 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLM-HWSI: A Multimodal Large Language Model for Hierarchical Whole Slide Image Understanding
Mar 25, 2026Whole Slide Images (WSIs) exhibit hierarchical structure, where diagnostic information emerges from cellular morphology, regional tissue organization, and global context. Existing Computational Pathology (CPath) Multimodal Large Language Models (MLLMs) typically compress an entire WSI into a single embedding, which hinders fine-grained grounding and ignores how pathologists synthesize evidence across different scales. We introduce \textbf{MLLM-HWSI}, a Hierarchical WSI-level MLLM that aligns visual features with pathology language at four distinct scales, cell as word, patch as phrase, region as sentence, and WSI as paragraph to support interpretable evidence-grounded reasoning. MLLM-HWSI decomposes each WSI into multi-scale embeddings with scale-specific projectors and jointly enforces (i) a hierarchical contrastive objective and (ii) a cross-scale consistency loss, preserving semantic coherence from cells to the WSI. We compute diagnostically relevant patches and aggregate segmented cell embeddings into a compact cellular token per-patch using a lightweight \textit{Cell-Cell Attention Fusion (CCAF)} transformer. The projected multi-scale tokens are fused with text tokens and fed to an instruction-tuned LLM for open-ended reasoning, VQA, report, and caption generation tasks. Trained in three stages, MLLM-HWSI achieves new SOTA results on 13 WSI-level benchmarks across six CPath tasks. By aligning language with multi-scale visual evidence, MLLM-HWSI provides accurate, interpretable outputs that mirror diagnostic workflows and advance holistic WSI understanding. Code is available at: \href{https://github.com/BasitAlawode/HWSI-MLLM}{GitHub}.
Multi-Resolution Pathology-Language Pre-training Model with Text-Guided Visual Representation
Apr 26, 2025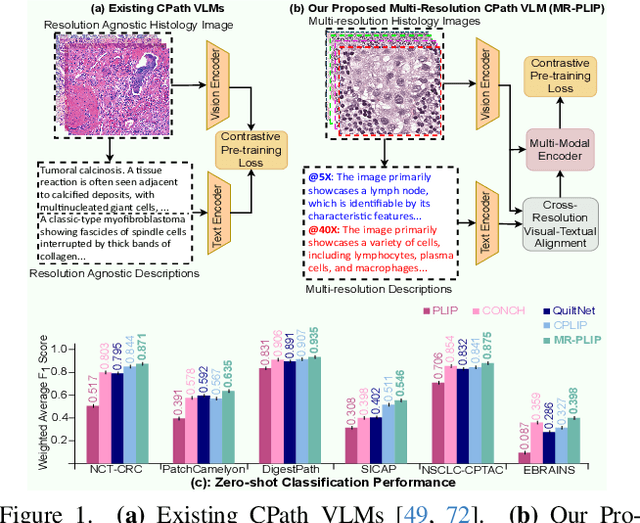
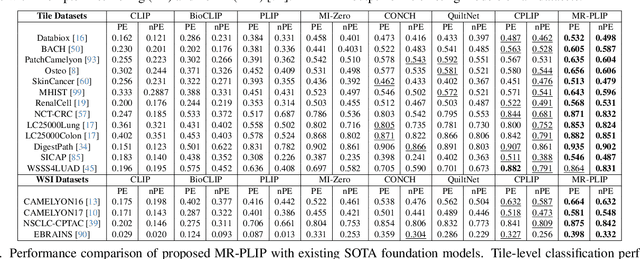
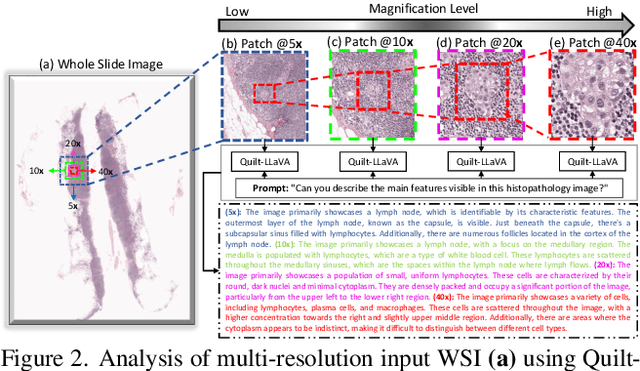
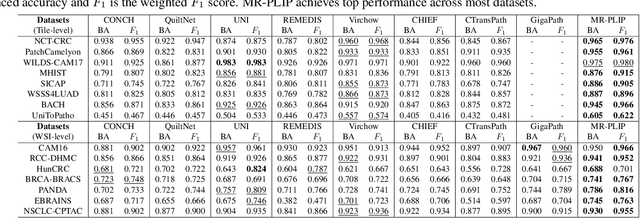
In Computational Pathology (CPath), the introduction of Vision-Language Models (VLMs) has opened new avenues for research, focusing primarily on aligning image-text pairs at a single magnification level. However, this approach might not be sufficient for tasks like cancer subtype classification, tissue phenotyping, and survival analysis due to the limited level of detail that a single-resolution image can provide. Addressing this, we propose a novel multi-resolution paradigm leveraging Whole Slide Images (WSIs) to extract histology patches