 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCytoplasmic Strings Analysis in Human Embryo Time-Lapse Videos using Deep Learning Framework
Dec 10, 2025Infertility is a major global health issue, and while in-vitro fertilization has improved treatment outcomes, embryo selection remains a critical bottleneck. Time-lapse imaging enables continuous, non-invasive monitoring of embryo development, yet most automated assessment methods rely solely on conventional morphokinetic features and overlook emerging biomarkers. Cytoplasmic Strings, thin filamentous structures connecting the inner cell mass and trophectoderm in expanded blastocysts, have been associated with faster blastocyst formation, higher blastocyst grades, and improved viability. However, CS assessment currently depends on manual visual inspection, which is labor-intensive, subjective, and severely affected by detection and subtle visual appearance. In this work, we present, to the best of our knowledge, the first computational framework for CS analysis in human IVF embryos. We first design a human-in-the-loop annotation pipeline to curate a biologically validated CS dataset from TLI videos, comprising 13,568 frames with highly sparse CS-positive instances. Building on this dataset, we propose a two-stage deep learning framework that (i) classifies CS presence at the frame level and (ii) localizes CS regions in positive cases. To address severe imbalance and feature uncertainty, we introduce the Novel Uncertainty-aware Contractive Embedding (NUCE) loss, which couples confidence-aware reweighting with an embedding contraction term to form compact, well-separated class clusters. NUCE consistently improves F1-score across five transformer backbones, while RF-DETR-based localization achieves state-of-the-art (SOTA) detection performance for thin, low-contrast CS structures. The source code will be made publicly available at: https://github.com/HamadYA/CS_Detection.
Multi-Resolution Pathology-Language Pre-training Model with Text-Guided Visual Representation
Apr 26, 2025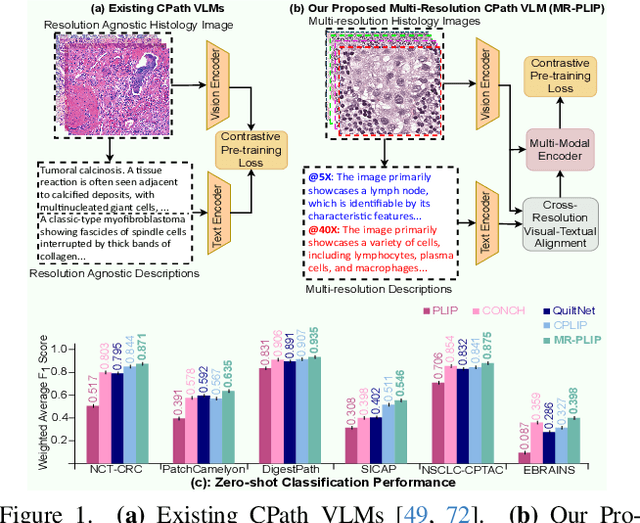
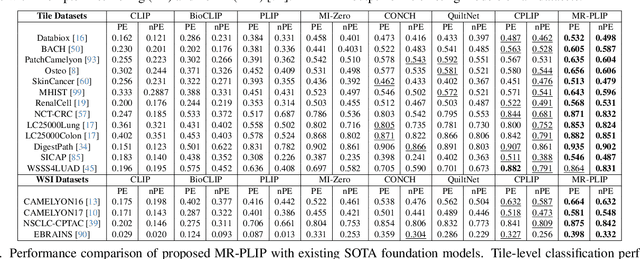
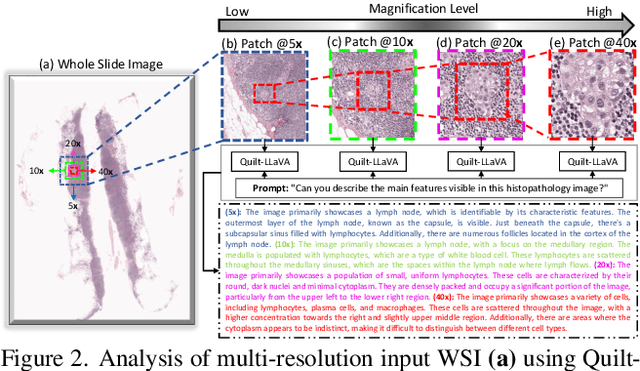
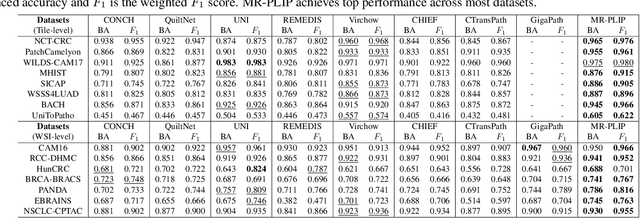
