 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Identification from emotional and noisy speech data using learned voice segregation and Speech VGG
Oct 23, 2022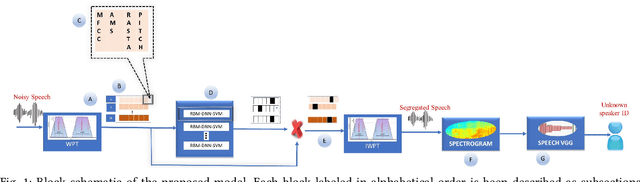
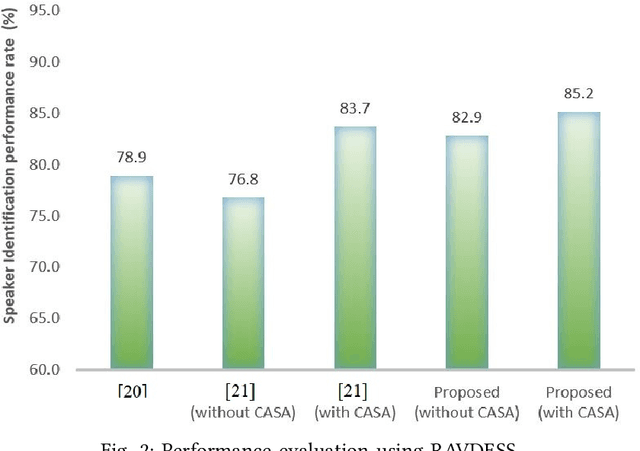
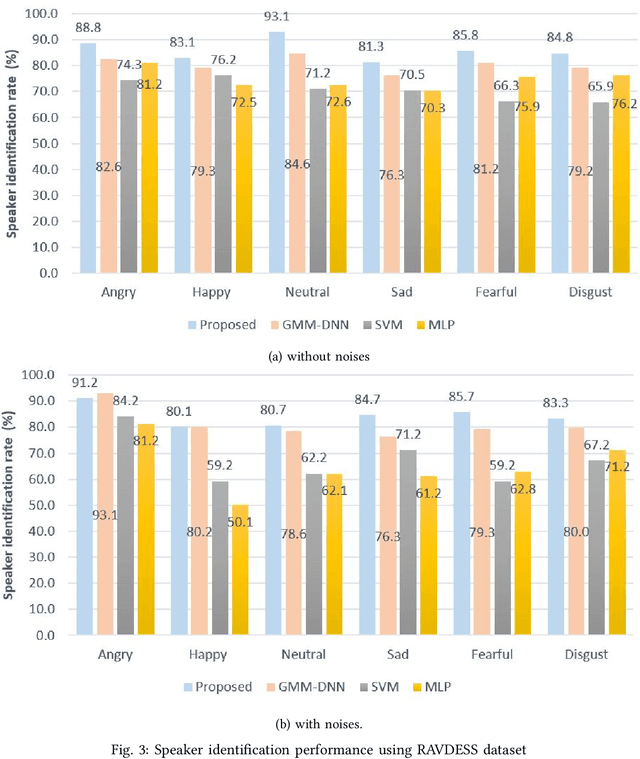
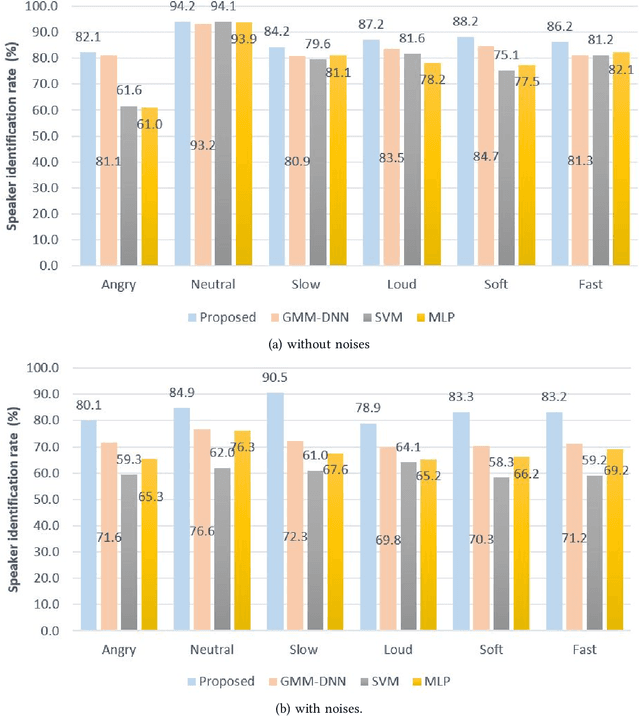
Speech signals are subjected to more acoustic interference and emotional factors than other signals. Noisy emotion-riddled speech data is a challenge for real-time speech processing applications. It is essential to find an effective way to segregate the dominant signal from other external influences. An ideal system should have the capacity to accurately recognize required auditory events from a complex scene taken in an unfavorable situation. This paper proposes a novel approach to speaker identification in unfavorable conditions such as emotion and interference using a pre-trained Deep Neural Network mask and speech VGG. The proposed model obtained superior performance over the recent literature in English and Arabic emotional speech data and reported an average speaker identification rate of 85.2\%, 87.0\%, and 86.6\% using the Ryerson audio-visual dataset (RAVDESS), speech under simulated and actual stress (SUSAS) dataset and Emirati-accented Speech dataset (ESD) respectively.
