 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoQ: Speech Emotion Recognition via Speech-Aware Q-Former and Large Language Model
Sep 19, 2025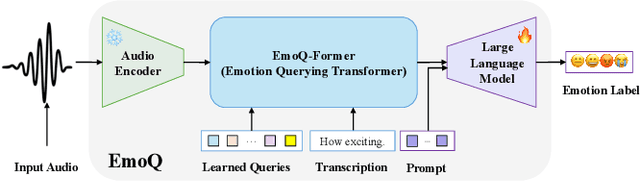
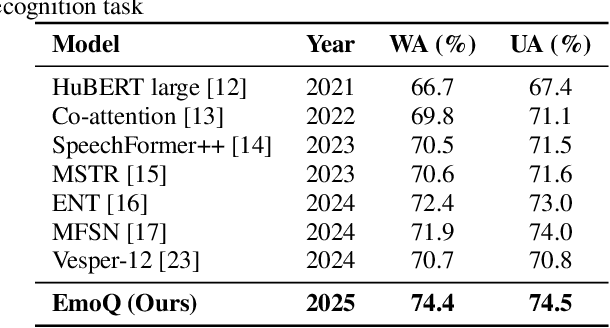
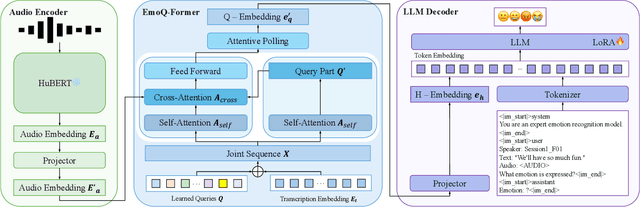
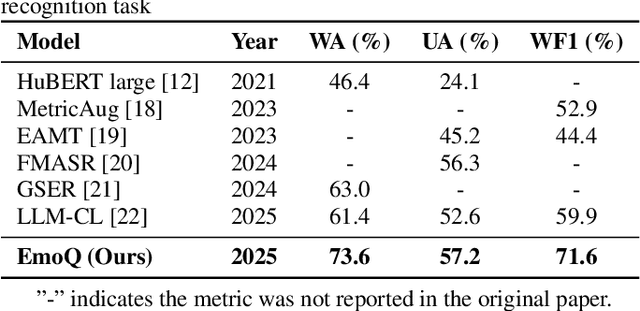
The performance of speech emotion recognition (SER) is limited by the insufficient emotion information in unimodal systems and the feature alignment difficulties in multimodal systems. Recently, multimodal large language models (MLLMs) have made progress in SER. However, MLLMs still suffer from hallucination and misclassification problems in complex emotion reasoning. To address these problems, we propose an MLLM-based framework called EmoQ, which generates query embeddings that fuse multimodal information through an EmoQ-Former and uses multi-objective affective learning (MAL) to achieve co-optimization. The framework also provides a soft-prompt injection strategy to inject multimodal representations into the LLM. This end-to-end architecture achieves state-of-the-art performance on the IEMOCAP and MELD datasets, providing a new multimodal fusion paradigm for SER.
Class Unbiasing for Generalization in Medical Diagnosis
Aug 09, 2025Medical diagnosis might fail due to bias. In this work, we identified class-feature bias, which refers to models' potential reliance on features that are strongly correlated with only a subset of classes, leading to biased performance and poor generalization on other classes. We aim to train a class-unbiased model (Cls-unbias) that mitigates both class imbalance and class-feature bias simultaneously. Specifically, we propose a class-wise inequality loss which promotes equal contributions of classification loss from positive-class and negative-class samples. We propose to optimize a class-wise group distributionally robust optimization objective-a class-weighted training objective that upweights underperforming classes-to enhance the effectiveness of the inequality loss under class imbalance. Through synthetic and real-world datasets, we empirically demonstrate that class-feature bias can negatively impact model performance. Our proposed method effectively mitigates both class-feature bias and class imbalance, thereby improving the model's generalization ability.
Subband Architecture Aided Selective Fixed-Filter Active Noise Control
Aug 01, 2025The feedforward selective fixed-filter method selects the most suitable pre-trained control filter based on the spectral features of the detected reference signal, effectively avoiding slow convergence in conventional adaptive algorithms. However, it can only handle limited types of noises, and the performance degrades when the input noise exhibits non-uniform power spectral density. To address these limitations, this paper devises a novel selective fixed-filter scheme based on a delayless subband structure. In the off-line training stage, subband control filters are pre-trained for different frequency ranges and stored in a dedicated sub-filter database. During the on-line control stage, the incoming noise is decomposed using a polyphase FFT filter bank, and a frequency-band-matching mechanism assigns each subband signal the most appropriate control filter. Subsequently, a weight stacking technique is employed to combine all subband weights into a fullband filter, enabling real-time noise suppression. Experimental results demonstrate that the proposed scheme provides fast convergence, effective noise reduction, and strong robustness in handling more complicated noisy environments.
