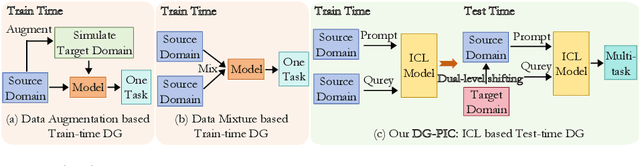
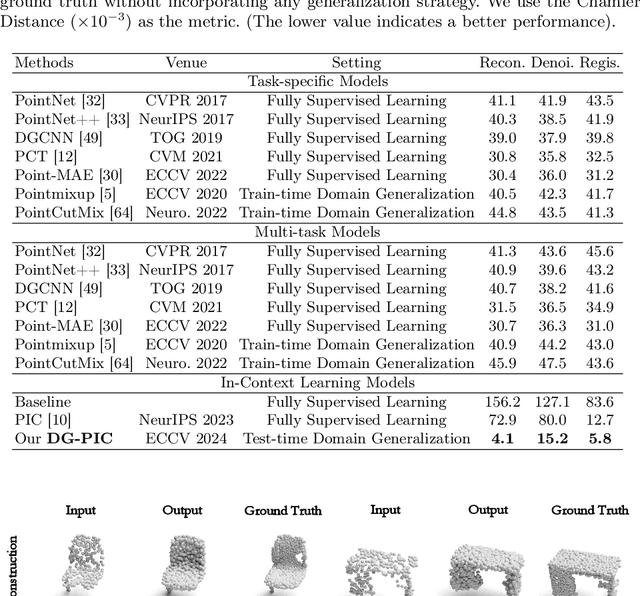
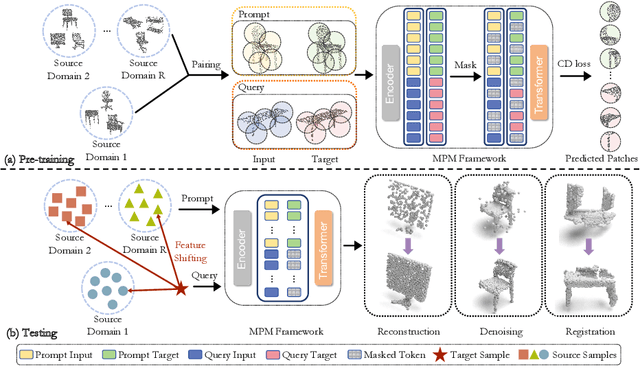

Recent point cloud understanding research suffers from performance drops on unseen data, due to the distribution shifts across different domains. While recent studies use Domain Generalization (DG) techniques to mitigate this by learning domain-invariant features, most are designed for a single task and neglect the potential of testing data. Despite In-Context Learning (ICL) showcasing multi-task learning capability, it usually relies on high-quality context-rich data and considers a single dataset, and has rarely been studied in point cloud understanding. In this paper, we introduce a novel, practical, multi-domain multi-task setting, handling multiple domains and multiple tasks within one unified model for domain generalized point cloud understanding. To this end, we propose Domain Generalized Point-In-Context Learning (DG-PIC) that boosts the generalizability across various tasks and domains at testing time. In particular, we develop dual-level source prototype estimation that considers both global-level shape contextual and local-level geometrical structures for representing source domains and a dual-level test-time feature shifting mechanism that leverages both macro-level domain semantic information and micro-level patch positional relationships to pull the target data closer to the source ones during the testing. Our DG-PIC does not require any model updates during the testing and can handle unseen domains and multiple tasks, \textit{i.e.,} point cloud reconstruction, denoising, and registration, within one unified model. We also introduce a benchmark for this new setting. Comprehensive experiments demonstrate that DG-PIC outperforms state-of-the-art techniques significantly.
