 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Semantic Reasoning for Training Free Video Anomaly Detection
Mar 10, 2026Training-free video anomaly detection (VAD) has recently emerged as a scalable alternative to supervised approaches, yet existing methods largely rely on static prompting and geometry-agnostic feature fusion. As a result, anomaly inference is often reduced to shallow similarity matching over Euclidean embeddings, leading to unstable predictions and limited interpretability, especially in complex or hierarchically structured scenes. We introduce MM-VAD, a geometry-aware semantic reasoning framework for training free VAD that reframes anomaly detection as adaptive test-time inference rather than fixed feature comparison. Our approach projects caption-derived scene representations into hyperbolic space to better preserve hierarchical structure and performs anomaly assessment through an adaptive question answering process over a frozen large language model. A lightweight, learnable prompt is optimised at test time using an unsupervised confidence-sparsity objective, enabling context-specific calibration without updating any backbone parameters. To further ground semantic predictions in visual evidence, we incorporate a covariance-aware Mahalanobis refinement that stabilises cross-modal alignment. Across four benchmarks, MM-VAD consistently improves over prior training-free methods, achieving 90.03% AUC on XD-Violence and 83.24%, 96.95%, and 98.81% on UCF-Crime, ShanghaiTech, and UCSD Ped2, respectively. Our results demonstrate that geometry-aware representation and adaptive semantic calibration provide a principled and effective alternative to static Euclidean matching in training-free VAD.
Enhancing Psychologists' Understanding through Explainable Deep Learning Framework for ADHD Diagnosis
Jan 28, 2026Attention Deficit Hyperactivity Disorder (ADHD) is a neurodevelopmental disorder that is challenging to diagnose and requires advanced approaches for reliable and transparent identification and classification. It is characterized by a pattern of inattention, hyperactivity and impulsivity that is more severe and more frequent than in individuals with a comparable level of development. In this paper, an explainable framework based on a fine-tuned hybrid Deep Neural Network (DNN) and Recurrent Neural Network (RNN) called HyExDNN-RNN model is proposed for ADHD detection, multi-class categorization, and decision interpretation. This framework not only detects ADHD, but also provides interpretable insights into the diagnostic process so that psychologists can better understand and trust the results of the diagnosis. We use the Pearson correlation coefficient for optimal feature selection and machine and deep learning models for experimental analysis and comparison. We use a standardized technique for feature reduction, model selection and interpretation to accurately determine the diagnosis rate and ensure the interpretability of the proposed framework. Our framework provided excellent results on binary classification, with HyExDNN-RNN achieving an F1 score of 99% and 94.2% on multi-class categorization. XAI approaches, in particular SHapley Additive exPlanations (SHAP) and Permutation Feature Importance (PFI), provided important insights into the importance of features and the decision logic of models. By combining AI with human expertise, we aim to bridge the gap between advanced computational techniques and practical psychological applications. These results demonstrate the potential of our framework to assist in ADHD diagnosis and interpretation.
Test-Time Adaptation for Anomaly Segmentation via Topology-Aware Optimal Transport Chaining
Jan 28, 2026Deep topological data analysis (TDA) offers a principled framework for capturing structural invariants such as connectivity and cycles that persist across scales, making it a natural fit for anomaly segmentation (AS). Unlike thresholdbased binarisation, which produces brittle masks under distribution shift, TDA allows anomalies to be characterised as disruptions to global structure rather than local fluctuations. We introduce TopoOT, a topology-aware optimal transport (OT) framework that integrates multi-filtration persistence diagrams (PDs) with test-time adaptation (TTA). Our key innovation is Optimal Transport Chaining, which sequentially aligns PDs across thresholds and filtrations, yielding geodesic stability scores that identify features consistently preserved across scales. These stabilityaware pseudo-labels supervise a lightweight head trained online with OT-consistency and contrastive objectives, ensuring robust adaptation under domain shift. Across standard 2D and 3D anomaly detection benchmarks, TopoOT achieves state-of-the-art performance, outperforming the most competitive methods by up to +24.1% mean F1 on 2D datasets and +10.2% on 3D AS benchmarks.
