 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiver Fibrosis Quantification and Analysis: The LiQA Dataset and Baseline Method
Dec 22, 2025Liver fibrosis represents a significant global health burden, necessitating accurate staging for effective clinical management. This report introduces the LiQA (Liver Fibrosis Quantification and Analysis) dataset, established as part of the CARE 2024 challenge. Comprising $440$ patients with multi-phase, multi-center MRI scans, the dataset is curated to benchmark algorithms for Liver Segmentation (LiSeg) and Liver Fibrosis Staging (LiFS) under complex real-world conditions, including domain shifts, missing modalities, and spatial misalignment. We further describe the challenge's top-performing methodology, which integrates a semi-supervised learning framework with external data for robust segmentation, and utilizes a multi-view consensus approach with Class Activation Map (CAM)-based regularization for staging. Evaluation of this baseline demonstrates that leveraging multi-source data and anatomical constraints significantly enhances model robustness in clinical settings.
Multi-Resolution Pathology-Language Pre-training Model with Text-Guided Visual Representation
Apr 26, 2025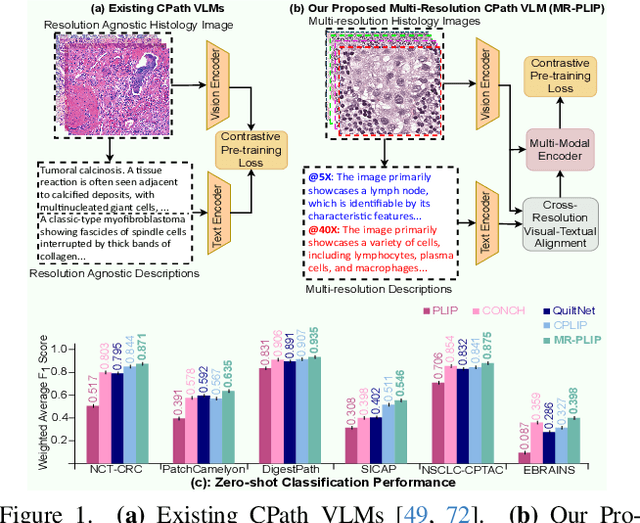
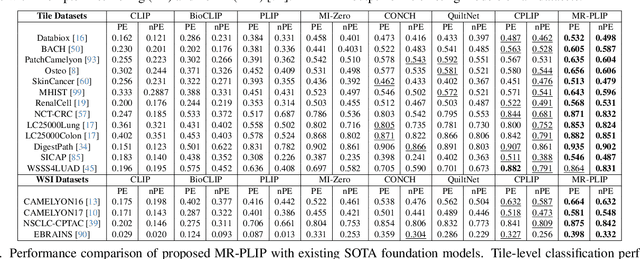
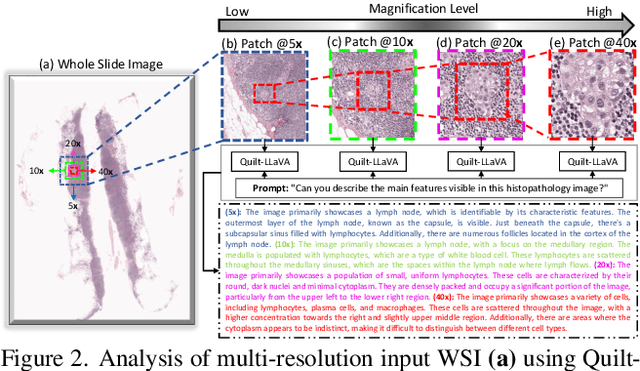
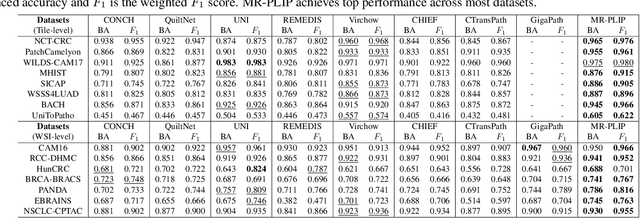
In Computational Pathology (CPath), the introduction of Vision-Language Models (VLMs) has opened new avenues for research, focusing primarily on aligning image-text pairs at a single magnification level. However, this approach might not be sufficient for tasks like cancer subtype classification, tissue phenotyping, and survival analysis due to the limited level of detail that a single-resolution image can provide. Addressing this, we propose a novel multi-resolution paradigm leveraging Whole Slide Images (WSIs) to extract histology patches at multiple resolutions and generate corresponding textual descriptions through advanced CPath VLM. We introduce visual-textual alignment at multiple resolutions as well as cross-resolution alignment to establish more effective text-guided visual representations. Cross-resolution alignment using a multimodal encoder enhances the model's ability to capture context from multiple resolutions in histology images. Our model aims to capture a broader range of information, supported by novel loss functions, enriches feature representation, improves discriminative ability, and enhances generalization across different resolutions. Pre-trained on a comprehensive TCGA dataset with 34 million image-language pairs at various resolutions, our fine-tuned model outperforms state-of-the-art (SOTA) counterparts across multiple datasets and tasks, demonstrating its effectiveness in CPath. The code is available on GitHub at: https://github.com/BasitAlawode/MR-PLIP
AquaticCLIP: A Vision-Language Foundation Model for Underwater Scene Analysis
Feb 03, 2025



The preservation of aquatic biodiversity is critical in mitigating the effects of climate change. Aquatic scene understanding plays a pivotal role in aiding marine scientists in their decision-making processes. In this paper, we introduce AquaticCLIP, a novel contrastive language-image pre-training model tailored for aquatic scene understanding. AquaticCLIP presents a new unsupervised learning framework that aligns images and texts in aquatic environments, enabling tasks such as segmentation, classification, detection, and object counting. By leveraging our large-scale underwater image-text paired dataset without the need for ground-truth annotations, our model enriches existing vision-language models in the aquatic domain. For this purpose, we construct a 2 million underwater image-text paired dataset using heterogeneous resources, including YouTube, Netflix, NatGeo, etc. To