In Computational Pathology (CPath), the introduction of Vision-Language Models (VLMs) has opened new avenues for research, focusing primarily on aligning image-text pairs at a single magnification level. However, this approach might not be sufficient for tasks like cancer subtype classification, tissue phenotyping, and survival analysis due to the limited level of detail that a single-resolution image can provide. Addressing this, we propose a novel multi-resolution paradigm leveraging Whole Slide Images (WSIs) to extract histology patches at multiple resolutions and generate corresponding textual descriptions through advanced CPath VLM. We introduce visual-textual alignment at multiple resolutions as well as cross-resolution alignment to establish more effective text-guided visual representations. Cross-resolution alignment using a multimodal encoder enhances the model's ability to capture context from multiple resolutions in histology images. Our model aims to capture a broader range of information, supported by novel loss functions, enriches feature representation, improves discriminative ability, and enhances generalization across different resolutions. Pre-trained on a comprehensive TCGA dataset with 34 million image-language pairs at various resolutions, our fine-tuned model outperforms state-of-the-art (SOTA) counterparts across multiple datasets and tasks, demonstrating its effectiveness in CPath. The code is available on GitHub at: https://github.com/BasitAlawode/MR-PLIP
A Survey of the Self Supervised Learning Mechanisms for Vision Transformers
Aug 30, 2024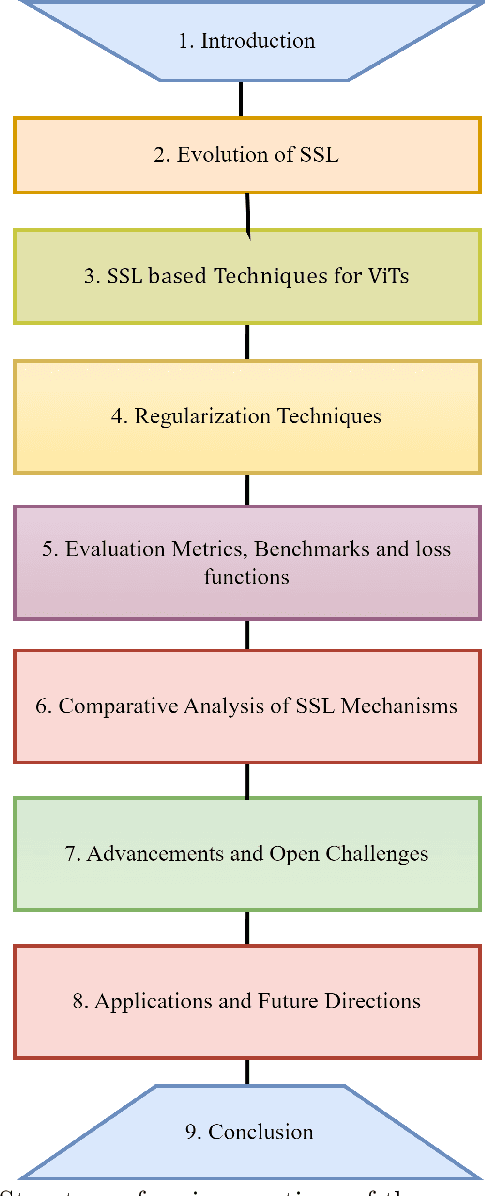
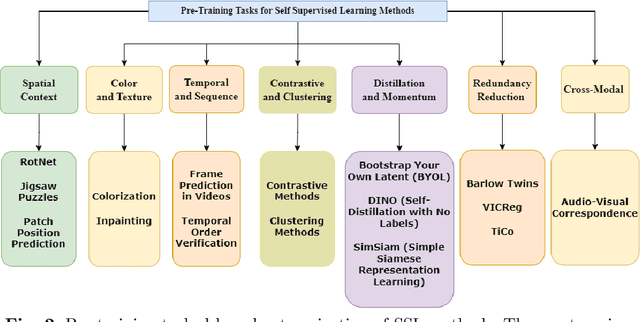
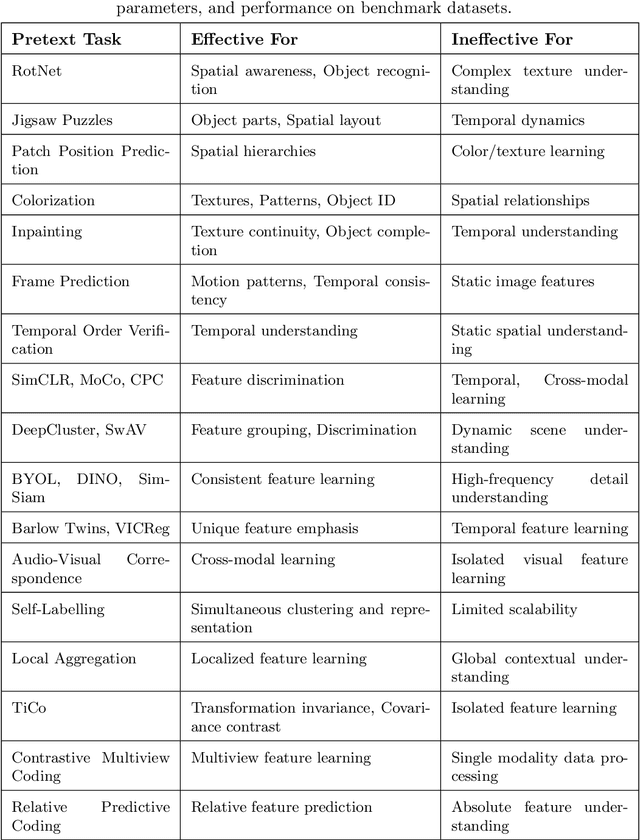
Deep supervised learning models require high volume of labeled data to attain sufficiently good results. Although, the practice of gathering and annotating such big data is costly and laborious. Recently, the application of self supervised learning (SSL) in vision tasks has gained significant attention. The intuition behind SSL is to exploit the synchronous relationships within the data as a form of self-supervision, which can be versatile. In the current big data era, most of the data is unlabeled, and the success of SSL thus relies in finding ways to improve this vast amount of unlabeled data available. Thus its better for deep learning algorithms to reduce