Emotional Speaker Identification using a Novel Capsule Nets Model
Jan 09, 2022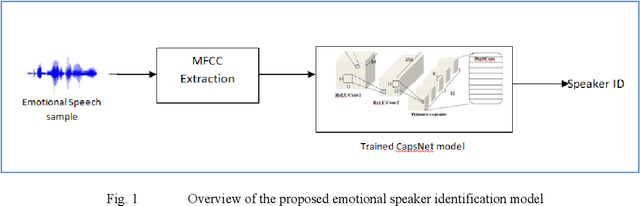

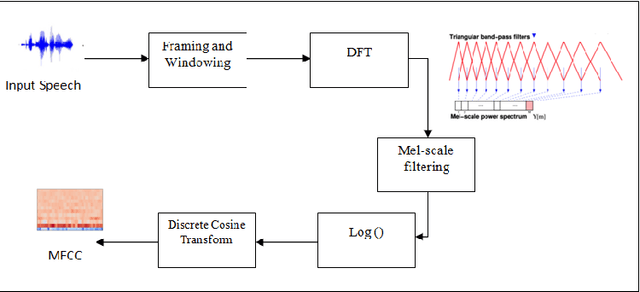
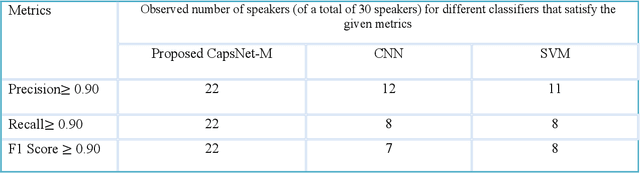
Speaker recognition systems are widely used in various applications to identify a person by their voice; however, the high degree of variability in speech signals makes this a challenging task. Dealing with emotional variations is very difficult because emotions alter the voice characteristics of a person; thus, the acoustic features differ from those used to train models in a neutral environment. Therefore, speaker recognition models trained on neutral speech fail to correctly identify speakers under emotional stress. Although considerable advancements in speaker identification have been made using convolutional neural networks (CNN), CNNs cannot exploit the spatial association between low-level features. Inspired by the recent introduction of capsule networks (CapsNets), which are based on deep learning to overcome the inadequacy of CNNs in preserving the pose relationship between low-level features with their pooling technique, this study investigates the performance of using CapsNets in identifying speakers from emotional speech recordings. A CapsNet-based speaker identification model is proposed and evaluated using three distinct speech databases, i.e., the Emirati Speech Database, SUSAS Dataset, and RAVDESS (open-access). The proposed model is also compared to baseline systems. Experimental results demonstrate that the novel proposed CapsNet model trains faster and provides better results over current state-of-the-art schemes. The effect of the routing algorithm on speaker identification performance was also studied by varying the number of iterations, both with and without a decoder network.
