 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMG: Progressive Motion Generation via Sparse Anchor Postures Curriculum Learning
Apr 23, 2025In computer animation, game design, and human-computer interaction, synthesizing human motion that aligns with user intent remains a significant challenge. Existing methods have notable limitations: textual approaches offer high-level semantic guidance but struggle to describe complex actions accurately; trajectory-based techniques provide intuitive global motion direction yet often fall short in generating precise or customized character movements; and anchor poses-guided methods are typically confined to synthesize only simple motion patterns. To generate more controllable and precise human motions, we propose \textbf{ProMoGen (Progressive Motion Generation)}, a novel framework that integrates trajectory guidance with sparse anchor motion control. Global trajectories ensure consistency in spatial direction and displacement, while sparse anchor motions only deliver precise action guidance without displacement. This decoupling enables independent refinement of both aspects, resulting in a more controllable, high-fidelity, and sophisticated motion synthesis. ProMoGen supports both dual and single control paradigms within a unified training process. Moreover, we recognize that direct learning from sparse motions is inherently unstable, we introduce \textbf{SAP-CL (Sparse Anchor Posture Curriculum Learning)}, a curriculum learning strategy that progressively adjusts the number of anchors used for guidance, thereby enabling more precise and stable convergence. Extensive experiments demonstrate that ProMoGen excels in synthesizing vivid and diverse motions guided by predefined trajectory and arbitrary anchor frames. Our approach seamlessly integrates personalized motion with structured guidance, significantly outperforming state-of-the-art methods across multiple control scenarios.
Exploring the latent space of diffusion models directly through singular value decomposition
Feb 04, 2025Despite the groundbreaking success of diffusion models in generating high-fidelity images, their latent space remains relatively under-explored, even though it holds significant promise for enabling versatile and interpretable image editing capabilities. The complicated denoising trajectory and high dimensionality of the latent space make it extremely challenging to interpret. Existing methods mainly explore the feature space of U-Net in Diffusion Models (DMs) instead of the latent space itself. In contrast, we directly investigate the latent space via Singular Value Decomposition (SVD) and discover three useful properties that can be used to control generation results without the requirements of data collection and maintain identity fidelity generated images. Based on these properties, we propose a novel image editing framework that is capable of learning arbitrary attributes from one pair of latent codes destined by text prompts in Stable Diffusion Models. To validate our approach, extensive experiments are conducted to demonstrate its effectiveness and flexibility in image editing. We will release our codes soon to foster further research and applications in this area.
Preserving Empirical Probabilities in BERT for Small-sample Clinical Entity Recognition
Sep 05, 2024



Named Entity Recognition (NER) encounters the challenge of unbalanced labels, where certain entity types are overrepresented while others are underrepresented in real-world datasets. This imbalance can lead to biased models that perform poorly on minority entity classes, impeding accurate and equitable entity recognition. This paper explores the effects of unbalanced entity labels of the BERT-based pre-trained model. We analyze the different mechanisms of loss calculation and loss propagation for the task of token classification on randomized datasets. Then we propose ways to improve the token classification for the highly imbalanced task of clinical entity recognition.
MaSkel: A Model for Human Whole-body X-rays Generation from Human Masking Images
Apr 13, 2024The human whole-body X-rays could offer a valuable reference for various applications, including medical diagnostics, digital animation modeling, and ergonomic design. The traditional method of obtaining X-ray information requires the use of CT (Computed Tomography) scan machines, which emit potentially harmful radiation. Thus it faces a significant limitation for realistic applications because it lacks adaptability and safety. In our work, We proposed a new method to directly generate the 2D human whole-body X-rays from the human masking images. The predicted images will be similar to the real ones with the same image style and anatomic structure. We employed a data-driven strategy. By leveraging advanced generative techniques, our model MaSkel(Masking image to Skeleton X-rays) could generate a high-quality X-ray image from a human masking image without the need for invasive and harmful radiation exposure, which not only provides a new path to generate highly anatomic and customized data but also reduces health risks. To our knowledge, our model MaSkel is the first work for predicting whole-body X-rays. In this paper, we did two parts of the work. The first one is to solve the data limitation problem, the diffusion-based techniques are utilized to make a data augmentation, which provides two synthetic datasets for preliminary pretraining. Then we designed a two-stage training strategy to train MaSkel. At last, we make qualitative and quantitative evaluations of the generated X-rays. In addition, we invite some professional doctors to assess our predicted data. These evaluations demonstrate the MaSkel's superior ability to generate anatomic X-rays from human masking images. The related code and links of the dataset are available at https://github.com/2022yingjie/MaSkel.