Surgical Instruction Generation with Transformers
Jul 16, 2021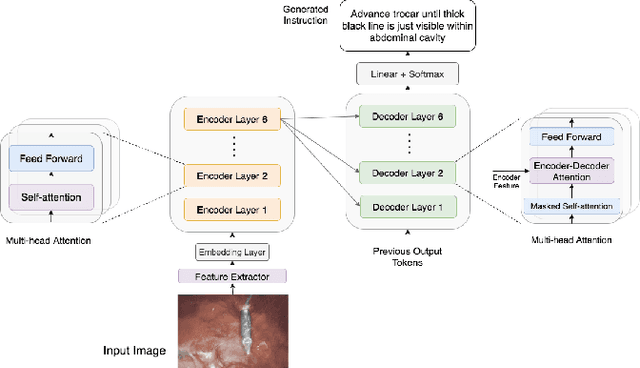
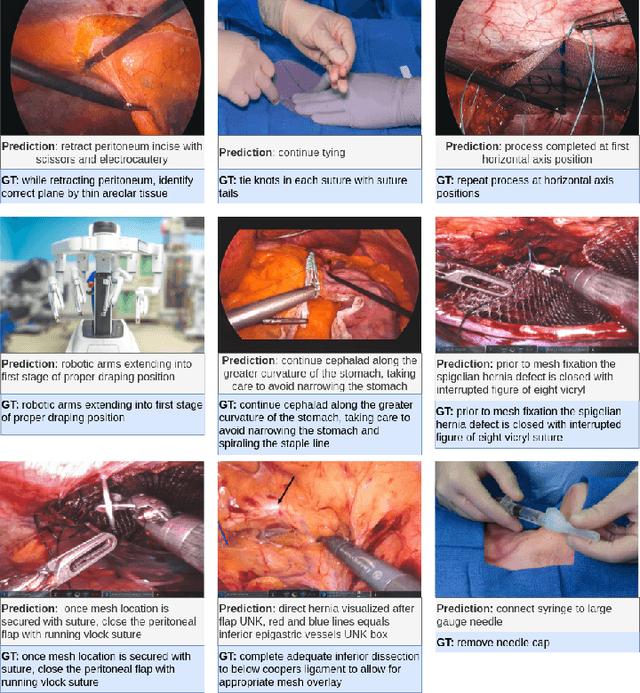
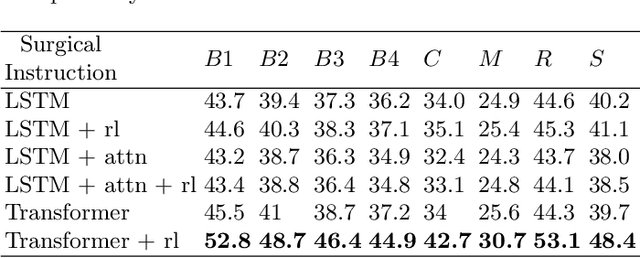
Automatic surgical instruction generation is a prerequisite towards intra-operative context-aware surgical assistance. However, generating instructions from surgical scenes is challenging, as it requires jointly understanding the surgical activity of current view and modelling relationships between visual information and textual description. Inspired by the neural machine translation and imaging captioning tasks in open domain, we introduce a transformer-backboned encoder-decoder network with self-critical reinforcement learning to generate instructions from surgical images. We evaluate the effectiveness of our method on DAISI dataset, which includes 290 procedures from various medical disciplines. Our approach outperforms the existing baseline over all caption evaluation metrics. The results demonstrate the benefits of the encoder-decoder structure backboned by transformer in handling multimodal context.
HighAir: A Hierarchical Graph Neural Network-Based Air Quality Forecasting Method
Jan 12, 2021
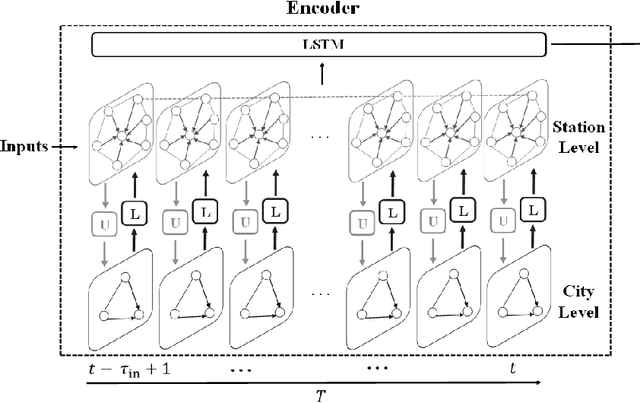
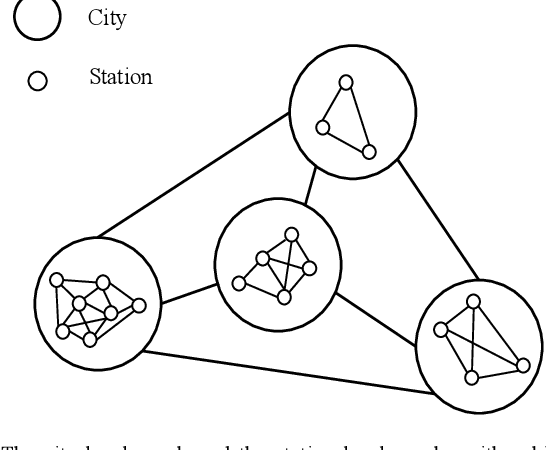
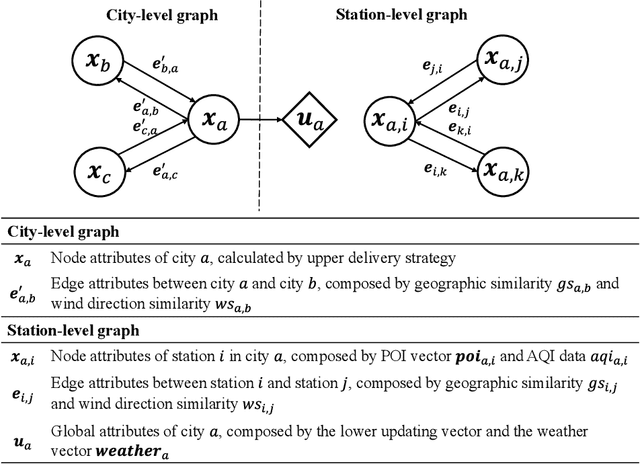
Accurately forecasting air quality is critical to protecting general public from lung and heart diseases. This is a challenging task due to the complicated interactions among distinct pollution sources and various other influencing factors. Existing air quality forecasting methods cannot effectively model the diffusion processes of air pollutants between cities and monitoring stations, which may suddenly deteriorate the air quality of a region. In this paper, we propose HighAir, i.e., a hierarchical graph neural network-based air quality forecasting method, which adopts an encoder-decoder architecture and considers complex air quality influencing factors, e.g., weather and land usage. Specifically, we construct a city-level graph and station-level graphs from a hierarchical perspective, which can consider