fine-tune AquaticCLIP, we propose a prompt-guided vision encoder that progressively aggregates patch features via learnable prompts, while a vision-guided mechanism enhances the language encoder by incorporating visual context. The model is optimized through a contrastive pretraining loss to align visual and textual modalities. AquaticCLIP achieves notable performance improvements in zero-shot settings across multiple underwater computer vision tasks, outperforming existing methods in both robustness and interpretability. Our model sets a new benchmark for vision-language applications in underwater environments. The code and dataset for AquaticCLIP are publicly available on GitHub at xxx.
GenMix: Effective Data Augmentation with Generative Diffusion Model Image Editing
Dec 03, 2024



Data augmentation is widely used to enhance generalization in visual classification tasks. However, traditional methods struggle when source and target domains differ, as in domain adaptation, due to their inability to address domain gaps. This paper introduces GenMix, a generalizable prompt-guided generative data augmentation approach that enhances both in-domain and cross-domain image classification. Our technique leverages image editing to generate augmented images based on custom conditional prompts, designed specifically for each problem type. By blending portions of the input image with its edited generative counterpart and incorporating fractal patterns, our approach mitigates unrealistic images and label ambiguity, improving the performance and adversarial robustness of the resulting models. Efficacy of our method is established with extensive experiments on eight public datasets for general and fine-grained classification, in both in-domain and cross-domain settings. Additionally, we demonstrate performance improvements for self-supervised learning, learning with data scarcity, and adversarial robustness. As compared to the existing state-of-the-art methods, our technique achieves stronger performance across the board.
NT-VOT211: A Large-Scale Benchmark for Night-time Visual Object Tracking
Oct 27, 2024Many current visual object tracking benchmarks such as OTB100, NfS, UAV123, LaSOT, and GOT-10K, predominantly contain day-time scenarios while the challenges posed by the night-time has been less investigated. It is primarily because of the lack of a large-scale, well-annotated night-time benchmark for rigorously evaluating tracking algorithms. To this end, this paper presents NT-VOT211, a new benchmark tailored for evaluating visual object tracking algorithms in the challenging night-time conditions. NT-VOT211 consists of 211 diverse videos, offering 211,000 well-annotated frames with 8 attributes including camera motion, deformation, fast motion, motion blur, tiny target, distractors, occlusion and out-of-view. To the best of our knowledge, it is the largest night-time tracking benchmark to-date that is specifically designed to address unique challenges such as adverse visibility, image blur, and distractors inherent to night-time tracking scenarios. Through a comprehensive analysis of results obtained from 42 diverse tracking algorithms on NT-VOT211, we uncover the strengths and limitations of these algorithms, highlighting opportunities for enhancements in visual object tracking, particularly in environments with suboptimal lighting. Besides, a leaderboard for revealing performance rankings, annotation tools, comprehensive meta-information and all the necessary code for reproducibility of results is made publicly available. We believe that our NT-VOT211 benchmark will not only be instrumental in facilitating field deployment of VOT algorithms, but will also help VOT enhancements and it will unlock new real-world tracking applications. Our dataset and other assets can be found at: {https://github.com/LiuYuML/NV-VOT211.