reliance on human supervision and instead focus on self-supervision based on the inherent relationships within the data. With the advent of ViTs, which have achieved remarkable results in computer vision, it is crucial to explore and understand the various SSL mechanisms employed for training these models specifically in scenarios where there is less label data available. In this survey we thus develop a comprehensive taxonomy of systematically classifying the SSL techniques based upon their representations and pre-training tasks being applied. Additionally, we discuss the motivations behind SSL, review popular pre-training tasks, and highlight the challenges and advancements in this field. Furthermore, we present a comparative analysis of different SSL methods, evaluate their strengths and limitations, and identify potential avenues for future research.
A survey of the Vision Transformers and its CNN-Transformer based Variants
May 25, 2023Vision transformers have recently become popular as a possible alternative to convolutional neural networks (CNNs) for a variety of computer vision applications. These vision transformers due to their ability to focus on global relationships in images have large capacity, but may result in poor generalization as compared to CNNs. Very recently, the hybridization of convolution and self-attention mechanisms in vision transformers is gaining popularity due to their ability of exploiting both local and global image representations. These CNN-Transformer architectures also known as hybrid vision transformers have shown remarkable results for vision applications. Recently, due to the rapidly growing number of these hybrid vision transformers, there is a need for a taxonomy and explanation of these architectures. This survey presents a taxonomy of the recent vision transformer architectures, and more specifically that of the hybrid vision transformers. Additionally, the key features of each architecture such as the attention mechanisms, positional embeddings, multi-scale processing, and convolution are also discussed. This survey highlights the potential of hybrid vision transformers to achieve outstanding performance on a variety of computer vision tasks. Moreover, it also points towards the future directions of this rapidly evolving field.