Bayesian Learning for Domain-Invariant Speaker Verification and Anti-Spoofing
Jun 09, 2025The performance of automatic speaker verification (ASV) and anti-spoofing drops seriously under real-world domain mismatch conditions. The relaxed instance frequency-wise normalization (RFN), which normalizes the frequency components based on the feature statistics along the time and channel axes, is a promising approach to reducing the domain dependence in the feature maps of a speaker embedding network. We advocate that the different frequencies should receive different weights and that the weights' uncertainty due to domain shift should be accounted for. To these ends, we propose leveraging variational inference to model the posterior distribution of the weights, which results in Bayesian weighted RFN (BWRFN). This approach overcomes the limitations of fixed-weight RFN, making it more effective under domain mismatch conditions. Extensive experiments on cross-dataset ASV, cross-TTS anti-spoofing, and spoofing-robust ASV show that BWRFN is significantly better than WRFN and RFN.
Detecting Neurocognitive Disorders through Analyses of Topic Evolution and Cross-modal Consistency in Visual-Stimulated Narratives
Jan 07, 2025



Early detection of neurocognitive disorders (NCDs) is crucial for timely intervention and disease management. Speech analysis offers a non-intrusive and scalable screening method, particularly through narrative tasks in neuropsychological assessment tools. Traditional narrative analysis often focuses on local indicators in microstructure, such as word usage and syntax. While these features provide insights into language production abilities, they often fail to capture global narrative patterns, or microstructures. Macrostructures include coherence, thematic organization, and logical progressions, reflecting essential cognitive skills potentially critical for recognizing NCDs. Addressing this gap, we propose to investigate specific cognitive and linguistic challenges by analyzing topical shifts, temporal dynamics, and the coherence of narratives over time, aiming to reveal cognitive deficits by identifying narrative impairments, and exploring their impact on communication and cognition. The investigation is based on the CU-MARVEL Rabbit Story corpus, which comprises recordings of a story-telling task from 758 older adults. We developed two approaches: the Dynamic Topic Models (DTM)-based temporal analysis to examine the evolution of topics over time, and the Text-Image Temporal Alignment Network (TITAN) to evaluate the coherence between spoken narratives and visual stimuli. DTM-based approach validated the effectiveness of dynamic topic consistency as a macrostructural metric (F1=0.61, AUC=0.78). The TITAN approach achieved the highest performance (F1=0.72, AUC=0.81), surpassing established microstructural and macrostructural feature sets. Cross-comparison and regression tasks further demonstrated the effectiveness of proposed dynamic macrostructural modeling approaches for NCD detection.
On the effectiveness of enrollment speech augmentation for Target Speaker Extraction
Sep 15, 2024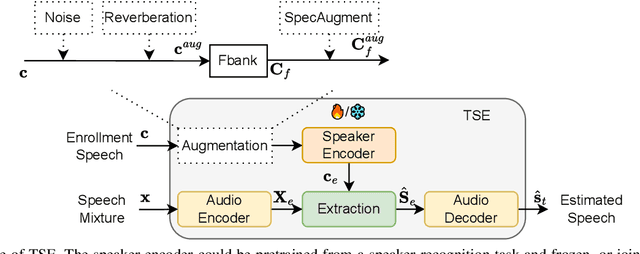
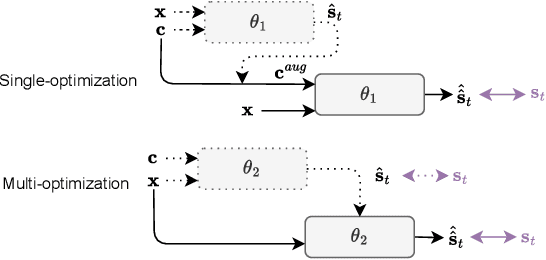
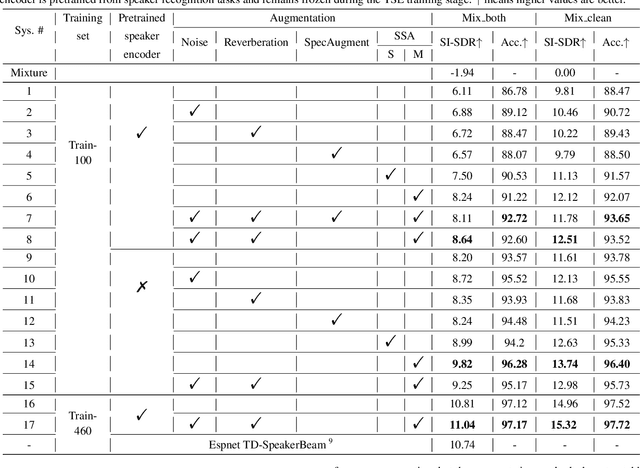
Deep learning technologies have significantly advanced the performance of target speaker extraction (TSE) tasks. To enhance the generalization and robustness of these algorithms when training data is insufficient, data augmentation is a commonly adopted technique. Unlike typical data augmentation applied to speech mixtures, this work thoroughly investigates the effectiveness of augmenting the enrollment speech space. We found that for both pretrained and jointly optimized speaker encoders, directly augmenting the enrollment speech leads to consistent performance improvement. In addition to conventional methods such as noise and reverberation addition, we propose a novel augmentation method called self-estimated speech augmentation (SSA). Experimental results on the Libri2Mix test set show that our proposed method can achieve an improvement of up to 2.5 dB.
