 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCytoplasmic Strings Analysis in Human Embryo Time-Lapse Videos using Deep Learning Framework
Dec 10, 2025Infertility is a major global health issue, and while in-vitro fertilization has improved treatment outcomes, embryo selection remains a critical bottleneck. Time-lapse imaging enables continuous, non-invasive monitoring of embryo development, yet most automated assessment methods rely solely on conventional morphokinetic features and overlook emerging biomarkers. Cytoplasmic Strings, thin filamentous structures connecting the inner cell mass and trophectoderm in expanded blastocysts, have been associated with faster blastocyst formation, higher blastocyst grades, and improved viability. However, CS assessment currently depends on manual visual inspection, which is labor-intensive, subjective, and severely affected by detection and subtle visual appearance. In this work, we present, to the best of our knowledge, the first computational framework for CS analysis in human IVF embryos. We first design a human-in-the-loop annotation pipeline to curate a biologically validated CS dataset from TLI videos, comprising 13,568 frames with highly sparse CS-positive instances. Building on this dataset, we propose a two-stage deep learning framework that (i) classifies CS presence at the frame level and (ii) localizes CS regions in positive cases. To address severe imbalance and feature uncertainty, we introduce the Novel Uncertainty-aware Contractive Embedding (NUCE) loss, which couples confidence-aware reweighting with an embedding contraction term to form compact, well-separated class clusters. NUCE consistently improves F1-score across five transformer backbones, while RF-DETR-based localization achieves state-of-the-art (SOTA) detection performance for thin, low-contrast CS structures. The source code will be made publicly available at: https://github.com/HamadYA/CS_Detection.
STING-BEE: Towards Vision-Language Model for Real-World X-ray Baggage Security Inspection
Apr 03, 2025Advancements in Computer-Aided Screening (CAS) systems are essential for improving the detection of security threats in X-ray baggage scans. However, current datasets are limited in representing real-world, sophisticated threats and concealment tactics, and existing approaches are constrained by a closed-set paradigm with predefined labels. To address these challenges, we introduce STCray, the first multimodal X-ray baggage security dataset, comprising 46,642 image-caption paired scans across 21 threat categories, generated using an X-ray scanner for airport security. STCray is meticulously developed with our specialized protocol that ensures domain-aware, coherent captions, that lead to the multi-modal instruction following data in X-ray baggage security. This allows us to train a domain-aware visual AI assistant named STING-BEE that supports a range of vision-language tasks, including scene comprehension, referring threat localization, visual grounding, and visual question answering (VQA), establishing novel baselines for multi-modal learning in X-ray baggage security. Further, STING-BEE shows state-of-the-art generalization in cross-domain settings. Code, data, and models are available at https://divs1159.github.io/STING-BEE/.