at multiple resolutions and generate corresponding textual descriptions through advanced CPath VLM. We introduce visual-textual alignment at multiple resolutions as well as cross-resolution alignment to establish more effective text-guided visual representations. Cross-resolution alignment using a multimodal encoder enhances the model's ability to capture context from multiple resolutions in histology images. Our model aims to capture a broader range of information, supported by novel loss functions, enriches feature representation, improves discriminative ability, and enhances generalization across different resolutions. Pre-trained on a comprehensive TCGA dataset with 34 million image-language pairs at various resolutions, our fine-tuned model outperforms state-of-the-art (SOTA) counterparts across multiple datasets and tasks, demonstrating its effectiveness in CPath. The code is available on GitHub at: https://github.com/BasitAlawode/MR-PLIP
AquaticCLIP: A Vision-Language Foundation Model for Underwater Scene Analysis
Feb 03, 2025



The preservation of aquatic biodiversity is critical in mitigating the effects of climate change. Aquatic scene understanding plays a pivotal role in aiding marine scientists in their decision-making processes. In this paper, we introduce AquaticCLIP, a novel contrastive language-image pre-training model tailored for aquatic scene understanding. AquaticCLIP presents a new unsupervised learning framework that aligns images and texts in aquatic environments, enabling tasks such as segmentation, classification, detection, and object counting. By leveraging our large-scale underwater image-text paired dataset without the need for ground-truth annotations, our model enriches existing vision-language models in the aquatic domain. For this purpose, we construct a 2 million underwater image-text paired dataset using heterogeneous resources, including YouTube, Netflix, NatGeo, etc. To fine-tune AquaticCLIP, we propose a prompt-guided vision encoder that progressively aggregates patch features via learnable prompts, while a vision-guided mechanism enhances the language encoder by incorporating visual context. The model is optimized through a contrastive pretraining loss to align visual and textual modalities. AquaticCLIP achieves notable performance improvements in zero-shot settings across multiple underwater computer vision tasks, outperforming existing methods in both robustness and interpretability. Our model sets a new benchmark for vision-language applications in underwater environments. The code and dataset for AquaticCLIP are publicly available on GitHub at xxx.