Novel Hybrid DNN Approaches for Speaker Verification in Emotional and Stressful Talking Environments
Dec 26, 2021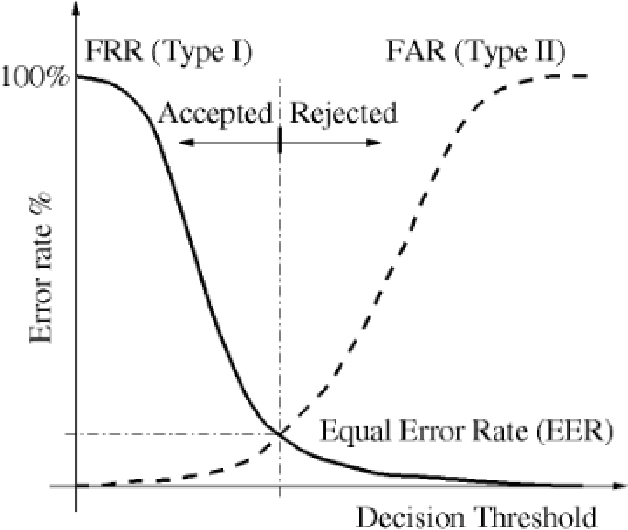
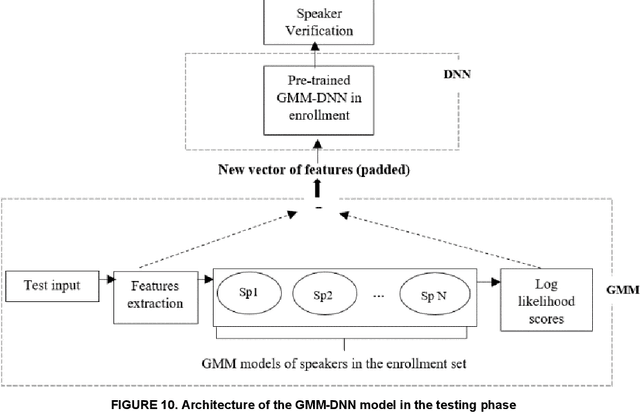
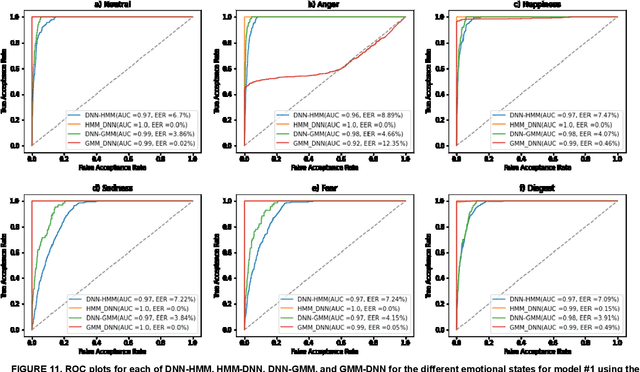
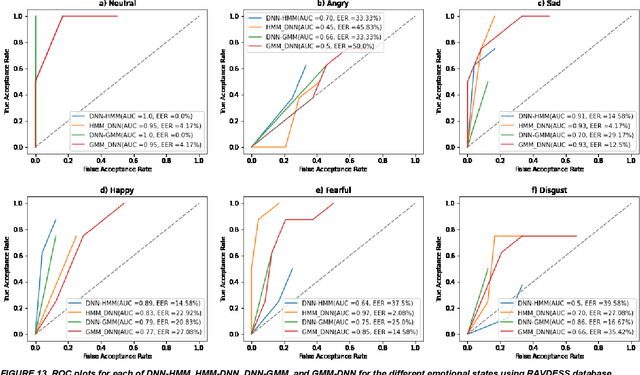
In this work, we conducted an empirical comparative study of the performance of text-independent speaker verification in emotional and stressful environments. This work combined deep models with shallow architecture, which resulted in novel hybrid classifiers. Four distinct hybrid models were utilized: deep neural network-hidden Markov model (DNN-HMM), deep neural network-Gaussian mixture model (DNN-GMM), Gaussian mixture model-deep neural network (GMM-DNN), and hidden Markov model-deep neural network (HMM-DNN). All models were based on novel implemented architecture. The comparative study used three distinct speech datasets: a private Arabic dataset and two public English databases, namely, Speech Under Simulated and Actual Stress (SUSAS) and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). The test results of the aforementioned hybrid models demonstrated that the proposed HMM-DNN leveraged the verification performance in emotional and stressful environments. Results also showed that HMM-DNN outperformed all other hybrid models in terms of equal error rate (EER) and area under the curve (AUC) evaluation metrics. The average resulting verification system based on the three datasets yielded EERs of 7.19%, 16.85%, 11.51%, and 11.90% based on HMM-DNN, DNN-HMM, DNN-GMM, and GMM-DNN, respectively. Furthermore, we found that the DNN-GMM model demonstrated the least computational complexity compared to all other hybrid models in both talking environments. Conversely, the HMM-DNN model required the greatest amount of training time. Findings also demonstrated that EER and AUC values depended on the database when comparing average emotional and stressful performances.