Existence Is Chaos: Enhancing 3D Human Motion Prediction with Uncertainty Consideration
Mar 21, 2024
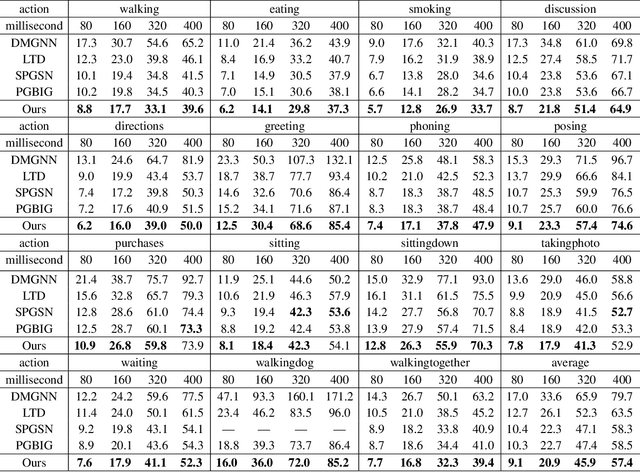


Human motion prediction is consisting in forecasting future body poses from historically observed sequences. It is a longstanding challenge due to motion's complex dynamics and uncertainty. Existing methods focus on building up complicated neural networks to model the motion dynamics. The predicted results are required to be strictly similar to the training samples with L2 loss in current training pipeline. However, little attention has been paid to the uncertainty property which is crucial to the prediction task. We argue that the recorded motion in training data could be an observation of possible future, rather than a predetermined result. In addition, existing works calculate the predicted error on each future frame equally during training, while recent work indicated that different frames could play different roles. In this work, a novel computationally efficient encoder-decoder model with uncertainty consideration is proposed, which could learn proper characteristics for future frames by a dynamic function. Experimental results on benchmark datasets demonstrate that our uncertainty consideration approach has obvious advantages both in quantity and quality. Moreover, the proposed method could produce motion sequences with much better quality that avoids the intractable shaking artefacts. We believe our work could provide a novel perspective to consider the uncertainty quality for the general motion prediction task and encourage the studies in this field. The code will be available in https://github.com/Motionpre/Adaptive-Salient-Loss-SAGGB.
CLARA: Multilingual Contrastive Learning for Audio Representation Acquisition
Nov 01, 2023Multilingual speech processing requires understanding emotions, a task made difficult by limited labelled data. CLARA, minimizes reliance on labelled data, enhancing generalization across languages. It excels at fostering shared representations, aiding cross-lingual transfer of speech and emotions, even with little data. Our approach adeptly captures emotional nuances in speech, overcoming subjective assessment issues. Using a large multilingual audio corpus and self-supervised learning, CLARA develops speech representations enriched with emotions, advancing emotion-aware multilingual speech processing. Our method expands the data range using data augmentation, textual embedding for visual understanding, and transfers knowledge from high- to low-resource languages. CLARA demonstrates excellent performance in emotion recognition, language comprehension, and audio benchmarks, excelling in zero-shot and few-shot learning. It adapts to low-resource languages, marking progress in multilingual speech representation learning.
EMNS /Imz/ Corpus: An emotive single-speaker dataset for narrative storytelling in games, television and graphic novels
May 25, 2023The increasing adoption of text-to-speech technologies has led to a growing demand for natural and emotive voices that adapt to a conversation's context and emotional tone. The Emotive Narrative Storytelling (EMNS) corpus is a unique speech dataset created to enhance conversations' expressiveness and emotive quality in interactive narrative-driven systems. The corpus consists of a 2.3-hour recording featuring a female speaker delivering labelled utterances. It encompasses eight acted emotional states, evenly distributed with a variance of 0.68%, along with expressiveness levels and natural language descriptions with word emphasis labels. The evaluation of audio samples from different datasets revealed that the EMNS corpus achieved the highest average scores in accurately conveying emotions and demonstrating expressiveness. It outperformed other datasets in conveying shared emotions and achieved comparable levels of genuineness. A classification task confirmed the accurate representation of intended emotions in the corpus, with participants recognising the recordings as genuine and expressive. Additionally, the availability of the dataset collection tool under the Apache 2.0 License simplifies remote speech data collection for researchers.