Transformer-Based Wireless Capsule Endoscopy Bleeding Tissue Detection and Classification
Dec 26, 2024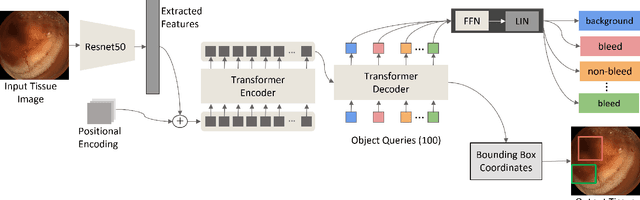

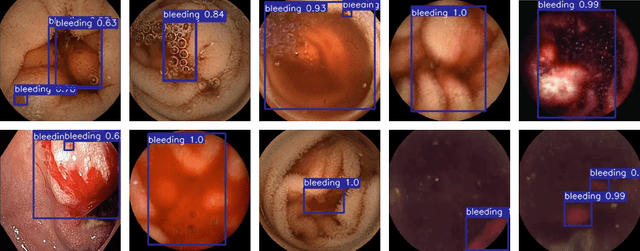
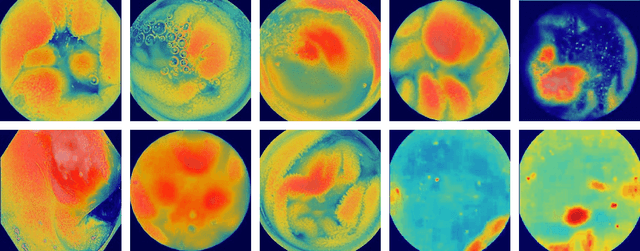
Informed by the success of the transformer model in various computer vision tasks, we design an end-to-end trainable model for the automatic detection and classification of bleeding and non-bleeding frames extracted from Wireless Capsule Endoscopy (WCE) videos. Based on the DETR model, our model uses the Resnet50 for feature extraction, the transformer encoder-decoder for bleeding and non-bleeding region detection, and a feedforward neural network for classification. Trained in an end-to-end approach on the Auto-WCEBleedGen Version 1 challenge training set, our model performs both detection and classification tasks as a single unit. Our model achieves an accuracy, recall, and F1-score classification percentage score of 98.28, 96.79, and 98.37 respectively, on the Auto-WCEBleedGen version 1 validation set. Further, we record an average precision (AP @ 0.5), mean-average precision (mAP) of 0.7447 and 0.7328 detection results. This earned us a 3rd place position in the challenge. Our code is publicly available via https://github.com/BasitAlawode/WCEBleedGen.
Predicting the Best of N Visual Trackers
Jul 22, 2024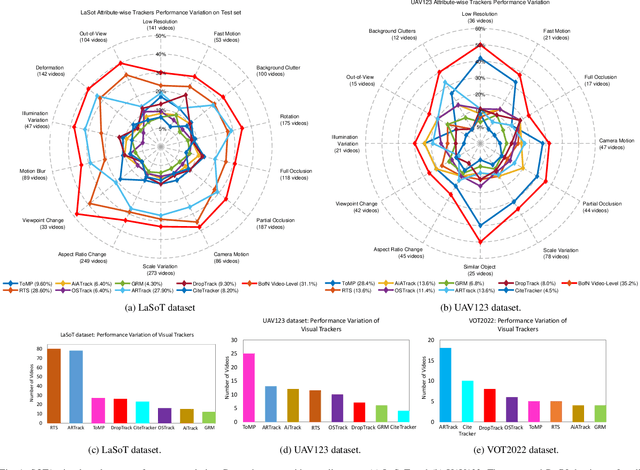
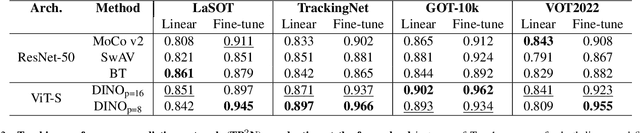
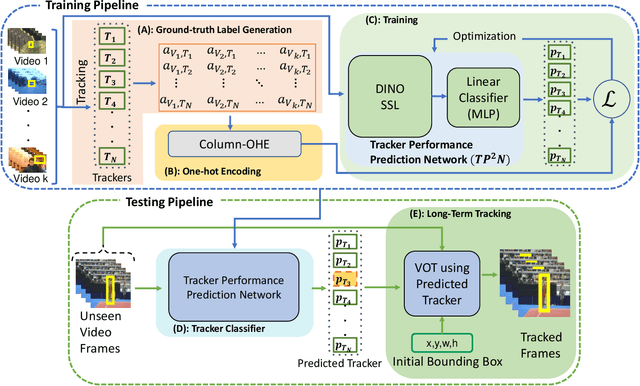
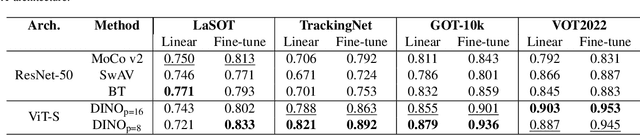
We observe that the performance of SOTA visual trackers surprisingly strongly varies across different video attributes and datasets. No single tracker remains the best performer across all tracking attributes and datasets. To bridge this gap, for a given video sequence, we predict the "Best of the N Trackers", called the BofN meta-tracker. At its core, a Tracking Performance Prediction Network (TP2N) selects a predicted best performing visual tracker for the given video sequence using only a few initial frames. We also introduce a frame-level BofN meta-tracker which keeps predicting best performer after regular temporal intervals. The TP2N is based on self-supervised learning architectures MocoV2, SwAv, BT, and DINO; experiments show that the DINO with ViT-S as a backbone performs the best. The video-level BofN meta-tracker outperforms, by a large margin, existing SOTA trackers on nine standard benchmarks - LaSOT, TrackingNet, GOT-10K, VOT2019, VOT2021, VOT2022, UAV123, OTB100, and WebUAV-3M. Further improvement is achieved by the frame-level BofN meta-tracker effectively handling variations in the tracking scenarios within long sequences. For instance, on GOT-10k, BofN meta-tracker average overlap is 88.7% and 91.1% with video and frame-level settings respectively. The best performing tracker, RTS, achieves 85.20% AO. On VOT2022, BofN expected average overlap is 67.88% and 70.98% with video and frame level settings, compared to the best performing ARTrack, 64.12%. This work also presents an extensive evaluation of competitive tracking methods on all commonly used benchmarks, following their protocols. The code, the trained models, and the results will soon be made publicly available on https://github.com/BasitAlawode/Best_of_N_Trackers.
Learning Spatial-Temporal Regularized Tensor Sparse RPCA for Background Subtraction