CB-HVTNet: A channel-boosted hybrid vision transformer network for lymphocyte assessment in histopathological images
May 16, 2023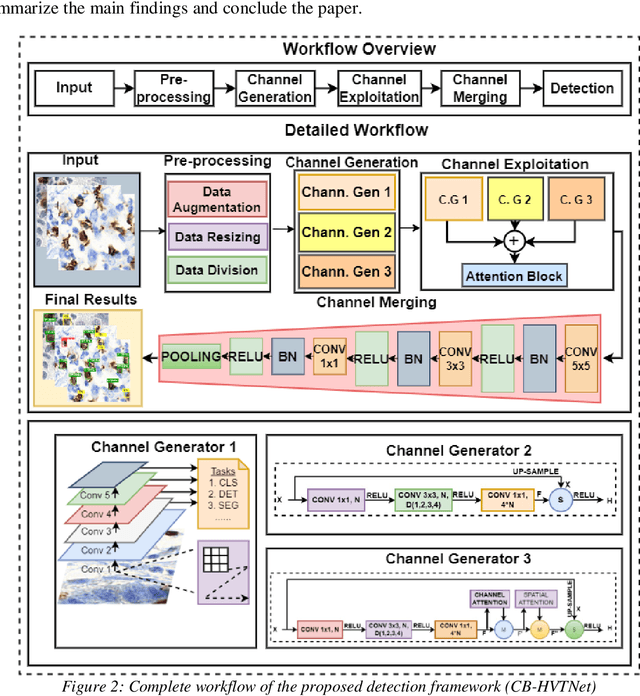

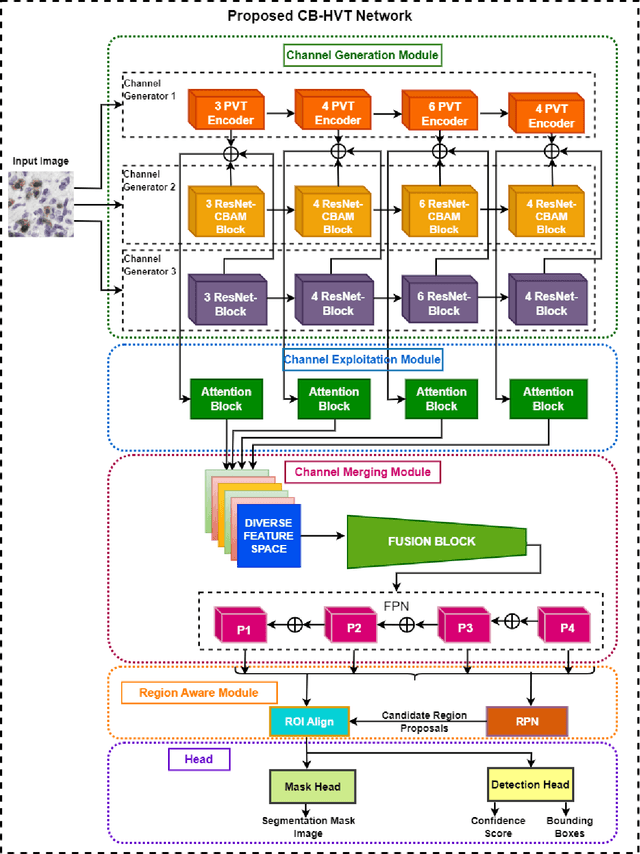

Transformers, due to their ability to learn long range dependencies, have overcome the shortcomings of convolutional neural networks (CNNs) for global perspective learning. Therefore, they have gained the focus of researchers for several vision related tasks including medical diagnosis. However, their multi-head attention module only captures global level feature representations, which is insufficient for medical images. To address this issue, we propose a Channel Boosted Hybrid Vision Transformer (CB HVT) that uses transfer learning to generate boosted channels and employs both transformers and CNNs to analyse lymphocytes in histopathological images. The proposed CB HVT comprises five modules, including a channel generation module, channel exploitation module, channel merging module, region-aware module, and a detection and segmentation head, which work together to effectively identify lymphocytes. The channel generation module uses the idea of channel boosting through transfer learning to extract diverse channels from different auxiliary learners. In the CB HVT, these boosted channels are first concatenated and ranked using an attention mechanism in the channel exploitation module. A fusion block is then utilized in the channel merging module for a gradual and systematic merging of the diverse boosted channels to improve the network's learning representations. The CB HVT also employs a proposal network in its region aware module and a head to effectively identify objects, even in overlapping regions and with artifacts. We evaluated the proposed CB HVT on two publicly available datasets for lymphocyte assessment in histopathological images. The results show that CB HVT outperformed other state of the art detection models, and has good generalization ability, demonstrating its value as a tool for pathologists.
