 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFact or Fake? Assessing the Role of Deepfake Detectors in Multimodal Misinformation Detection
Feb 02, 2026In multimodal misinformation, deception usually arises not just from pixel-level manipulations in an image, but from the semantic and contextual claim jointly expressed by the image-text pair. Yet most deepfake detectors, engineered to detect pixel-level forgeries, do not account for claim-level meaning, despite their growing integration in automated fact-checking (AFC) pipelines. This raises a central scientific and practical question: Do pixel-level detectors contribute useful signal for verifying image-text claims, or do they instead introduce misleading authenticity priors that undermine evidence-based reasoning? We provide the first systematic analysis of deepfake detectors in the context of multimodal misinformation detection. Using two complementary benchmarks, MMFakeBench and DGM4, we evaluate: (1) state-of-the-art image-only deepfake detectors, (2) an evidence-driven fact-checking system that performs tool-guided retrieval via Monte Carlo Tree Search (MCTS) and engages in deliberative inference through Multi-Agent Debate (MAD), and (3) a hybrid fact-checking system that injects detector outputs as auxiliary evidence. Results across both benchmark datasets show that deepfake detectors offer limited standalone value, achieving F1 scores in the range of 0.26-0.53 on MMFakeBench and 0.33-0.49 on DGM4, and that incorporating their predictions into fact-checking pipelines consistently reduces performance by 0.04-0.08 F1 due to non-causal authenticity assumptions. In contrast, the evidence-centric fact-checking system achieves the highest performance, reaching F1 scores of approximately 0.81 on MMFakeBench and 0.55 on DGM4. Overall, our findings demonstrate that multimodal claim verification is driven primarily by semantic understanding and external evidence, and that pixel-level artifact signals do not reliably enhance reasoning over real-world image-text misinformation.
TSkel-Mamba: Temporal Dynamic Modeling via State Space Model for Human Skeleton-based Action Recognition
Dec 12, 2025Skeleton-based action recognition has garnered significant attention in the computer vision community. Inspired by the recent success of the selective state-space model (SSM) Mamba in modeling 1D temporal sequences, we propose TSkel-Mamba, a hybrid Transformer-Mamba framework that effectively captures both spatial and temporal dynamics. In particular, our approach leverages Spatial Transformer for spatial feature learning while utilizing Mamba for temporal modeling. Mamba, however, employs separate SSM blocks for individual channels, which inherently limits its ability to model inter-channel dependencies. To better adapt Mamba for skeleton data and enhance Mamba`s ability to model temporal dependencies, we introduce a Temporal Dynamic Modeling (TDM) block, which is a versatile plug-and-play component that integrates a novel Multi-scale Temporal Interaction (MTI) module. The MTI module employs multi-scale Cycle operators to capture cross-channel temporal interactions, a critical factor in action recognition. Extensive experiments on NTU-RGB+D 60, NTU-RGB+D 120, NW-UCLA and UAV-Human datasets demonstrate that TSkel-Mamba achieves state-of-the-art performance while maintaining low inference time, making it both efficient and highly effective.
Boosting Skeleton-based Zero-Shot Action Recognition with Training-Free Test-Time Adaptation
Dec 12, 2025We introduce Skeleton-Cache, the first training-free test-time adaptation framework for skeleton-based zero-shot action recognition (SZAR), aimed at improving model generalization to unseen actions during inference. Skeleton-Cache reformulates inference as a lightweight retrieval process over a non-parametric cache that stores structured skeleton representations, combining both global and fine-grained local descriptors. To guide the fusion of descriptor-wise predictions, we leverage the semantic reasoning capabilities of large language models (LLMs) to assign class-specific importance weights. By integrating these structured descriptors with LLM-guided semantic priors, Skeleton-Cache dynamically adapts to unseen actions without any additional training or access to training data. Extensive experiments on NTU RGB+D 60/120 and PKU-MMD II demonstrate that Skeleton-Cache consistently boosts the performance of various SZAR backbones under both zero-shot and generalized zero-shot settings. The code is publicly available at https://github.com/Alchemist0754/Skeleton-Cache.