Sep 27, 2023Video background subtraction is one of the fundamental problems in computer vision that aims to segment all moving objects. Robust principal component analysis has been identified as a promising unsupervised paradigm for background subtraction tasks in the last decade thanks to its competitive performance in a number of benchmark datasets. Tensor robust principal component analysis variations have improved background subtraction performance further. However, because moving object pixels in the sparse component are treated independently and do not have to adhere to spatial-temporal structured-sparsity constraints, performance is reduced for sequences with dynamic backgrounds, camouflaged, and camera jitter problems. In this work, we present a spatial-temporal regularized tensor sparse RPCA algorithm for precise background subtraction. Within the sparse component, we impose spatial-temporal regularizations in the form of normalized graph-Laplacian matrices. To do this, we build two graphs, one across the input tensor spatial locations and the other across its frontal slices in the time domain. While maximizing the objective function, we compel the tensor sparse component to serve as the spatiotemporal eigenvectors of the graph-Laplacian matrices. The disconnected moving object pixels in the sparse component are preserved by the proposed graph-based regularizations since they both comprise of spatiotemporal subspace-based structure. Additionally, we propose a unique objective function that employs batch and online-based optimization methods to jointly maximize the background-foreground and spatial-temporal regularization components. Experiments are performed on six publicly available background subtraction datasets that demonstrate the superior performance of the proposed algorithm compared to several existing methods. Our source code will be available very soon.
Improving Underwater Visual Tracking With a Large Scale Dataset and Image Enhancement
Aug 31, 2023This paper presents a new dataset and general tracker enhancement method for Underwater Visual Object Tracking (UVOT). Despite its significance, underwater tracking has remained unexplored due to data inaccessibility. It poses distinct challenges; the underwater environment exhibits non-uniform lighting conditions, low visibility, lack of sharpness, low contrast, camouflage, and reflections from suspended particles. Performance of traditional tracking methods designed primarily for terrestrial or open-air scenarios drops in such conditions. We address the problem by proposing a novel underwater image enhancement algorithm designed specifically to boost tracking quality. The method has resulted in a significant performance improvement, of up to 5.0% AUC, of state-of-the-art (SOTA) visual trackers. To develop robust and accurate UVOT methods, large-scale datasets are required. To this end, we introduce a large-scale UVOT benchmark dataset consisting of 400 video segments and 275,000 manually annotated frames enabling underwater training and evaluation of deep trackers. The videos are labelled with several underwater-specific tracking attributes including watercolor variation, target distractors, camouflage, target relative size, and low visibility conditions. The UVOT400 dataset, tracking results, and the code are publicly available on: https://github.com/BasitAlawode/UWVOT400.