Uni-Hema: Unified Model for Digital Hematopathology
Nov 19, 2025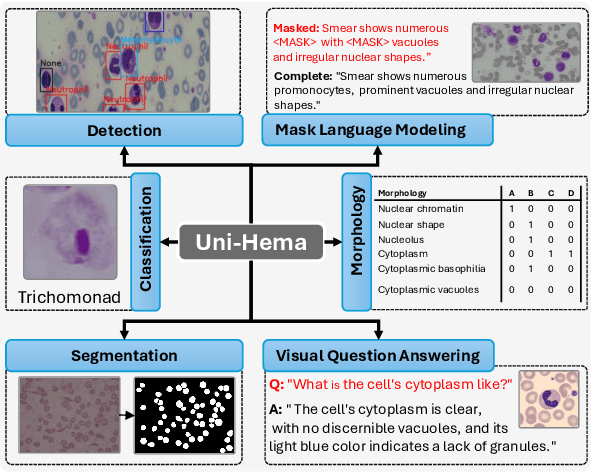
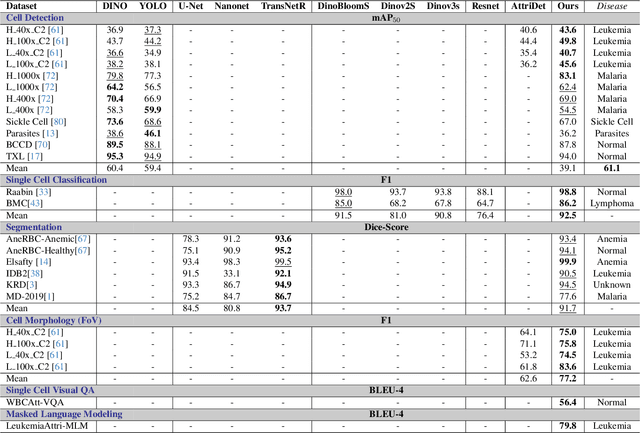
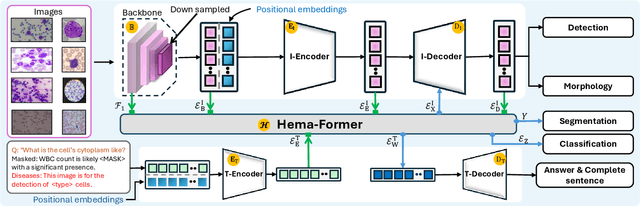
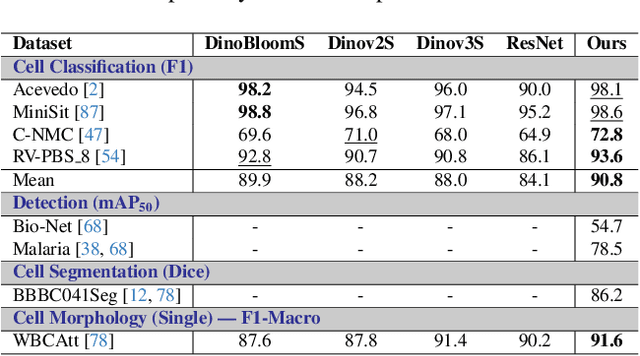
Digital hematopathology requires cell-level analysis across diverse disease categories, including malignant disorders (e.g., leukemia), infectious conditions (e.g., malaria), and non-malignant red blood cell disorders (e.g., sickle cell disease). Whether single-task, vision-language, WSI-optimized, or single-cell hematology models, these approaches share a key limitation, they cannot provide unified, multi-task, multi-modal reasoning across the complexities of digital hematopathology. To overcome these limitations, we propose Uni-Hema, a multi-task, unified model for digital hematopathology integrating detection, classification, segmentation, morphology prediction, and reasoning across multiple diseases. Uni-Hema leverages 46 publicly available datasets, encompassing over 700K images and 21K question-answer pairs, and is built upon Hema-Former, a multimodal module that bridges visual and textual representations at the hierarchy level for the different tasks (detection, classification, segmentation, morphology, mask language modeling and visual question answer) at different granularity. Extensive experiments demonstrate that Uni-Hema achieves comparable or superior performance to train on a single-task and single dataset models, across diverse hematological tasks, while providing interpretable, morphologically relevant insights at the single-cell level. Our framework establishes a new standard for multi-task and multi-modal digital hematopathology. The code will be made publicly available.