city-level and station-level patterns, respectively. We design two strategies, i.e., upper delivery and lower updating, to implement the inter-level interactions, and introduce message passing mechanism to implement the intra-level interactions. We dynamically adjust edge weights based on wind direction to model the correlations between dynamic factors and air quality. We compare HighAir with the state-of-the-art air quality forecasting methods on the dataset of Yangtze River Delta city group, which covers 10 major cities within 61,500 km2. The experimental results show that HighAir significantly outperforms other methods.
Skeleton-bridged Point Completion: From Global Inference to Local Adjustment
Oct 14, 2020
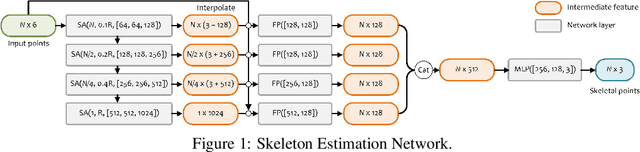

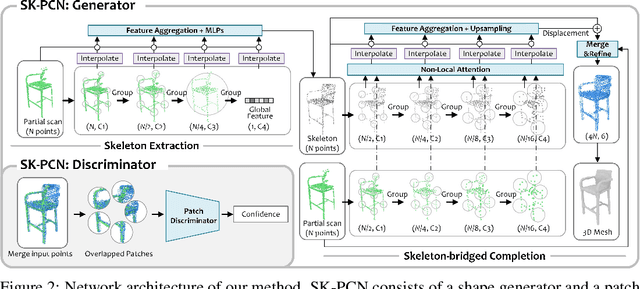
Point completion refers to complete the missing geometries of objects from partial point clouds. Existing works usually estimate the missing shape by decoding a latent feature encoded from the input points. However, real-world objects are usually with diverse topologies and surface details, which a latent feature may fail to represent to recover a clean and complete surface. To this end, we propose a skeleton-bridged point completion network (SK-PCN) for shape completion. Given a partial scan, our method first predicts its 3D skeleton to obtain the global structure, and completes the surface by learning displacements from skeletal points. We decouple the shape completion into structure estimation and surface reconstruction, which eases the learning difficulty and benefits our method to obtain on-surface details. Besides, considering the missing features during encoding input points, SK-PCN adopts a local adjustment strategy that merges the input point cloud to our predictions for surface refinement. Comparing with previous methods, our skeleton-bridged manner better supports point normal estimation to obtain the full surface mesh beyond point clouds. The qualitative and quantitative experiments on both point cloud and mesh completion show that our approach outperforms the existing methods on various object categories.
