 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Harmful Meme Detection under Missing Modalities via Shared Representation Learning
Feb 01, 2026Internet memes are powerful tools for communication, capable of spreading political, psychological, and sociocultural ideas. However, they can be harmful and can be used to disseminate hate toward targeted individuals or groups. Although previous studies have focused on designing new detection methods, these often rely on modal-complete data, such as text and images. In real-world settings, however, modalities like text may be missing due to issues like poor OCR quality, making existing methods sensitive to missing information and leading to performance deterioration. To address this gap, in this paper, we present the first-of-its-kind work to comprehensively investigate the behavior of harmful meme detection methods in the presence of modal-incomplete data. Specifically, we propose a new baseline method that learns a shared representation for multiple modalities by projecting them independently. These shared representations can then be leveraged when data is modal-incomplete. Experimental results on two benchmark datasets demonstrate that our method outperforms existing approaches when text is missing. Moreover, these results suggest that our method allows for better integration of visual features, reducing dependence on text and improving robustness in scenarios where textual information is missing. Our work represents a significant step forward in enabling the real-world application of harmful meme detection, particularly in situations where a modality is absent.
Integrating Features for Recognizing Human Activities through Optimized Parameters in Graph Convolutional Networks and Transformer Architectures
Aug 29, 2024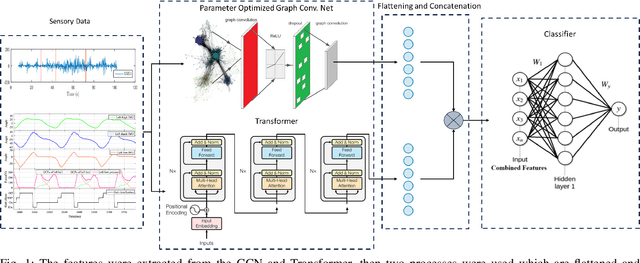
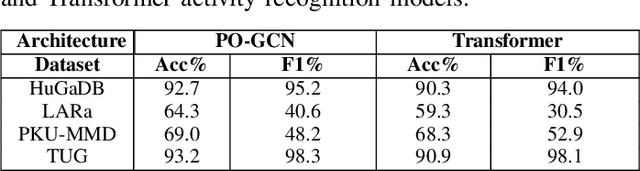
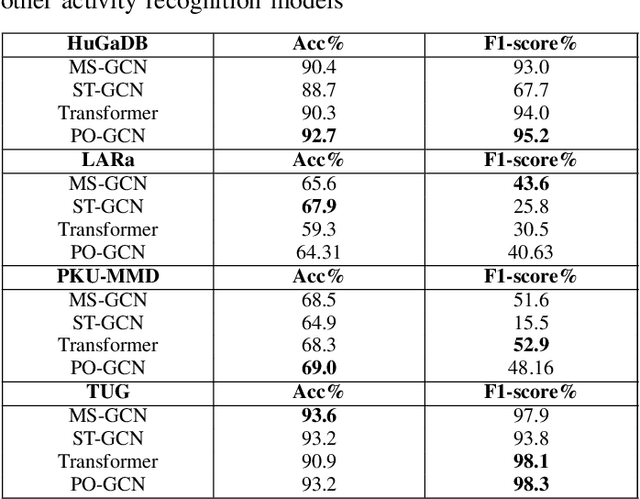