Depth Attention for Robust RGB Tracking
Oct 27, 2024RGB video object tracking is a fundamental task in computer vision. Its effectiveness can be improved using depth information, particularly for handling motion-blurred target. However, depth information is often missing in commonly used tracking benchmarks. In this work, we propose a new framework that leverages monocular depth estimation to counter the challenges of tracking targets that are out of view or affected by motion blur in RGB video sequences. Specifically, our work introduces following contributions. To the best of our knowledge, we are the first to propose a depth attention mechanism and to formulate a simple framework that allows seamlessly integration of depth information with state of the art tracking algorithms, without RGB-D cameras, elevating accuracy and robustness. We provide extensive experiments on six challenging tracking benchmarks. Our results demonstrate that our approach provides consistent gains over several strong baselines and achieves new SOTA performance. We believe that our method will open up new possibilities for more sophisticated VOT solutions in real-world scenarios. Our code and models are publicly released: https://github.com/LiuYuML/Depth-Attention.
Pseudo-label Refinement for Improving Self-Supervised Learning Systems
Oct 18, 2024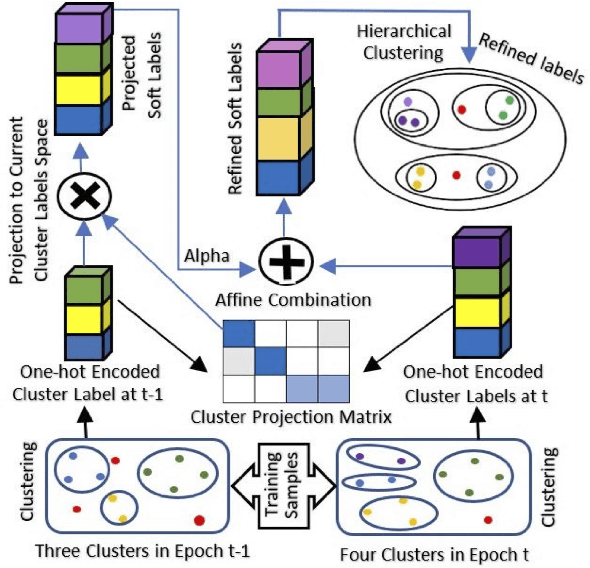

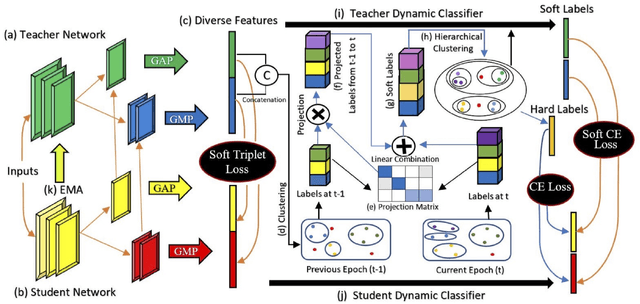

Self-supervised learning systems have gained significant attention in recent years by leveraging clustering-based pseudo-labels to provide supervision without the need for human annotations. However, the noise in these pseudo-labels caused by the clustering methods poses a challenge to the learning process leading to degraded performance. In this work, we propose a pseudo-label refinement (SLR) algorithm to address this issue. The cluster labels from the previous epoch are projected to the current epoch cluster-labels space and a linear combination of the new label and the projected label is computed as a soft refined label containing the information from the previous epoch clusters as well as from the current epoch. In contrast to the common practice of using the maximum value as a cluster/class indicator, we employ hierarchical clustering on these soft pseudo-labels to generate refined hard-labels. This approach better utilizes the information embedded in the soft labels, outperforming the simple maximum value approach for hard label generation. The effectiveness of the proposed SLR algorithm is evaluated in the context of person re-identification (Re-ID) using unsupervised domain adaptation (UDA). Experimental results demonstrate that the modified Re-ID baseline, incorporating the SLR algorithm, achieves significantly improved mean Average Precision (mAP) performance in various UDA tasks, including real-to-synthetic, synthetic-to-real, and different real-to-real scenarios. These findings highlight the efficacy of the SLR algorithm in enhancing the performance of self-supervised learning systems.
Lower-dimensional projections of cellular expression improves cell type classification from single-cell RNA sequencing
Oct 13, 2024



Single-cell RNA sequencing (scRNA-seq) enables the study of cellular diversity at single cell level. It provides a global view of cell-type specification during the onset of biological mechanisms such as developmental processes and human organogenesis. Various statistical, machine and deep learning-based methods have been proposed for cell-type classification. Most of the methods utilizes unsupervised lower dimensional projections obtained from for a large reference data. In this work, we proposed a reference-based method for cell type classification, called EnProCell. The EnProCell, first, computes lower dimensional projections that capture both the high variance and class separability through an ensemble of principle component analysis and multiple discriminant analysis. In the second phase, EnProCell trains a deep neural network on the lower dimensional representation of data to classify cell types. The proposed method outperformed the existing state-of-the-art methods when tested on four different data sets produced from different single-cell sequencing technologies. The EnProCell showed higher accuracy (98.91) and F1 score (98.64) than other methods for predicting reference from reference datasets. Similarly, EnProCell also showed better performance than existing methods in predicting cell types for data with unknown cell types (query) from reference datasets (accuracy:99.52; F1 score: 99.07). In addition to improved performance, the proposed methodology is simple and does not require more computational resources and time. the EnProCell is available at https://github.com/umar1196/EnProCell.
