 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Neurocognitive Disorders through Analyses of Topic Evolution and Cross-modal Consistency in Visual-Stimulated Narratives
Jan 07, 2025



Early detection of neurocognitive disorders (NCDs) is crucial for timely intervention and disease management. Speech analysis offers a non-intrusive and scalable screening method, particularly through narrative tasks in neuropsychological assessment tools. Traditional narrative analysis often focuses on local indicators in microstructure, such as word usage and syntax. While these features provide insights into language production abilities, they often fail to capture global narrative patterns, or microstructures. Macrostructures include coherence, thematic organization, and logical progressions, reflecting essential cognitive skills potentially critical for recognizing NCDs. Addressing this gap, we propose to investigate specific cognitive and linguistic challenges by analyzing topical shifts, temporal dynamics, and the coherence of narratives over time, aiming to reveal cognitive deficits by identifying narrative impairments, and exploring their impact on communication and cognition. The investigation is based on the CU-MARVEL Rabbit Story corpus, which comprises recordings of a story-telling task from 758 older adults. We developed two approaches: the Dynamic Topic Models (DTM)-based temporal analysis to examine the evolution of topics over time, and the Text-Image Temporal Alignment Network (TITAN) to evaluate the coherence between spoken narratives and visual stimuli. DTM-based approach validated the effectiveness of dynamic topic consistency as a macrostructural metric (F1=0.61, AUC=0.78). The TITAN approach achieved the highest performance (F1=0.72, AUC=0.81), surpassing established microstructural and macrostructural feature sets. Cross-comparison and regression tasks further demonstrated the effectiveness of proposed dynamic macrostructural modeling approaches for NCD detection.
What Sentiment and Fun Facts We Learnt Before FIFA World Cup Qatar 2022 Using Twitter and AI
Jun 28, 2023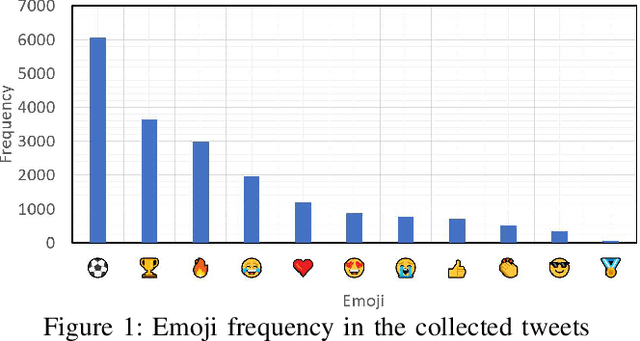


Twitter is a social media platform bridging most countries and allows real-time news discovery. Since the tweets on Twitter are usually short and express public feelings, thus provide a source for opinion mining and sentiment analysis for global events. This paper proposed an effective solution, in providing a sentiment on tweets related to the FIFA World Cup. At least 130k tweets, as the first in the community, are collected and implemented as a dataset to evaluate the performance of the proposed machine learning solution. These tweets are collected with the related hashtags and keywords of the Qatar World Cup 2022. The Vader algorithm is used in this paper for sentiment analysis. Through the machine learning method and collected Twitter tweets, we discovered the sentiments and fun facts of several aspects important to the period before the World Cup. The result shows people are positive to the opening of the World Cup.
Leveraging ChatGPT As Text Annotation Tool For Sentiment Analysis
Jun 18, 2023



Sentiment analysis is a well-known natural language processing task that involves identifying the emotional tone or polarity of a given piece of text. With the growth of social media and other online platforms, sentiment analysis has become increasingly crucial for businesses and organizations seeking to monitor and comprehend customer feedback as well as opinions. Supervised learning algorithms have been popularly employed for this task, but they require human-annotated text to create the classifier. To overcome this challenge, lexicon-based tools have been used. A drawback of lexicon-based algorithms is their reliance on pre-defined sentiment lexicons, which may not capture the full range of sentiments in natural language. ChatGPT is a new product of OpenAI and has emerged as the most popular AI product. It can answer questions on various topics and tasks. This study explores the use of ChatGPT as a tool for data labeling for different sentiment analysis tasks. It is evaluated on two distinct sentiment analysis datasets with varying purposes. The results demonstrate that ChatGPT outperforms other lexicon-based unsupervised methods with significant improvements in overall accuracy. Specifically, compared to the best-performing lexical-based algorithms, ChatGPT achieves a remarkable increase in accuracy of 20% for the tweets dataset and approximately 25% for the Amazon reviews dataset. These findings highlight the exceptional performance of ChatGPT in sentiment analysis tasks, surpassing existing lexicon-based approaches by a significant margin. The evidence suggests it can be used for annotation on different sentiment analysis events and taskss.
Dataset Culling: Towards Efficient Training Of Distillation-Based Domain Specific Models
Feb 10, 2019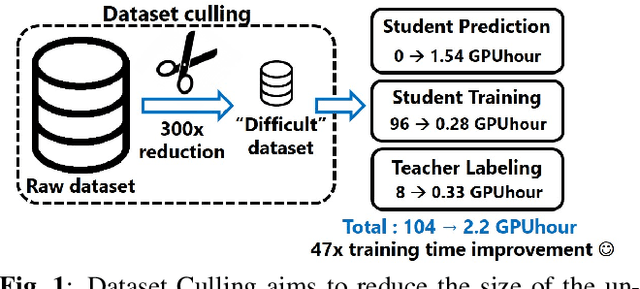
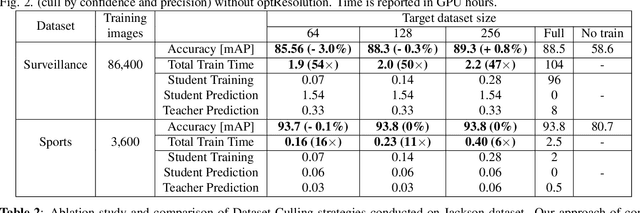
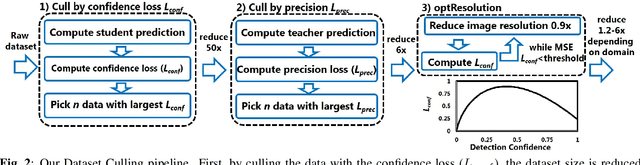
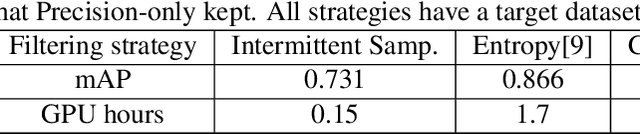
Real-time CNN-based object detection models for applications like surveillance can achieve high accuracy but are computationally expensive. Recent works have shown 10 to 100x reduction in computation cost for inference by using domain-specific networks. However, prior works have focused on inference only. If the domain model requires frequent retraining, training costs can pose a significant bottleneck. To address this, we propose Dataset Culling: a pipeline to reduce the size of the dataset for training, based on the prediction difficulty. Images that are easy to classify are filtered out since they contribute little to improving the accuracy. The difficulty is measured using our proposed confidence loss metric with little computational overhead. Dataset Culling is extended to optimize the image resolution to further improve training and inference costs. We develop fixed-angle, long-duration video datasets across several domains, and we show that Dataset Culling can reduce the training costs by 47x with no accuracy loss or even with slight improvement. Codes are available: https://github.com/kentaroy47/DatasetCulling