* 23 pages, 13 figures
Novel Dual-Channel Long Short-Term Memory Compressed Capsule Networks for Emotion Recognition
Dec 26, 2021
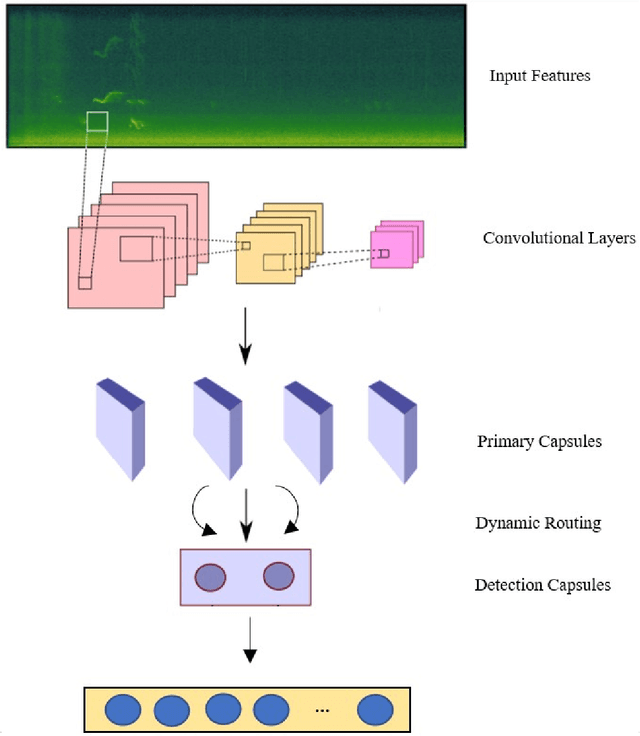
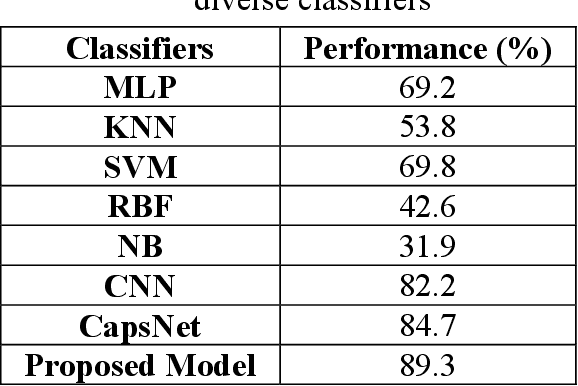
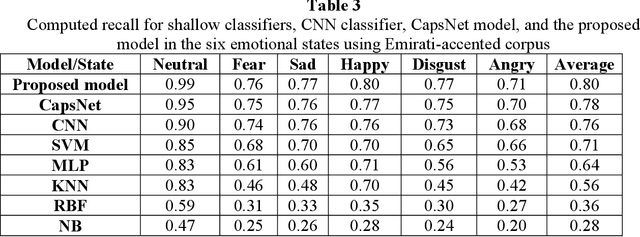
Recent analysis on speech emotion recognition has made considerable advances with the use of MFCCs spectrogram features and the implementation of neural network approaches such as convolutional neural networks (CNNs). Capsule networks (CapsNet) have gained gratitude as alternatives to CNNs with their larger capacities for hierarchical representation. To address these issues, this research introduces a text-independent and speaker-independent SER novel architecture, where a dual-channel long short-term memory compressed-CapsNet (DC-LSTM COMP-CapsNet) algorithm is proposed based on the structural features of CapsNet. Our proposed novel classifier can ensure the energy efficiency of the model and adequate compression method in speech emotion recognition, which is not delivered through the original structure of a CapsNet. Moreover, the grid search approach is used to attain optimal solutions. Results witnessed an improved performance and reduction in the training and testing running time. The speech datasets used to evaluate our algorithm are: Arabic Emirati-accented corpus, English speech under simulated and actual stress corpus, English Ryerson audio-visual database of emotional speech and song corpus, and crowd-sourced emotional multimodal actors dataset. This work reveals that the optimum feature extraction method compared to other known methods is MFCCs delta-delta. Using the four datasets and the MFCCs delta-delta, DC-LSTM COMP-CapsNet surpasses all the state-of-the-art systems, classical classifiers, CNN, and the original CapsNet. Using the Arabic Emirati-accented corpus, our results demonstrate that the proposed work yields average emotion recognition accuracy of 89.3% compared to 84.7%, 82.2%, 69.8%, 69.2%, 53.8%, 42.6%, and 31.9% based on CapsNet, CNN, support vector machine, multi-layer perceptron, k-nearest neighbor, radial basis function, and naive Bayes, respectively.