DynaPURLS: Dynamic Refinement of Part-aware Representations for Skeleton-based Zero-Shot Action Recognition
Dec 12, 2025Zero-shot skeleton-based action recognition (ZS-SAR) is fundamentally constrained by prevailing approaches that rely on aligning skeleton features with static, class-level semantics. This coarse-grained alignment fails to bridge the domain shift between seen and unseen classes, thereby impeding the effective transfer of fine-grained visual knowledge. To address these limitations, we introduce \textbf{DynaPURLS}, a unified framework that establishes robust, multi-scale visual-semantic correspondences and dynamically refines them at inference time to enhance generalization. Our framework leverages a large language model to generate hierarchical textual descriptions that encompass both global movements and local body-part dynamics. Concurrently, an adaptive partitioning module produces fine-grained visual representations by semantically grouping skeleton joints. To fortify this fine-grained alignment against the train-test domain shift, DynaPURLS incorporates a dynamic refinement module. During inference, this module adapts textual features to the incoming visual stream via a lightweight learnable projection. This refinement process is stabilized by a confidence-aware, class-balanced memory bank, which mitigates error propagation from noisy pseudo-labels. Extensive experiments on three large-scale benchmark datasets, including NTU RGB+D 60/120 and PKU-MMD, demonstrate that DynaPURLS significantly outperforms prior art, setting new state-of-the-art records. The source code is made publicly available at https://github.com/Alchemist0754/DynaPURLS
Hybrid Transformer-Mamba Architecture for Weakly Supervised Volumetric Medical Segmentation
Dec 11, 2025Weakly supervised semantic segmentation offers a label-efficient solution to train segmentation models for volumetric medical imaging. However, existing approaches often rely on 2D encoders that neglect the inherent volumetric nature of the data. We propose TranSamba, a hybrid Transformer-Mamba architecture designed to capture 3D context for weakly supervised volumetric medical segmentation. TranSamba augments a standard Vision Transformer backbone with Cross-Plane Mamba blocks, which leverage the linear complexity of state space models for efficient information exchange across neighboring slices. The information exchange enhances the pairwise self-attention within slices computed by the Transformer blocks, directly contributing to the attention maps for object localization. TranSamba achieves effective volumetric modeling with time complexity that scales linearly with the input volume depth and maintains constant memory usage for batch processing. Extensive experiments on three datasets demonstrate that TranSamba establishes new state-of-the-art performance, consistently outperforming existing methods across diverse modalities and pathologies. Our source code and trained models are openly accessible at: https://github.com/YihengLyu/TranSamba.
Multi-Granularity Mutual Refinement Network for Zero-Shot Learning
Nov 11, 2025Zero-shot learning (ZSL) aims to recognize unseen classes with zero samples by transferring semantic knowledge from seen classes. Current approaches typically correlate global visual features with semantic information (i.e., attributes) or align local visual region features with corresponding attributes to enhance visual-semantic interactions. Although effective, these methods often overlook the intrinsic interactions between local region features, which can further improve the acquisition of transferable and explicit visual features. In this paper, we propose a network named Multi-Granularity Mutual Refinement Network (Mg-MRN), which refine discriminative and transferable visual features by learning decoupled multi-granularity features and cross-granularity feature interactions. Specifically, we design a multi-granularity feature extraction module to learn region-level discriminative features through decoupled region feature mining. Then, a cross-granularity feature fusion module strengthens the inherent interactions between region features of varying granularities. This module enhances the discriminability of representations at each granularity level by integrating region representations from adjacent hierarchies, further improving ZSL recognition performance. Extensive experiments on three popular ZSL benchmark datasets demonstrate the superiority and competitiveness of our proposed Mg-MRN method. Our code is available at https://github.com/NingWang2049/Mg-MRN.
LatentMove: Towards Complex Human Movement Video Generation
May 28, 2025Image-to-video (I2V) generation seeks to produce realistic motion sequences from a single reference image. Although recent methods exhibit strong temporal consistency, they often struggle when dealing with complex, non-repetitive human movements, leading to unnatural deformations. To tackle this issue, we present LatentMove, a DiT-based framework specifically tailored for highly dynamic human animation. Our architecture incorporates a conditional control branch and learnable face/body tokens to preserve consistency as well as fine-grained details across frames. We introduce Complex-Human-Videos (CHV), a dataset featuring diverse, challenging human motions designed to benchmark the robustness of I2V systems. We also introduce two metrics to assess the flow and silhouette consistency of generated videos with their ground truth. Experimental results indicate that LatentMove substantially improves human animation quality--particularly when handling rapid, intricate movements--thereby pushing the boundaries of I2V generation. The code, the CHV dataset, and the evaluation metrics will be available at https://github.com/ --.
Watch and Listen: Understanding Audio-Visual-Speech Moments with Multimodal LLM
May 23, 2025Humans naturally understand moments in a video by integrating visual and auditory cues. For example, localizing a scene in the video like "A scientist passionately speaks on wildlife conservation as dramatic orchestral music plays, with the audience nodding and applauding" requires simultaneous processing of visual, audio, and speech signals. However, existing models often struggle to effectively fuse and interpret audio information, limiting their capacity for comprehensive video temporal understanding. To address this, we present TriSense, a triple-modality large language model designed for holistic video temporal understanding through the integration of visual, audio, and speech modalities. Central to TriSense is a Query-Based Connector that adaptively reweights modality contributions based on the input query, enabling robust performance under modality dropout and allowing flexible combinations of available inputs. To support TriSense's multimodal capabilities, we introduce TriSense-2M, a high-quality dataset of over 2 million curated samples generated via an automated pipeline powered by fine-tuned LLMs. TriSense-2M includes long-form videos and diverse modality combinations, facilitating broad generalization. Extensive experiments across multiple benchmarks demonstrate the effectiveness of TriSense and its potential to advance multimodal video analysis. Code and dataset will be publicly released.