Deep Neural Networks based Meta-Learning for Network Intrusion Detection
Feb 18, 2023Designing an intrusion detection system is difficult as network traffic encompasses various attack types, including new and evolving ones with minor changes. The data used to construct a predictive model has a skewed class distribution and limited representation of attack types, which differ from real network traffic. These limitations result in dataset shift, negatively impacting the machine learning models' predictive abilities and reducing the detection rate against novel attacks. To address the challenge of dataset shift, we introduce the INformation FUsion and Stacking Ensemble (INFUSE) for network intrusion detection. This approach further improves its predictive power by employing a deep neural network-based Meta-Learner on top of INFUSE. First, a hybrid feature space is created by integrating decision and feature spaces. Five different classifiers are utilized to generate a pool of decision spaces. The feature space is then enriched through a deep sparse autoencoder that learns the semantic relationships between attacks. Finally, the deep Meta-Learner acts as an ensemble combiner to analyze the hybrid feature space and make a final decision. Our evaluation on stringent benchmark datasets and comparison to existing techniques showed the effectiveness of INFUSE with an F-Score of 0.91, Accuracy of 91.6%, and Recall of 0.94 on the Test+ dataset, and an F-Score of 0.91, Accuracy of 85.6%, and Recall of 0.87 on the stringent Test-21 dataset. These promising results indicate the proposed technique has strong generalization capability and the potential to detect network attacks.
A Survey of Deep Learning Techniques for the Analysis of COVID-19 and their usability for Detecting Omicron
Feb 13, 2022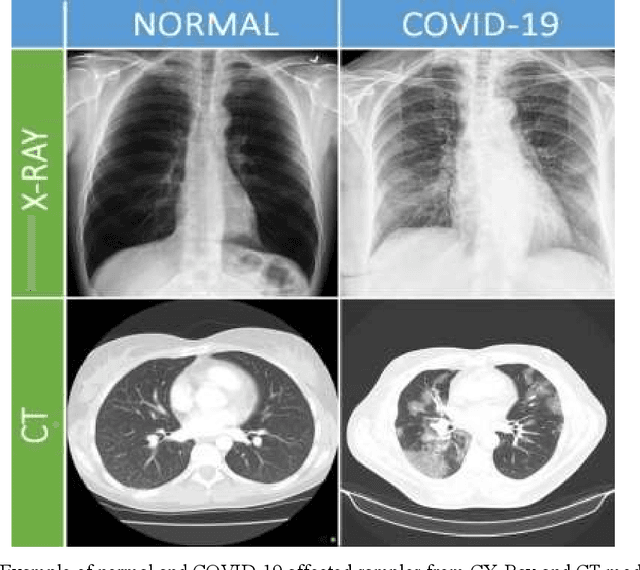
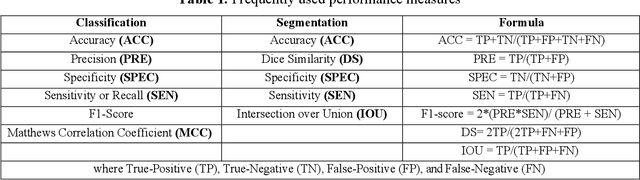
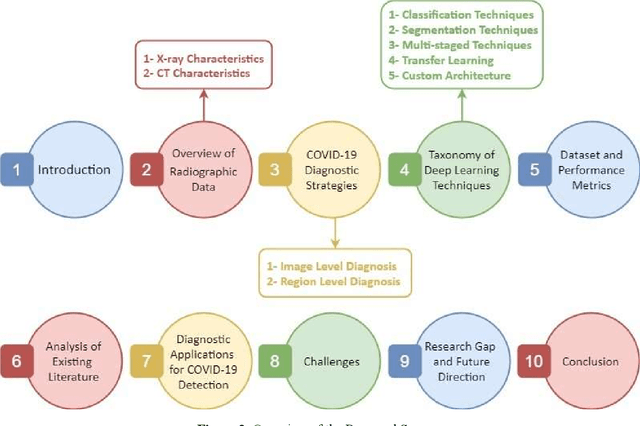
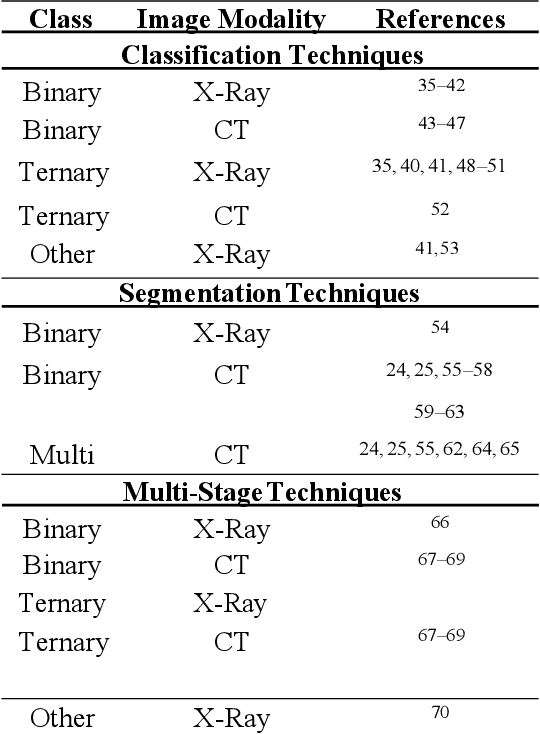
The Coronavirus (COVID-19) outbreak in December 2019 has become an ongoing threat to humans worldwide, creating a health crisis that infected millions of lives, as well as devastating the global economy. Deep learning (DL) techniques have proved helpful in analysis and delineation of infectious regions in radiological images in a timely manner. This paper makes an in-depth survey of DL techniques and draws a taxonomy based on diagnostic strategies and learning approaches. DL techniques are systematically categorized into classification, segmentation, and multi-stage approaches for COVID-19 diagnosis at image and region level analysis. Each category includes pre-trained and custom-made Convolutional Neural Network architectures for detecting COVID-19 