Explainable AI for Curie Temperature Prediction in Magnetic Materials
Aug 09, 2025We explore machine learning techniques for predicting Curie temperatures of magnetic materials using the NEMAD database. By augmenting the dataset with composition-based and domain-aware descriptors, we evaluate the performance of several machine learning models. We find that the Extra Trees Regressor delivers the best performance reaching an R^2 score of up to 0.85 $\pm$ 0.01 (cross-validated) for a balanced dataset. We employ the k-means clustering algorithm to gain insights into the performance of chemically distinct material groups. Furthermore, we perform the SHAP analysis to identify key physicochemical drivers of Curie behavior, such as average atomic number and magnetic moment. By employing explainable AI techniques, this analysis offers insights into the model's predictive behavior, thereby advancing scientific interpretability.
Advances in LLMs with Focus on Reasoning, Adaptability, Efficiency and Ethics
Jun 14, 2025



This survey paper outlines the key developments in the field of Large Language Models (LLMs), such as enhancing their reasoning skills, adaptability to various tasks, increased computational efficiency, and ability to make ethical decisions. The techniques that have been most effective in bridging the gap between human and machine communications include the Chain-of-Thought prompting, Instruction Tuning, and Reinforcement Learning from Human Feedback. The improvements in multimodal learning and few-shot or zero-shot techniques have further empowered LLMs to handle complex jobs with minor input. They also manage to do more with less by applying scaling and optimization tricks for computing power conservation. This survey also offers a broader perspective on recent advancements in LLMs going beyond isolated aspects such as model architecture or ethical concerns. It categorizes emerging methods that enhance LLM reasoning, efficiency, and ethical alignment. It also identifies underexplored areas such as interpretability, cross-modal integration and sustainability. With recent progress, challenges like huge computational costs, biases, and ethical risks remain constant. Addressing these requires bias mitigation, transparent decision-making, and clear ethical guidelines. Future research will focus on enhancing models ability to handle multiple input, thereby making them more intelligent, safe, and reliable.
Leveraging Sparse Annotations for Leukemia Diagnosis on the Large Leukemia Dataset
Apr 03, 2025Leukemia is 10th most frequently diagnosed cancer and one of the leading causes of cancer related deaths worldwide. Realistic analysis of Leukemia requires White Blook Cells (WBC) localization, classification, and morphological assessment. Despite deep learning advances in medical imaging, leukemia analysis lacks a large, diverse multi-task dataset, while existing small datasets lack domain diversity, limiting real world applicability. To overcome dataset challenges, we present a large scale WBC dataset named Large Leukemia Dataset (LLD) and novel methods for detecting WBC with their attributes. Our contribution here is threefold. First, we present a large-scale Leukemia dataset collected through Peripheral Blood Films (PBF) from several patients, through multiple microscopes, multi cameras, and multi magnification. To enhance diagnosis explainability and medical expert acceptance, each leukemia cell is annotated at 100x with 7 morphological attributes, ranging from Cell Size to Nuclear Shape. Secondly, we propose a multi task model that not only detects WBCs but also predicts their attributes, providing an interpretable and clinically meaningful solution. Third, we propose a method for WBC detection with attribute analysis using sparse annotations. This approach reduces the annotation burden on hematologists, requiring them to mark only a small area within the field of view. Our method enables the model to leverage the entire field of view rather than just the annotated regions, enhancing learning efficiency and diagnostic accuracy. From diagnosis explainability to overcoming domain shift challenges, presented datasets could be used for many challenging aspects of microscopic image analysis. The datasets, code, and demo are available at: https://im.itu.edu.pk/sparse-leukemiaattri/