Multi-Resolution Pathology-Language Pre-training Model with Text-Guided Visual Representation
Apr 26, 2025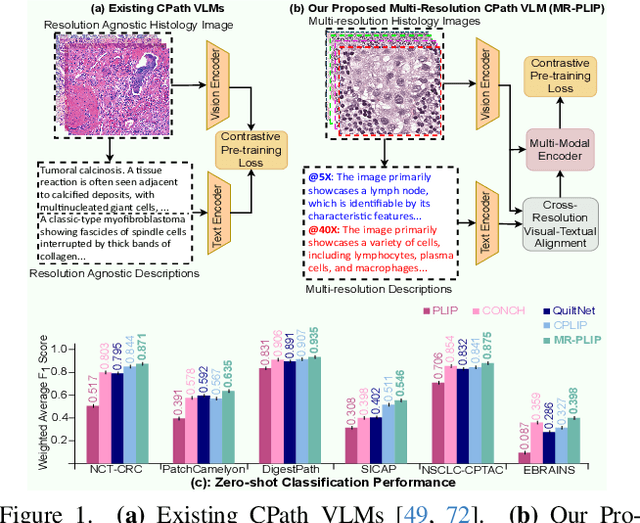
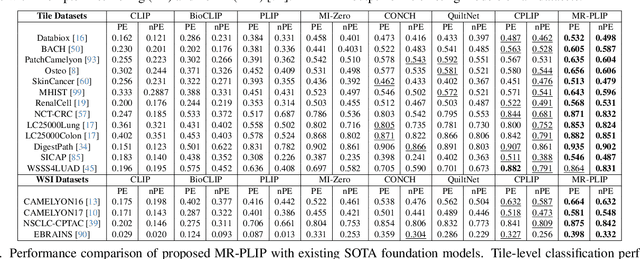
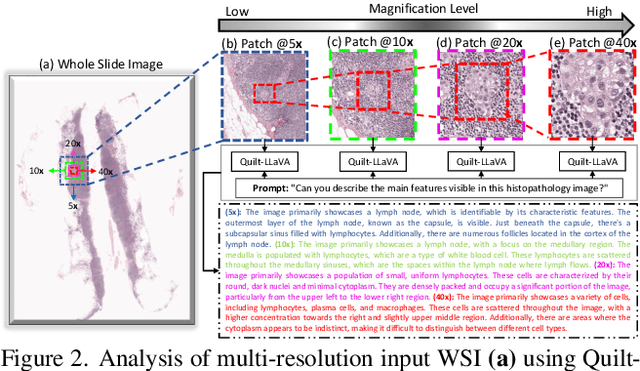
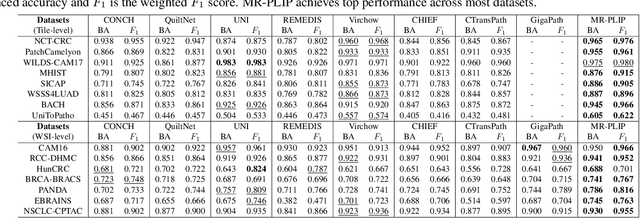
In Computational Pathology (CPath), the introduction of Vision-Language Models (VLMs) has opened new avenues for research, focusing primarily on aligning image-text pairs at a single magnification level. However, this approach might not be sufficient for tasks like cancer subtype classification, tissue phenotyping, and survival analysis due to the limited level of detail that a single-resolution image can provide. Addressing this, we propose a novel multi-resolution paradigm leveraging Whole Slide Images (WSIs) to extract histology patches at multiple resolutions and generate corresponding textual descriptions through advanced CPath VLM. We introduce visual-textual alignment at multiple resolutions as well as cross-resolution alignment to establish more effective text-guided visual representations. Cross-resolution alignment using a multimodal encoder enhances the model's ability to capture context from multiple resolutions in histology images. Our model aims to capture a broader range of information, supported by novel loss functions, enriches feature representation, improves discriminative ability, and enhances generalization across different resolutions. Pre-trained on a comprehensive TCGA dataset with 34 million image-language pairs at various resolutions, our fine-tuned model outperforms state-of-the-art (SOTA) counterparts across multiple datasets and tasks, demonstrating its effectiveness in CPath. The code is available on GitHub at: https://github.com/BasitAlawode/MR-PLIP
Polarisation-Inclusive Spiking Neural Networks for Real-Time RFI Detection in Modern Radio Telescopes
Apr 16, 2025Radio Frequency Interference (RFI) is a known growing challenge for radio astronomy, intensified by increasing observatory sensitivity and prevalence of orbital RFI sources. Spiking Neural Networks (SNNs) offer a promising solution for real-time RFI detection by exploiting the time-varying nature of radio observation and neuron dynamics together. This work explores the inclusion of polarisation information in SNN-based RFI detection, using simulated data from the Hydrogen Epoch of Reionisation Array (HERA) instrument and provides power usage estimates for deploying SNN-based RFI detection on existing neuromorphic hardware. Preliminary results demonstrate state-of-the-art detection accuracy and highlight possible extensive energy-efficiency gains.