infection in radiographic imaging modalities; X-Ray, and Computer Tomography (CT). Furthermore, a discussion is made on challenges in developing diagnostic techniques in pandemic, cross-platform interoperability, and examining imaging modality, in addition to reviewing methodologies and performance measures used in these techniques. This survey provides an insight into promising areas of research in DL for analyzing radiographic images and thus, may further accelerate the research in designing of customized DL based diagnostic tools for effectively dealing with new variants of COVID-19 and emerging challenges.
COVID-19 Detection in Chest X-Ray Images using a New Channel Boosted CNN
Dec 17, 2020
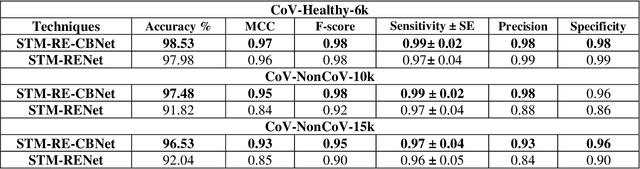
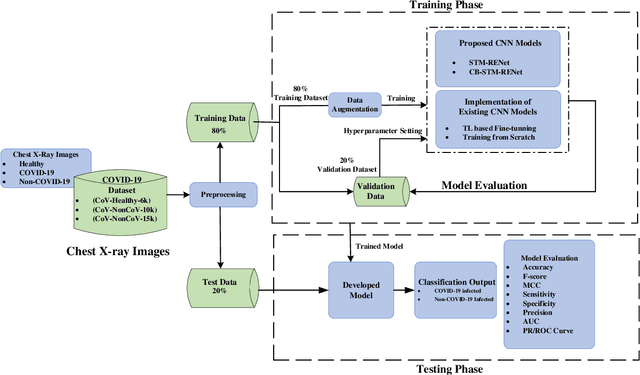
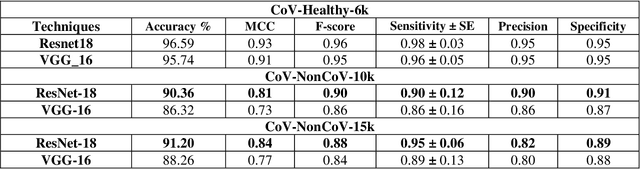
COVID-19 is a highly contagious respiratory infection that has affected a large population across the world and continues with its devastating consequences. It is imperative to detect COVID-19 at the earliest to limit the span of infection. In this work, a new classification technique CB-STM-RENet based on deep Convolutional Neural Network (CNN) and Channel Boosting is proposed for the screening of COVID-19 in chest X-Rays. In this connection, to learn the COVID-19 specific radiographic patterns, a new convolution block based on split-transform-merge (STM) is developed. This new block systematically incorporates region and edge-based operations at each branch to capture the diverse set of features at various levels, especially those related to region homogeneity, textural variations, and boundaries of the infected region. The learning and discrimination capability of the proposed CNN architecture is enhanced by exploiting the Channel Boosting idea that concatenates the auxiliary channels along with the original channels. The auxiliary channels are generated from the pre-trained CNNs using Transfer Learning. The effectiveness of the proposed technique CB-STM-RENet is evaluated on three different datasets of chest X-Rays namely CoV-Healthy-6k, CoV-NonCoV-10k, and CoV-NonCoV-15k. The performance comparison of the proposed CB-STM-RENet with the existing techniques exhibits high performance both in discriminating COVID-19 chest infections from Healthy, as well as, other types of chest infections. CB-STM-RENet provides the highest performance on all these three datasets; especially on the stringent CoV-NonCoV-15k dataset. The good detection rate (97%), and high precision (93%) of the proposed technique suggest that it can be adapted for the diagnosis of COVID-19 infected patients. The test code is available at https://github.com/PRLAB21/COVID-19-Detection-System-using-Chest-X-Ray-Images.