VoxGenesis: Unsupervised Discovery of Latent Speaker Manifold for Speech Synthesis
Mar 01, 2024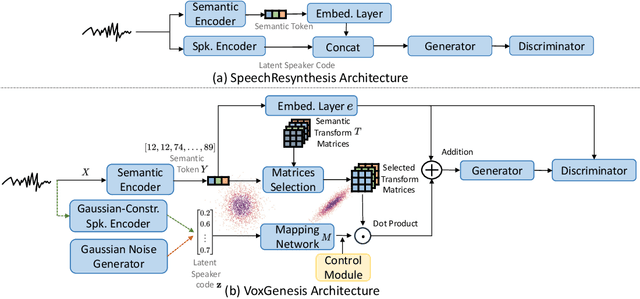
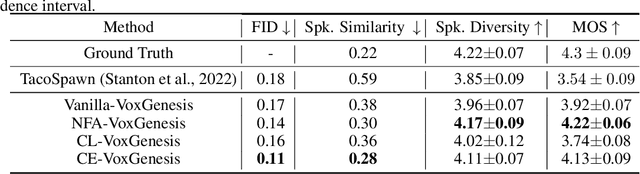
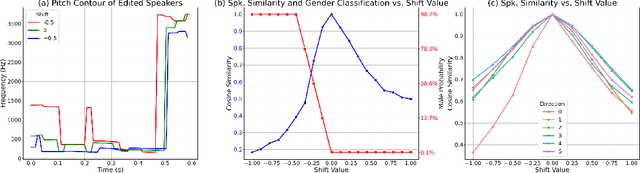

Achieving nuanced and accurate emulation of human voice has been a longstanding goal in artificial intelligence. Although significant progress has been made in recent years, the mainstream of speech synthesis models still relies on supervised speaker modeling and explicit reference utterances. However, there are many aspects of human voice, such as emotion, intonation, and speaking style, for which it is hard to obtain accurate labels. In this paper, we propose VoxGenesis, a novel unsupervised speech synthesis framework that can discover a latent speaker manifold and meaningful voice editing directions without supervision. VoxGenesis is conceptually simple. Instead of mapping speech features to waveforms deterministically, VoxGenesis transforms a Gaussian distribution into speech distributions conditioned and aligned by semantic tokens. This forces the model to learn a speaker distribution disentangled from the semantic content. During the inference, sampling from the Gaussian distribution enables the creation of novel speakers with distinct characteristics. More importantly, the exploration of latent space uncovers human-interpretable directions associated with specific speaker characteristics such as gender attributes, pitch, tone, and emotion, allowing for voice editing by manipulating the latent codes along these identified directions. We conduct extensive experiments to evaluate the proposed VoxGenesis using both subjective and objective metrics, finding that it produces significantly more diverse and realistic speakers with distinct characteristics than the previous approaches. We also show that latent space manipulation produces consistent and human-identifiable effects that are not detrimental to the speech quality, which was not possible with previous approaches. Audio samples of VoxGenesis can be found at: \url{https://bit.ly/VoxGenesis}.