* 19 pages, 11 figures
COVID-19 Electrocardiograms Classification using CNN Models
Dec 15, 2021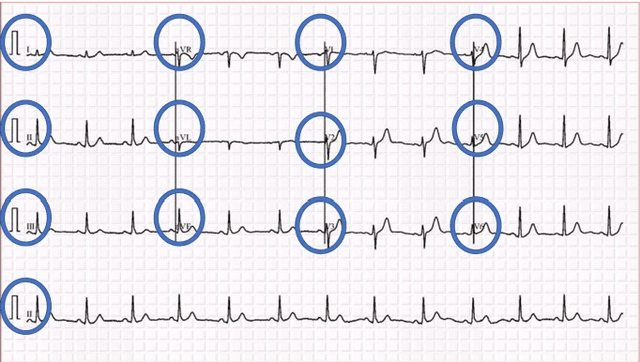
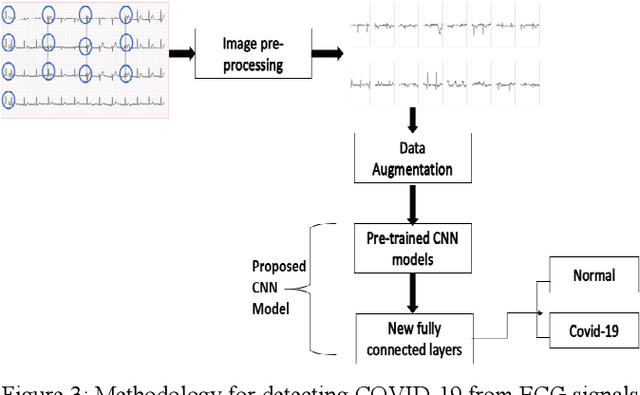
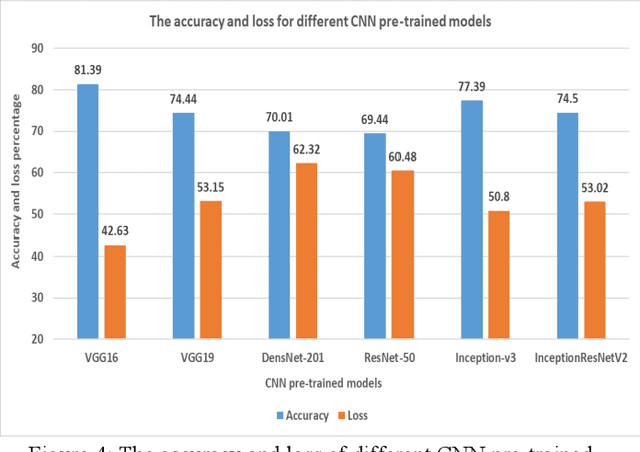
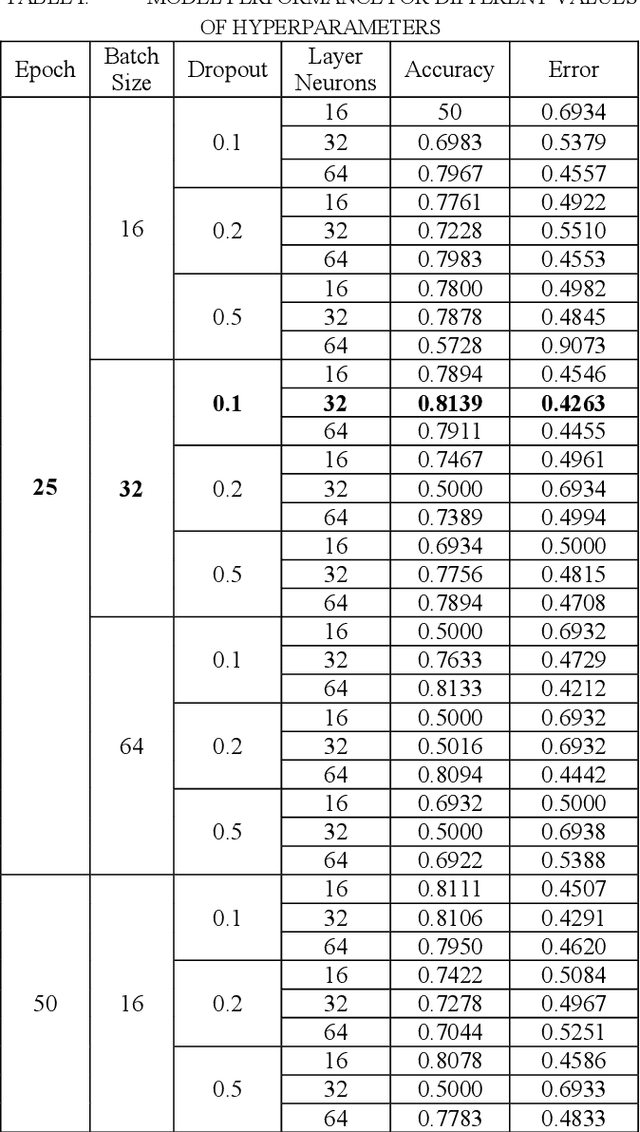
With the periodic rise and fall of COVID-19 and numerous countries being affected by its ramifications, there has been a tremendous amount of work that has been done by scientists, researchers, and doctors all over the world. Prompt intervention is keenly needed to tackle the unconscionable dissemination of the disease. The implementation of Artificial Intelligence (AI) has made a significant contribution to the digital health district by applying the fundamentals of deep learning algorithms. In this study, a novel approach is proposed to automatically diagnose the COVID-19 by the utilization of Electrocardiogram (ECG) data with the integration of deep learning algorithms, specifically the Convolutional Neural Network (CNN) models. Several CNN models have been utilized in this proposed framework, including VGG16, VGG19, InceptionResnetv2, InceptionV3, Resnet50, and Densenet201. The VGG16 model has outperformed the rest of the models, with an accuracy of 85.92%. Our results show a relatively low accuracy in the rest of the models compared to the VGG16 model, which is due to the small size of the utilized dataset, in addition to the exclusive utilization of the Grid search hyperparameters optimization approach for the VGG16 model only. Moreover, our results are preparatory, and there is a possibility to enhance the accuracy of all models by further expanding the dataset and adapting a suitable hyperparameters optimization technique.