Classification and Region Analysis of COVID-19 Infection using Lung CT Images and Deep Convolutional Neural Networks
Sep 16, 2020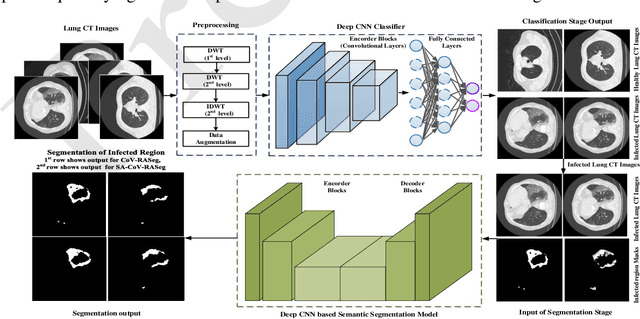
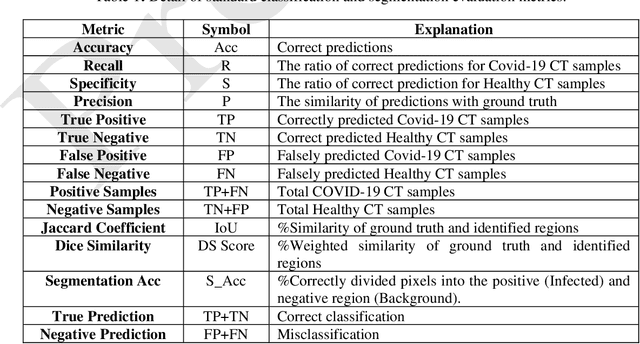
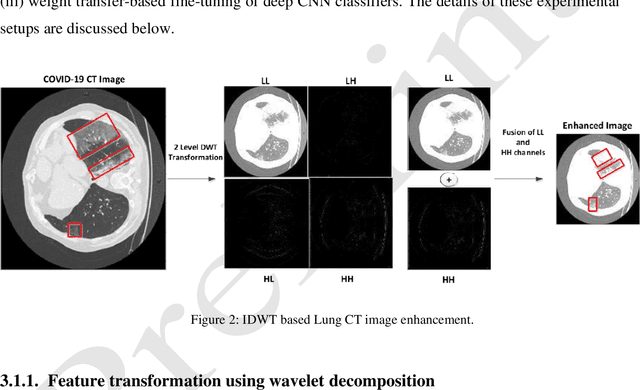
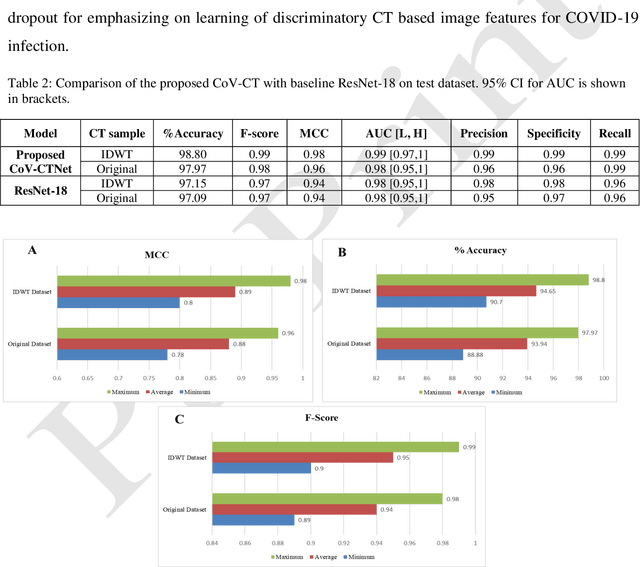
COVID-19 is a global health problem. Consequently, early detection and analysis of the infection patterns are crucial for controlling infection spread as well as devising a treatment plan. This work proposes a two-stage deep Convolutional Neural Networks (CNNs) based framework for delineation of COVID-19 infected regions in Lung CT images. In the first stage, initially, COVID-19 specific CT image features are enhanced using a two-level discrete wavelet transformation. These enhanced CT images are then classified using the proposed custom-made deep CoV-CTNet. In the second stage, the CT images classified as infectious images are provided to the segmentation models for the identification and analysis of COVID-19 infectious regions. In this regard, we propose a novel semantic segmentation model CoV-RASeg, which systematically uses average and max pooling operations in the encoder and decoder blocks. This systematic utilization of max and average pooling operations helps the proposed CoV-RASeg in simultaneously learning both the boundaries and region homogeneity. Moreover, the idea of attention is incorporated to deal with mildly infected regions. The proposed two-stage framework is evaluated on a standard Lung CT image dataset, and its performance is compared with the existing deep CNN models. The performance of the proposed CoV-CTNet is evaluated using Mathew Correlation Coefficient (MCC) measure (0.98) and that of proposed CoV-RASeg using Dice Similarity (DS) score (0.95). The promising results on an unseen test set suggest that the proposed framework has the potential to help the radiologists in the identification and analysis of COVID-19 infected regions.