Symmetric Dilated Convolution for Surgical Gesture Recognition
Jul 14, 2020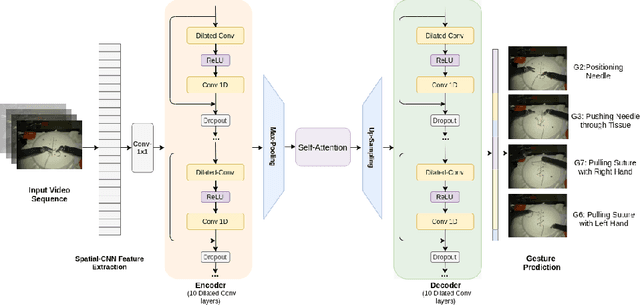
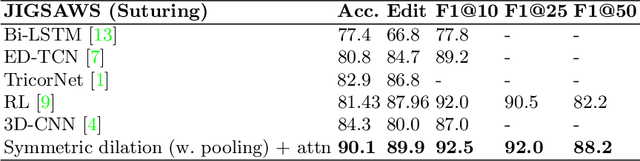
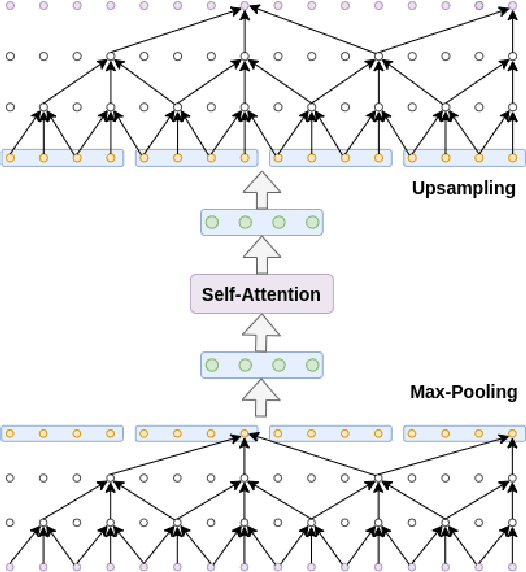
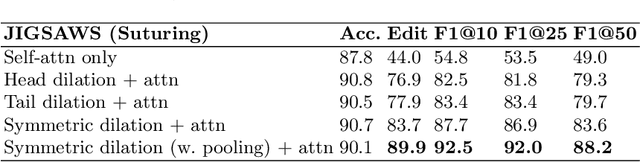
Automatic surgical gesture recognition is a prerequisite of intra-operative computer assistance and objective surgical skill assessment. Prior works either require additional sensors to collect kinematics data or have limitations on capturing temporal information from long and untrimmed surgical videos. To tackle these challenges, we propose a novel temporal convolutional architecture to automatically detect and segment surgical gestures with corresponding boundaries only using RGB videos. We devise our method with a symmetric dilation structure bridged by a self-attention module to encode and decode the long-term temporal patterns and establish the frame-to-frame relationship accordingly. We validate the effectiveness of our approach on a fundamental robotic suturing task from the JIGSAWS dataset. The experiment results demonstrate the ability of our method on capturing long-term frame dependencies, which largely outperform the state-of-the-art methods on the frame-wise accuracy up to ~6 points and the F1@50 score ~6 points.
Total3DUnderstanding: Joint Layout, Object Pose and Mesh Reconstruction for Indoor Scenes from a Single Image
Feb 27, 2020
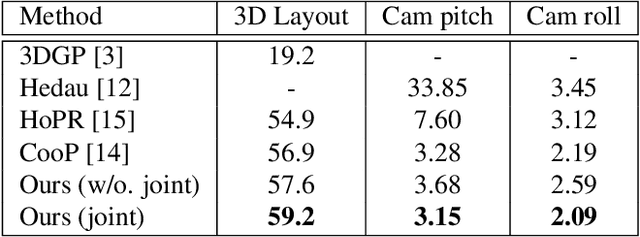
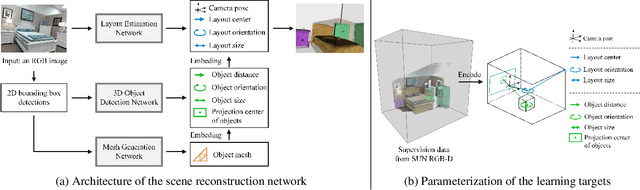

Semantic reconstruction of indoor scenes refers to both scene understanding and object reconstruction. Existing works either address one part of this problem or focus on independent objects. In this paper, we bridge the gap between understanding and reconstruction, and propose an end-to-end solution to jointly reconstruct room layout, object bounding boxes and meshes from a single image. Instead of separately resolving scene understanding and object reconstruction, our method builds upon a holistic scene context and proposes a coarse-to-fine hierarchy with three components: 1. room layout with camera pose; 2. 3D object bounding boxes; 3. object meshes. We argue that understanding the context of each component can assist the task of parsing the others, which enables joint understanding and reconstruction. The experiments on the SUN RGB-D and Pix3D datasets demonstrate that our method consistently outperforms existing methods in indoor layout estimation, 3D object detection and mesh reconstruction.