 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Features for Recognizing Human Activities through Optimized Parameters in Graph Convolutional Networks and Transformer Architectures
Aug 29, 2024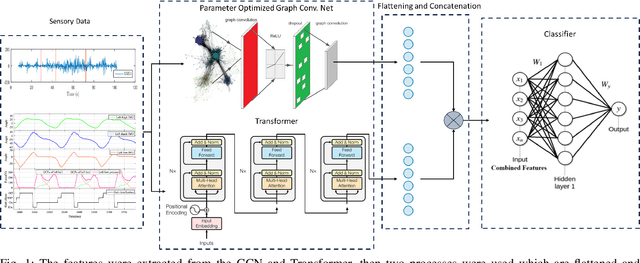
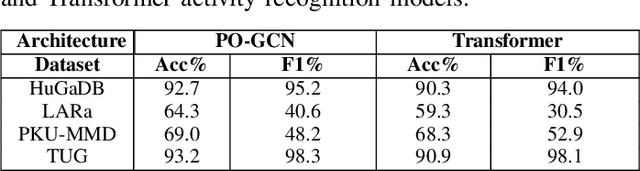
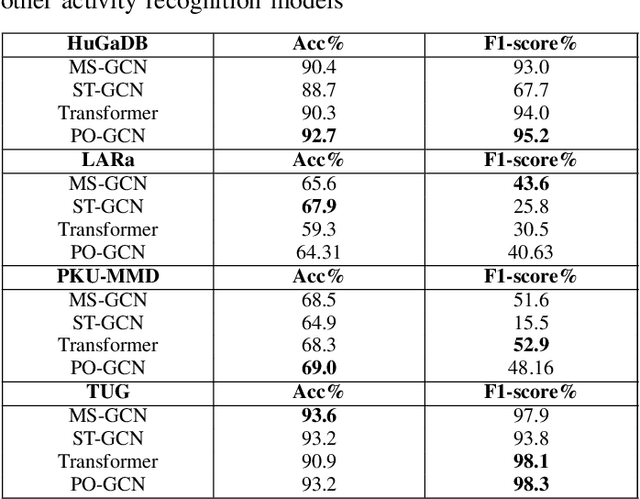

Human activity recognition is a major field of study that employs computer vision, machine vision, and deep learning techniques to categorize human actions. The field of deep learning has made significant progress, with architectures that are extremely effective at capturing human dynamics. This study emphasizes the influence of feature fusion on the accuracy of activity recognition. This technique addresses the limitation of conventional models, which face difficulties in identifying activities because of their limited capacity to understand spatial and temporal features. The technique employs sensory data obtained from four publicly available datasets: HuGaDB, PKU-MMD, LARa, and TUG. The accuracy and F1-score of two deep learning models, specifically a Transformer model and a Parameter-Optimized Graph Convolutional Network (PO-GCN), were evaluated using these datasets. The feature fusion technique integrated the final layer features from both models and inputted them into a classifier. Empirical evidence demonstrates that PO-GCN outperforms standard models in activity recognition. HuGaDB demonstrated a 2.3% improvement in accuracy and a 2.2% increase in F1-score. TUG showed a 5% increase in accuracy and a 0.5% rise in F1-score. On the other hand, LARa and PKU-MMD achieved lower accuracies of 64% and 69% respectively. This indicates that the integration of features enhanced the performance of both the Transformer model and PO-GCN.
Studying the Similarity of COVID-19 Sounds based on Correlation Analysis of MFCC
Oct 17, 2020
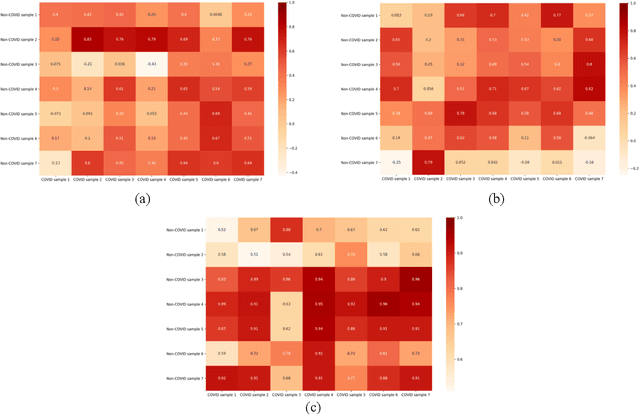

Recently there has been a formidable work which has been put up from the people who are working in the frontlines such as hospitals, clinics, and labs alongside researchers and scientists who are also putting tremendous efforts in the fight against COVID-19 pandemic. Due to the preposterous spread of the virus, the integration of the artificial intelligence has taken a considerable part in the health sector, by implementing the fundamentals of Automatic Speech Recognition (ASR) and deep learning algorithms. In this paper, we illustrate the importance of speech signal processing in the extraction of the Mel-Frequency Cepstral Coefficients (MFCCs) of the COVID-19 and non-COVID-19 samples and find their relationship using Pearson correlation coefficients. Our results show high similarity in MFCCs between different COVID-19 cough and breathing sounds, while MFCC of voice is more robust between COVID-19 and non-COVID-19 samples. Moreover, our results are preliminary, and there is a possibility to exclude the voices of COVID-19 patients from further processing in diagnosing the disease.