Deep Object Detection based Mitosis Analysis in Breast Cancer Histopathological Images
Mar 17, 2020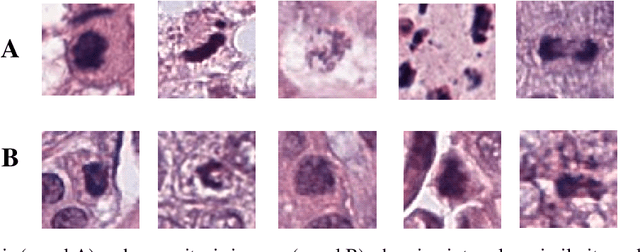

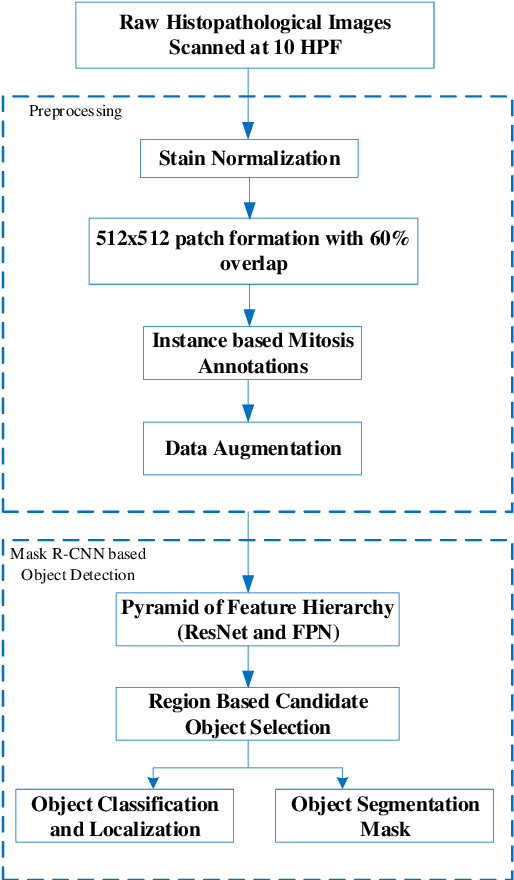
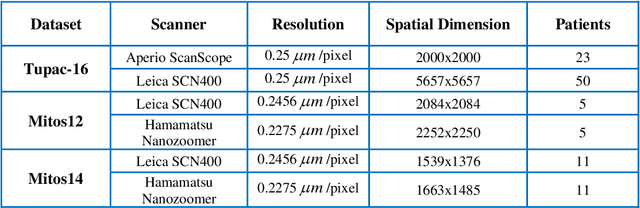
Empirical evaluation of breast tissue biopsies for mitotic nuclei detection is considered an important prognostic biomarker in tumor grading and cancer progression. However, automated mitotic nuclei detection poses several challenges because of the unavailability of pixel-level annotations, different morphological configurations of mitotic nuclei, their sparse representation, and close resemblance with non-mitotic nuclei. These challenges undermine the precision of the automated detection model and thus make detection difficult in a single phase. This work proposes an end-to-end detection system for mitotic nuclei identification in breast cancer histopathological images. Deep object detection-based Mask R-CNN is adapted for mitotic nuclei detection that initially selects the candidate mitotic region with maximum recall. However, in the second phase, these candidate regions are refined by multi-object loss function to improve the precision. The performance of the proposed detection model shows improved discrimination ability (F-score of 0.86) for mitotic nuclei with significant precision (0.86) as compared to the two-stage detection models (F-score of 0.701) on TUPAC16 dataset. Promising results suggest that the deep object detection-based model has the potential to learn the characteristic features of mitotic nuclei from weakly annotated data and suggests that it can be adapted for the identification of other nuclear bodies in histopathological images.