Shifting Perspective to See Difference: A Novel Multi-View Method for Skeleton based Action Recognition
Sep 07, 2022
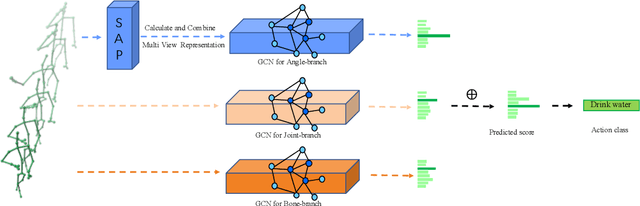

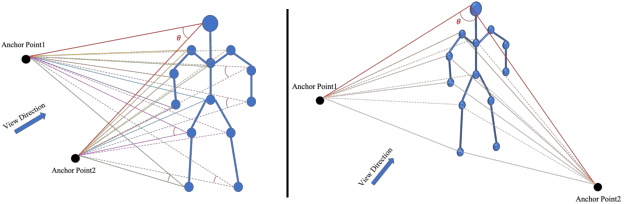
Skeleton-based human action recognition is a longstanding challenge due to its complex dynamics. Some fine-grain details of the dynamics play a vital role in classification. The existing work largely focuses on designing incremental neural networks with more complicated adjacent matrices to capture the details of joints relationships. However, they still have difficulties distinguishing actions that have broadly similar motion patterns but belong to different categories. Interestingly, we found that the subtle differences in motion patterns can be significantly amplified and become easy for audience to distinct through specified view directions, where this property haven't been fully explored before. Drastically different from previous work, we boost the performance by proposing a conceptually simple yet effective Multi-view strategy that recognizes actions from a collection of dynamic view features. Specifically, we design a novel Skeleton-Anchor Proposal (SAP) module which contains a Multi-head structure to learn a set of views. For feature learning of different views, we introduce a novel Angle Representation to transform the actions under different views and feed the transformations into the baseline model. Our module can work seamlessly with the existing action classification model. Incorporated with baseline models, our SAP module exhibits clear performance gains on many challenging benchmarks. Moreover, comprehensive experiments show that our model consistently beats down the state-of-the-art and remains effective and robust especially when dealing with corrupted data. Related code will be available on https://github.com/ideal-idea/SAP .
Symmetric Dilated Convolution for Surgical Gesture Recognition
Jul 14, 2020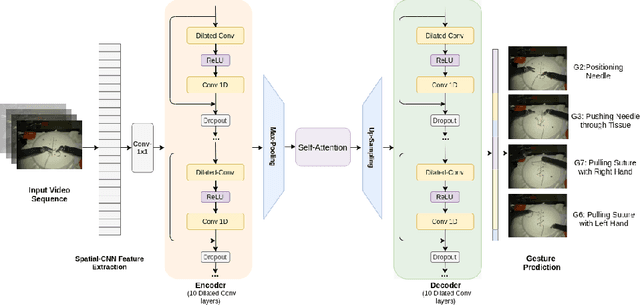
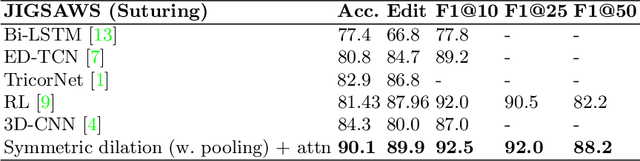
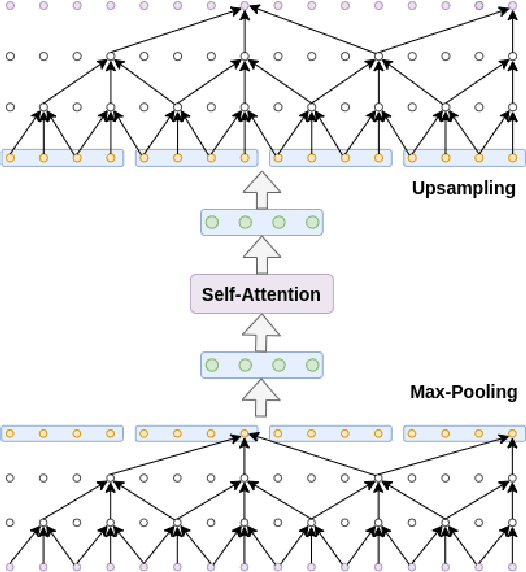
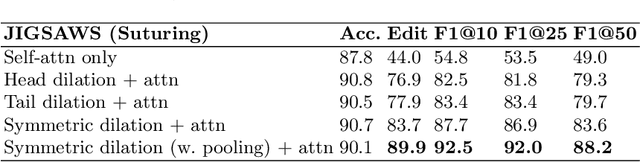
Automatic surgical gesture recognition is a prerequisite of intra-operative computer assistance and objective surgical skill assessment. Prior works either require additional sensors to collect kinematics data or have limitations on capturing temporal information from long and untrimmed surgical videos. To tackle these challenges, we propose a novel temporal convolutional architecture to automatically detect and segment surgical gestures with corresponding boundaries only using RGB videos. We devise our method with a symmetric dilation structure bridged by a self-attention module to encode and decode the long-term temporal patterns and establish the frame-to-frame relationship accordingly. We validate the effectiveness of our approach on a fundamental robotic suturing task from the JIGSAWS dataset. The experiment results demonstrate the ability of our method on capturing long-term frame dependencies, which largely outperform the state-of-the-art methods on the frame-wise accuracy up to ~6 points and the F1@50 score ~6 points.