Deep neural network-based detection of counterfeit products from smartphone images
Oct 08, 2024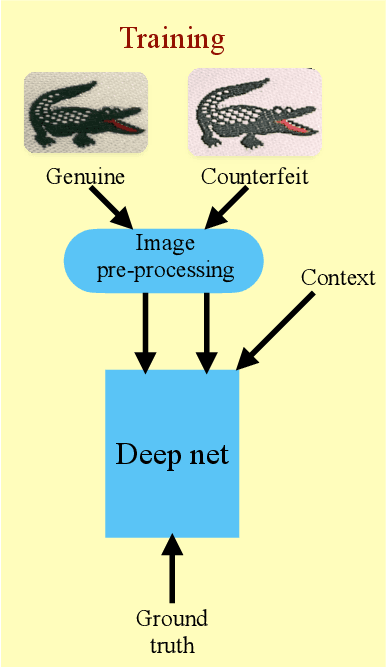
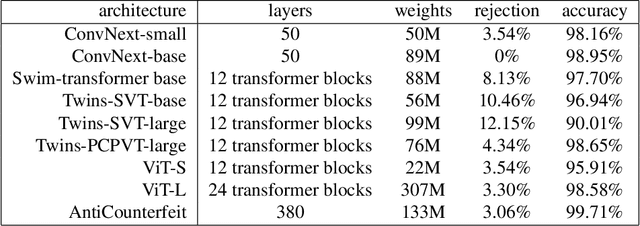

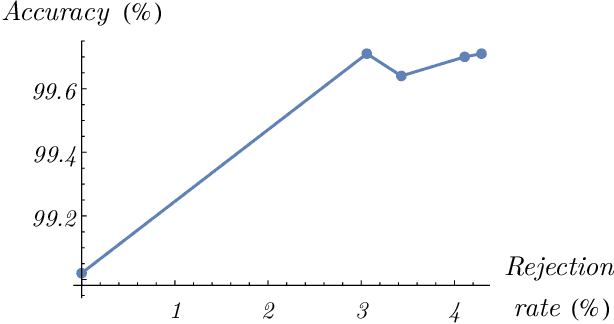
Counterfeit products such as drugs and vaccines as well as luxury items such as high-fashion handbags, watches, jewelry, garments, and cosmetics, represent significant direct losses of revenue to legitimate manufacturers and vendors, as well as indirect costs to societies at large. We present the world's first purely computer-vision-based system to combat such counterfeiting-one that does not require special security tags or other alterations to the products or modifications to supply chain tracking. Our deep neural network system shows high accuracy on branded garments from our first manufacturer tested (99.71% after 3.06% rejections) using images captured under natural, weakly controlled conditions, such as in retail stores, customs checkpoints, warehouses, and outdoors. Our system, suitably transfer trained on a small number of fake and genuine articles, should find application in additional product categories as well, for example fashion accessories, perfume boxes, medicines, and more.
Preserving Empirical Probabilities in BERT for Small-sample Clinical Entity Recognition
Sep 05, 2024



Named Entity Recognition (NER) encounters the challenge of unbalanced labels, where certain entity types are overrepresented while others are underrepresented in real-world datasets. This imbalance can lead to biased models that perform poorly on minority entity classes, impeding accurate and equitable entity recognition. This paper explores the effects of unbalanced entity labels of the BERT-based pre-trained model. We analyze the different mechanisms of loss calculation and loss propagation for the task of token classification on randomized datasets. Then we propose ways to improve the token classification for the highly imbalanced task of clinical entity recognition.
Joint Stream: Malignant Region Learning for Breast Cancer Diagnosis
Jun 26, 2024



Early diagnosis of breast cancer (BC) significantly contributes to reducing the mortality rate worldwide. The detection of different factors and biomarkers such as Estrogen receptor (ER), Progesterone receptor (PR), Human epidermal growth factor receptor 2 (HER2) gene, Histological grade (HG), Auxiliary lymph node (ALN) status, and Molecular subtype (MS) can play a significant role in improved BC diagnosis. However, the existing methods predict only a single factor which makes them less suitable to use in diagnosis and designing a strategy for treatment. In this paper, we propose to classify the six essential indicating factors (ER, PR, HER2, ALN, HG, MS) for early BC diagnosis using H\&E stained WSI's. To precisely capture local neighboring relationships, we use spatial and frequency domain information from the large patch size of WSI's malignant regions. Furthermore, to cater the variable number of regions of interest sizes and give due attention to each region, we propose a malignant region learning attention network. Our experimental results demonstrate that combining spatial and frequency information using the malignant region learning module significantly improves multi-factor and single-factor classification performance on publicly available datasets.