The exploitation of Multiple Feature Extraction Techniques for Speaker Identification in Emotional States under Disguised Voices
Dec 15, 2021

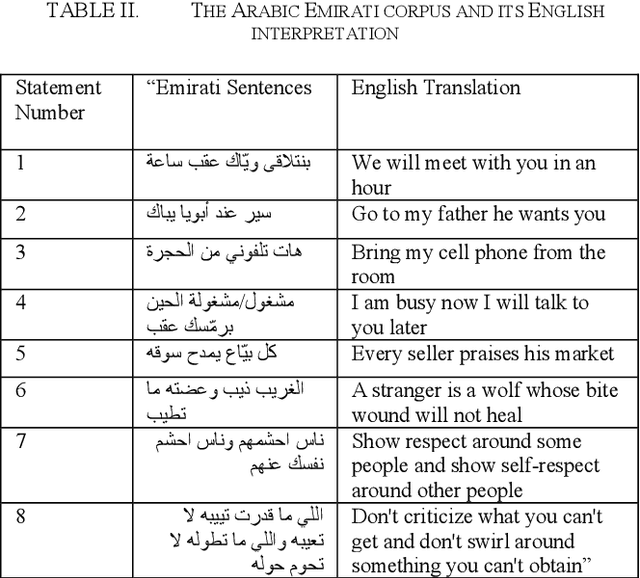
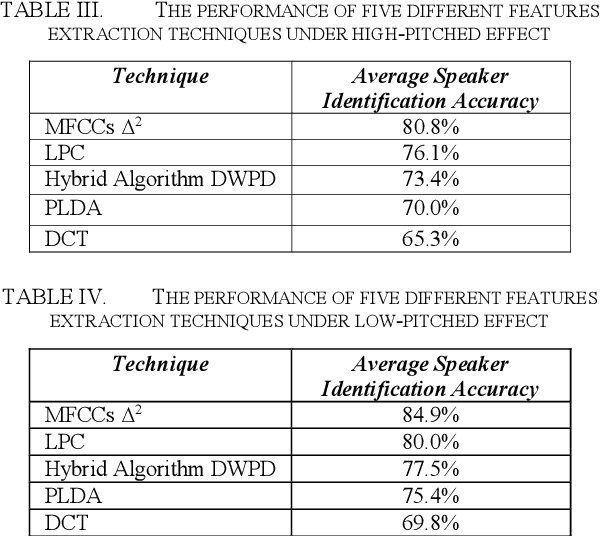
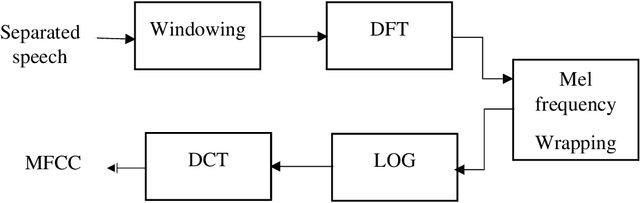
Due to improvements in artificial intelligence, speaker identification (SI) technologies have brought a great direction and are now widely used in a variety of sectors. One of the most important components of SI is feature extraction, which has a substantial impact on the SI process and performance. As a result, numerous feature extraction strategies are thoroughly investigated, contrasted, and analyzed. This article exploits five distinct feature extraction methods for speaker identification in disguised voices under emotional environments. To evaluate this work significantly, three effects are used: high-pitched, low-pitched, and Electronic Voice Conversion (EVC). Experimental results reported that the concatenated Mel-Frequency Cepstral Coefficients (MFCCs), MFCCs-delta, and MFCCs-delta-delta is the best feature extraction method.