Transformer-Based Wireless Capsule Endoscopy Bleeding Tissue Detection and Classification
Dec 26, 2024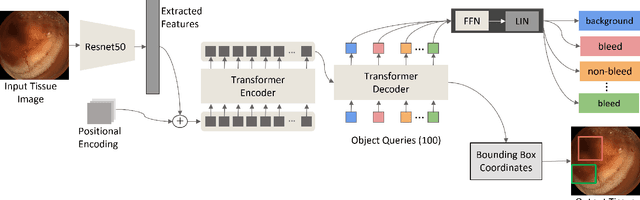

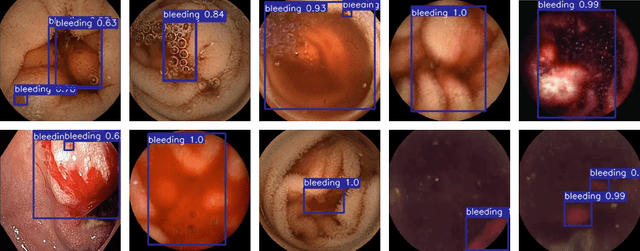
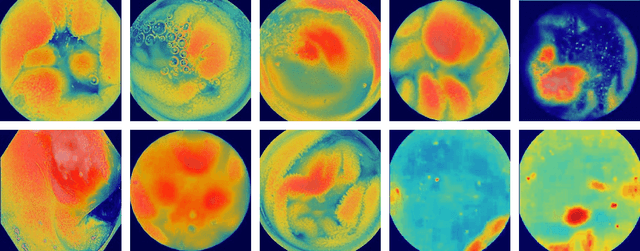
Informed by the success of the transformer model in various computer vision tasks, we design an end-to-end trainable model for the automatic detection and classification of bleeding and non-bleeding frames extracted from Wireless Capsule Endoscopy (WCE) videos. Based on the DETR model, our model uses the Resnet50 for feature extraction, the transformer encoder-decoder for bleeding and non-bleeding region detection, and a feedforward neural network for classification. Trained in an end-to-end approach on the Auto-WCEBleedGen Version 1 challenge training set, our model performs both detection and classification tasks as a single unit. Our model achieves an accuracy, recall, and F1-score classification percentage score of 98.28, 96.79, and 98.37 respectively, on the Auto-WCEBleedGen version 1 validation set. Further, we record an average precision (AP @ 0.5), mean-average precision (mAP) of 0.7447 and 0.7328 detection results. This earned us a 3rd place position in the challenge. Our code is publicly available via https://github.com/BasitAlawode/WCEBleedGen.
Emotional Speaker Identification using a Novel Capsule Nets Model
Jan 09, 2022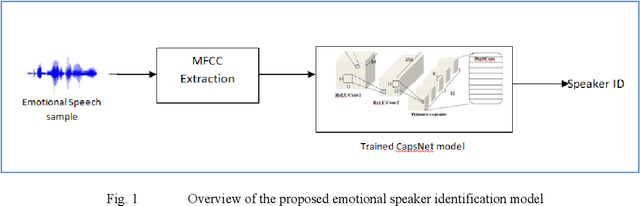

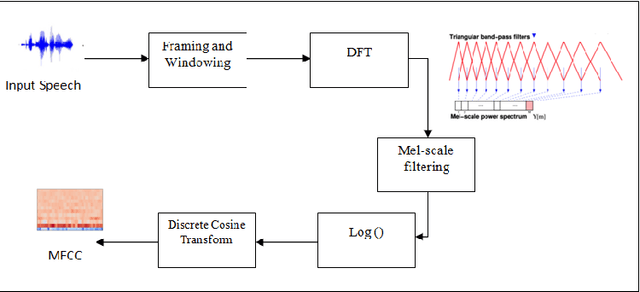
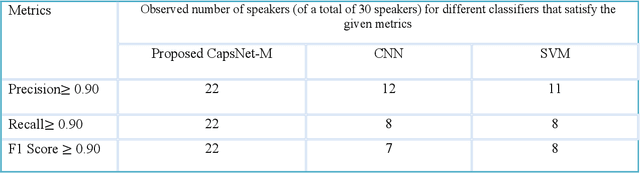
Speaker recognition systems are widely used in various applications to identify a person by their voice; however, the high degree of variability in speech signals makes this a challenging task. Dealing with emotional variations is very difficult because emotions alter the voice characteristics of a person; thus, the acoustic features differ from those used to train models in a neutral environment. Therefore, speaker recognition models trained on neutral speech fail to correctly identify speakers under emotional stress. Although considerable advancements in speaker identification have been made using convolutional neural networks (CNN), CNNs cannot exploit the spatial association between low-level features. Inspired by the recent introduction of capsule networks (CapsNets), which are based on deep learning to overcome the inadequacy of CNNs in preserving the pose relationship between low-level features with their pooling technique, this study investigates the performance of using CapsNets in identifying speakers from emotional speech recordings. A CapsNet-based speaker identification model is proposed and evaluated using three distinct speech databases, i.e., the Emirati Speech Database, SUSAS Dataset, and RAVDESS (open-access). The proposed model is also compared to baseline systems. Experimental results demonstrate that the novel proposed CapsNet model trains faster and provides better results over current state-of-the-art schemes. The effect of the routing algorithm on speaker identification performance was also studied by varying the number of iterations, both with and without a decoder network.