Deep-Ace: LSTM-based Prokaryotic Lysine Acetylation Site Predictor
Oct 13, 2024



Acetylation of lysine residues (K-Ace) is a post-translation modification occurring in both prokaryotes and eukaryotes. It plays a crucial role in disease pathology and cell biology hence it is important to identify these K-Ace sites. In the past, many machine learning-based models using hand-crafted features and encodings have been used to find and analyze the characteristics of K-Ace sites however these methods ignore long term relationships within sequences and therefore observe performance degradation. In the current work we propose Deep-Ace, a deep learning-based framework using Long-Short-Term-Memory (LSTM) network which has the ability to understand and encode long-term relationships within a sequence. Such relations are vital for learning discriminative and effective sequence representations. In the work reported here, the use of LSTM to extract deep features as well as for prediction of K-Ace sites using fully connected layers for eight different species of prokaryotic models (including B. subtilis, C. glutamicum, E. coli, G. kaustophilus, S. eriocheiris, B. velezensis, S. typhimurium, and M. tuberculosis) has been explored. Our proposed method has outperformed existing state of the art models achieving accuracy as 0.80, 0.79, 0.71, 0.75, 0.80, 0.83, 0.756, and 0.82 respectively for eight bacterial species mentioned above. The method with minor modifications can be used for eukaryotic systems and can serve as a tool for the prognosis and diagnosis of various diseases in humans.
Text Classification using Graph Convolutional Networks: A Comprehensive Survey
Oct 12, 2024
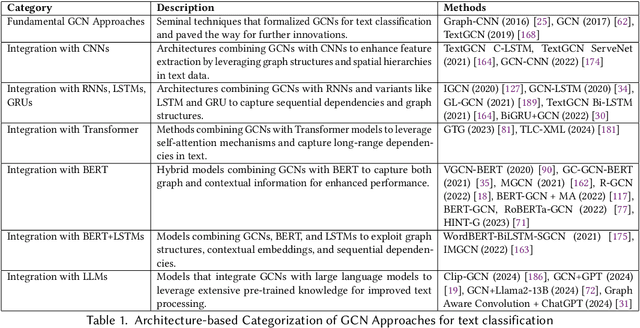
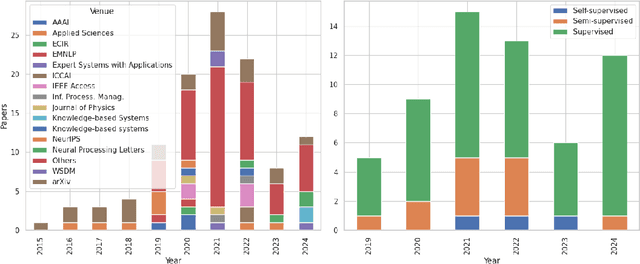
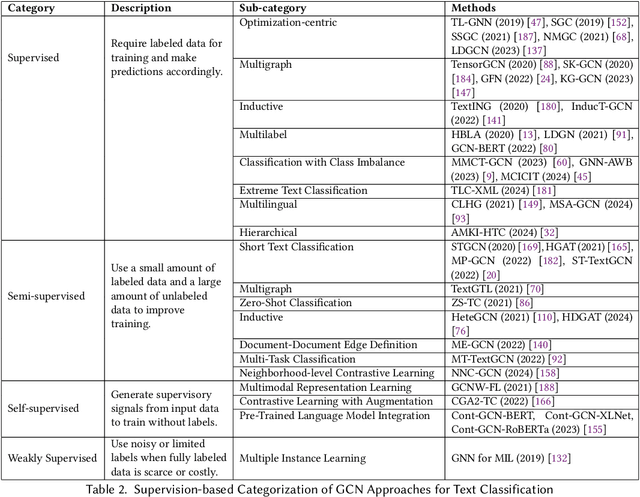
Text classification is a quintessential and practical problem in natural language processing with applications in diverse domains such as sentiment analysis, fake news detection, medical diagnosis, and document classification. A sizable body of recent works exists where researchers have studied and tackled text classification from different angles with varying degrees of success. Graph convolution network (GCN)-based approaches have gained a lot of traction in this domain over the last decade with many implementations achieving state-of-the-art performance in more recent literature and thus, warranting the need for an updated survey. This work aims to summarize and categorize various GCN-based Text Classification approaches with regard to the architecture and mode of supervision. It identifies their strengths and limitations and compares their performance on various benchmark datasets. We also discuss future research directions and the challenges that exist in this domain.