CASA-Based Speaker Identification Using Cascaded GMM-CNN Classifier in Noisy and Emotional Talking Conditions
Feb 11, 2021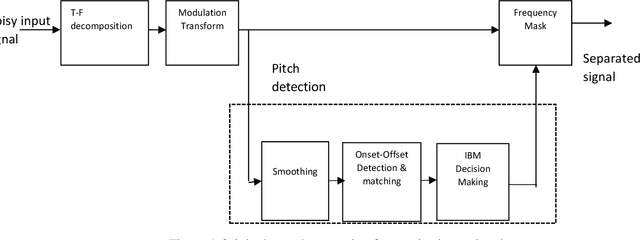
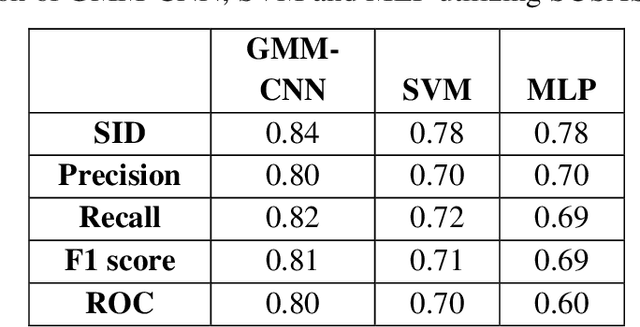
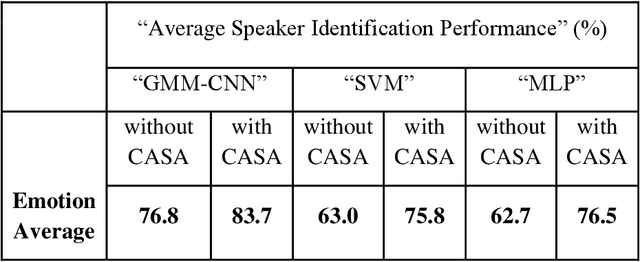
This work aims at intensifying text-independent speaker identification performance in real application situations such as noisy and emotional talking conditions. This is achieved by incorporating two different modules: a Computational Auditory Scene Analysis CASA based pre-processing module for noise reduction and cascaded Gaussian Mixture Model Convolutional Neural Network GMM-CNN classifier for speaker identification followed by emotion recognition. This research proposes and evaluates a novel algorithm to improve the accuracy of speaker identification in emotional and highly-noise susceptible conditions. Experiments demonstrate that the proposed model yields promising results in comparison with other classifiers when Speech Under Simulated and Actual Stress SUSAS database, Emirati Speech Database ESD, the Ryerson Audio-Visual Database of Emotional Speech and Song RAVDESS database and the Fluent Speech Commands database are used in a noisy environment.
* Published in Applied Soft Computing journal
Studying the Similarity of COVID-19 Sounds based on Correlation Analysis of MFCC
Oct 17, 2020
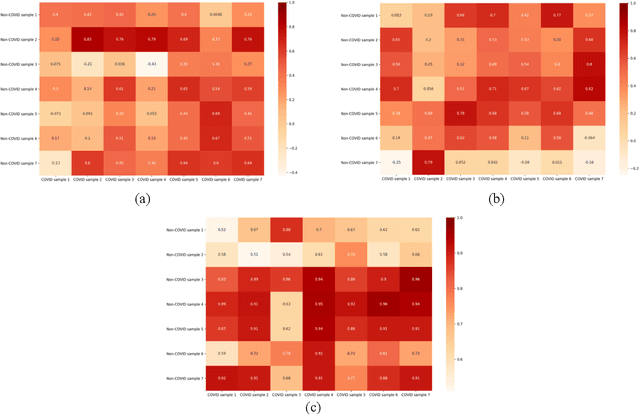

Recently there has been a formidable work which has been put up from the people who are working in the frontlines such as hospitals, clinics, and labs alongside researchers and scientists who are also putting tremendous efforts in the fight against COVID-19 pandemic. Due to the preposterous spread of the virus, the integration of the artificial intelligence has taken a considerable part in the health sector, by implementing the fundamentals of Automatic Speech Recognition (ASR) and deep learning algorithms. In this paper, we illustrate the importance of speech signal processing in the extraction of the Mel-Frequency Cepstral Coefficients (MFCCs) of the COVID-19 and non-COVID-19 samples and find their relationship using Pearson correlation coefficients. Our results show high similarity in MFCCs between different COVID-19 cough and breathing sounds, while MFCC of voice is more robust between COVID-19 and non-COVID-19 samples. Moreover, our results are preliminary, and there is a possibility to exclude the voices of COVID-19 patients from further processing in diagnosing the disease.