Human activity recognition is a major field of study that employs computer vision, machine vision, and deep learning techniques to categorize human actions. The field of deep learning has made significant progress, with architectures that are extremely effective at capturing human dynamics. This study emphasizes the influence of feature fusion on the accuracy of activity recognition. This technique addresses the limitation of conventional models, which face difficulties in identifying activities because of their limited capacity to understand spatial and temporal features. The technique employs sensory data obtained from four publicly available datasets: HuGaDB, PKU-MMD, LARa, and TUG. The accuracy and F1-score of two deep learning models, specifically a Transformer model and a Parameter-Optimized Graph Convolutional Network (PO-GCN), were evaluated using these datasets. The feature fusion technique integrated the final layer features from both models and inputted them into a classifier. Empirical evidence demonstrates that PO-GCN outperforms standard models in activity recognition. HuGaDB demonstrated a 2.3% improvement in accuracy and a 2.2% increase in F1-score. TUG showed a 5% increase in accuracy and a 0.5% rise in F1-score. On the other hand, LARa and PKU-MMD achieved lower accuracies of 64% and 69% respectively. This indicates that the integration of features enhanced the performance of both the Transformer model and PO-GCN.
Feature Fusion for Human Activity Recognition using Parameter-Optimized Multi-Stage Graph Convolutional Network and Transformer Models
Jun 24, 2024Human activity recognition (HAR) is a crucial area of research that involves understanding human movements using computer and machine vision technology. Deep learning has emerged as a powerful tool for this task, with models such as Convolutional Neural Networks (CNNs) and Transformers being employed to capture various aspects of human motion. One of the key contributions of this work is the demonstration of the effectiveness of feature fusion in improving HAR accuracy by capturing spatial and temporal features, which has important implications for the development of more accurate and robust activity recognition systems. The study uses sensory data from HuGaDB, PKU-MMD, LARa, and TUG datasets. Two model, the PO-MS-GCN and a Transformer were trained and evaluated, with PO-MS-GCN outperforming state-of-the-art models. HuGaDB and TUG achieved high accuracies and f1-scores, while LARa and PKU-MMD had lower scores. Feature fusion improved results across datasets.
What Sentiment and Fun Facts We Learnt Before FIFA World Cup Qatar 2022 Using Twitter and AI
Jun 28, 2023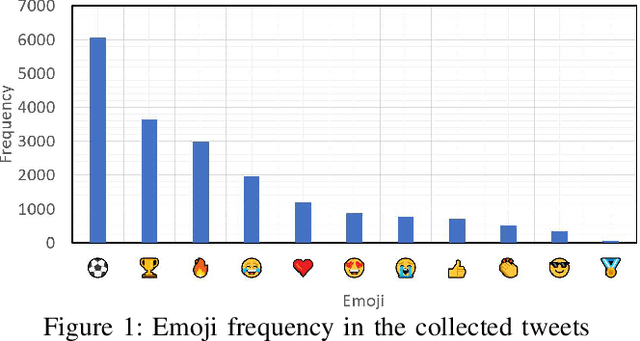


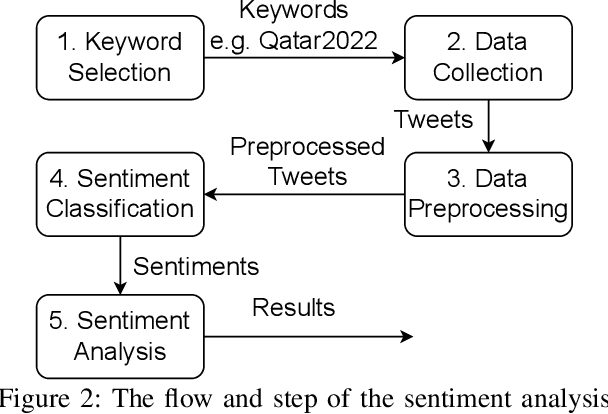
Twitter is a social media platform bridging most countries and allows real-time news discovery. Since the tweets on Twitter are usually short and express public feelings, thus provide a source for opinion mining and sentiment analysis for global events. This paper proposed an effective solution, in providing a sentiment on tweets related to the FIFA World Cup. At least 130k tweets, as the first in the community, are collected and implemented as a dataset to evaluate the performance of the proposed machine learning solution. These tweets are collected with the related hashtags and keywords of the Qatar World Cup 2022. The Vader algorithm is used in this paper for sentiment analysis. Through the machine learning method and collected Twitter tweets, we discovered the sentiments and fun facts of several aspects important to the period before the World Cup. The result shows people are positive to the opening of the World Cup.
Leveraging ChatGPT As Text Annotation Tool For Sentiment Analysis
Jun 18, 2023



Sentiment analysis is a well-known natural language processing task that involves identifying the emotional tone or polarity of a given piece of text. With the growth of social media and other online platforms, sentiment analysis has become increasingly crucial for businesses and organizations seeking to monitor and comprehend customer feedback as well as opinions. Supervised learning algorithms have been popularly employed for this task, but they require human-annotated text to create the classifier. To overcome this challenge, lexicon-based tools have been used. A drawback of lexicon-based algorithms is their reliance on pre-defined sentiment lexicons, which may not capture the full range of sentiments in natural language. ChatGPT is a new product of OpenAI and has emerged as the most popular AI product. It can answer questions on various topics and tasks. This study explores the use of ChatGPT as a tool for data labeling for different sentiment analysis tasks. It is evaluated on two distinct sentiment analysis datasets with varying purposes. The results demonstrate that ChatGPT outperforms other lexicon-based unsupervised methods with significant improvements in overall accuracy. Specifically, compared to the best-performing lexical-based algorithms, ChatGPT achieves a remarkable increase in accuracy of 20% for the tweets dataset and approximately 25% for the Amazon reviews dataset. These findings highlight the exceptional performance of ChatGPT in sentiment analysis tasks, surpassing existing lexicon-based approaches by a significant margin. The evidence suggests it can be used for annotation on different sentiment analysis events and taskss.