Emotion Recognition Using Speaker Cues
Feb 04, 2020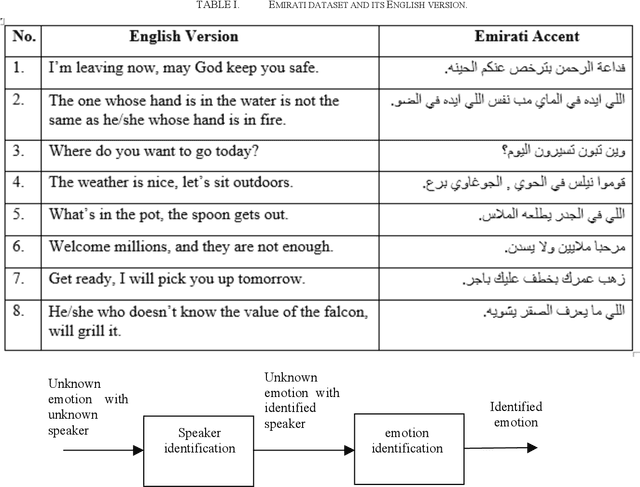
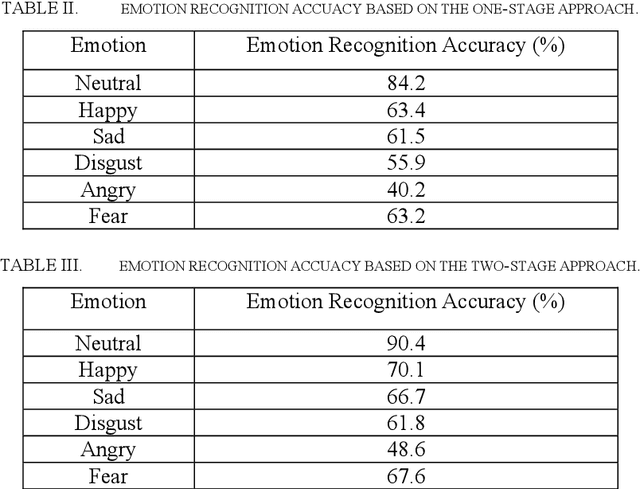
This research aims at identifying the unknown emotion using speaker cues. In this study, we identify the unknown emotion using a two-stage framework. The first stage focuses on identifying the speaker who uttered the unknown emotion, while the next stage focuses on identifying the unknown emotion uttered by the recognized speaker in the prior stage. This proposed framework has been evaluated on an Arabic Emirati-accented speech database uttered by fifteen speakers per gender. Mel-Frequency Cepstral Coefficients (MFCCs) have been used as the extracted features and Hidden Markov Model (HMM) has been utilized as the classifier in this work. Our findings demonstrate that emotion recognition accuracy based on the two-stage framework is greater than that based on the one-stage approach and the state-of-the-art classifiers and models such as Gaussian Mixture Model (GMM), Support Vector Machine (SVM), and Vector Quantization (VQ). The average emotion recognition accuracy based on the two-stage approach is 67.5%, while the accuracy reaches to 61.4%, 63.3%, 64.5%, and 61.5%, based on the one-stage approach, GMM, SVM, and VQ, respectively. The achieved results based on the two-stage framework are very close to those attained in subjective assessment by human listeners.
Emirati-Accented Speaker Identification in Stressful Talking Conditions
Oct 29, 2019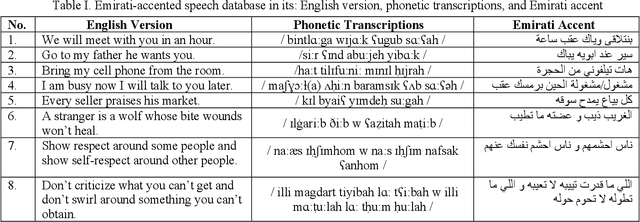
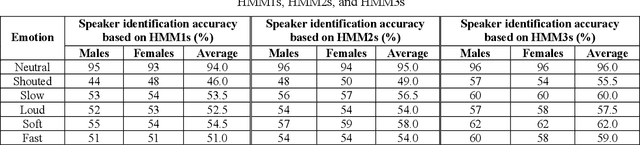
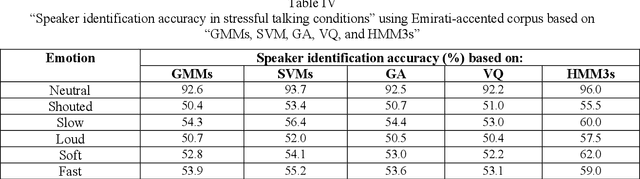
This research is dedicated to improving text-independent Emirati-accented speaker identification performance in stressful talking conditions using three distinct classifiers: First-Order Hidden Markov Models (HMM1s), Second-Order Hidden Markov Models (HMM2s), and Third-Order Hidden Markov Models (HMM3s). The database that has been used in this work was collected from 25 per gender Emirati native speakers uttering eight widespread Emirati sentences in each of neutral, shouted, slow, loud, soft, and fast talking conditions. The extracted features of the captured database are called Mel-Frequency Cepstral Coefficients (MFCCs). Based on HMM1s, HMM2s, and HMM3s, average Emirati-accented speaker identification accuracy in stressful conditions is 58.6%, 61.1%, and 65.0%, respectively. The achieved average speaker identification accuracy in stressful conditions based on HMM3s is so similar to that attained in subjective assessment by human listeners.