Phonetic-aware speaker embedding for far-field speaker verification
Nov 27, 2023When a speaker verification (SV) system operates far from the sound sourced, significant challenges arise due to the interference of noise and reverberation. Studies have shown that incorporating phonetic information into speaker embedding can improve the performance of text-independent SV. Inspired by this observation, we propose a joint-training speech recognition and speaker recognition (JTSS) framework to exploit phonetic content for far-field SV. The framework encourages speaker embeddings to preserve phonetic information by matching the frame-based feature maps of a speaker embedding network with wav2vec's vectors. The intuition is that phonetic information can preserve low-level acoustic dynamics with speaker information and thus partly compensate for the degradation due to noise and reverberation. Results show that the proposed framework outperforms the standard speaker embedding on the VOiCES Challenge 2019 evaluation set and the VoxCeleb1 test set. This indicates that leveraging phonetic information under far-field conditions is effective for learning robust speaker representations.
Contrastive Speaker Embedding With Sequential Disentanglement
Sep 23, 2023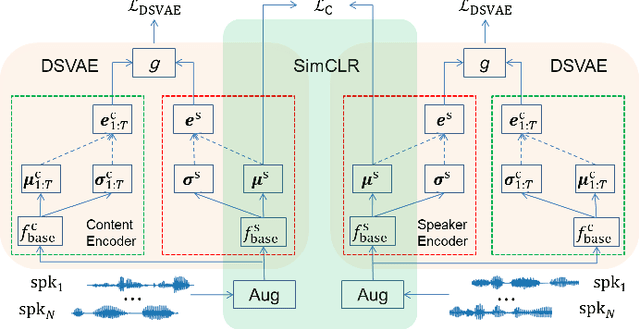
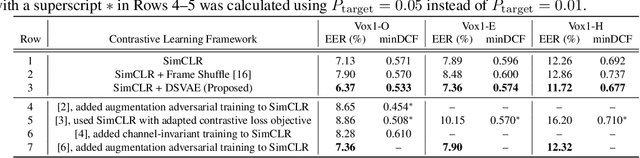
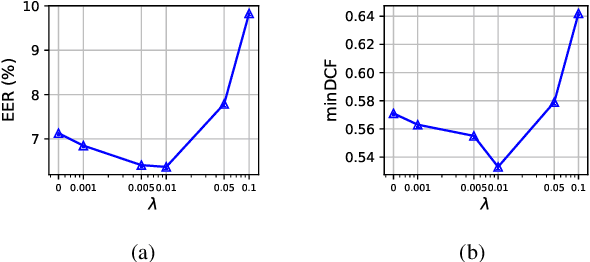
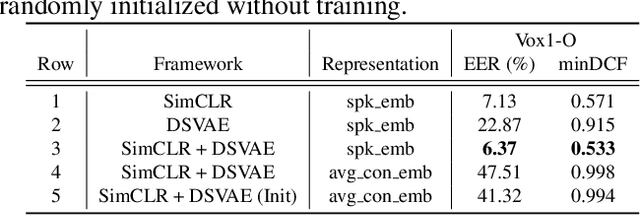
Contrastive speaker embedding assumes that the contrast between the positive and negative pairs of speech segments is attributed to speaker identity only. However, this assumption is incorrect because speech signals contain not only speaker identity but also linguistic content. In this paper, we propose a contrastive learning framework with sequential disentanglement to remove linguistic content by incorporating a disentangled sequential variational autoencoder (DSVAE) into the conventional SimCLR framework. The DSVAE aims to disentangle speaker factors from content factors in an embedding space so that only the speaker factors are used for constructing a contrastive loss objective. Because content factors have been removed from the contrastive learning, the resulting speaker embeddings will be content-invariant. Experimental results on VoxCeleb1-test show that the proposed method consistently outperforms SimCLR. This suggests that applying sequential disentanglement is beneficial to learning speaker-discriminative embeddings.
Asymmetric Clean Segments-Guided Self-Supervised Learning for Robust Speaker Verification
Sep 08, 2023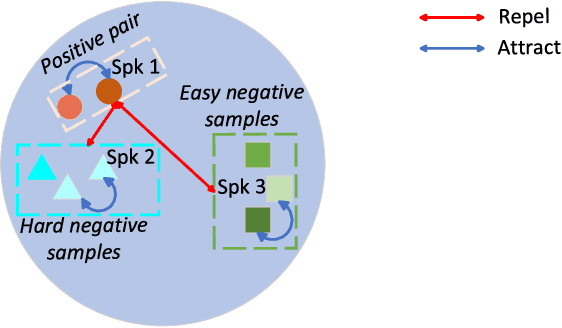
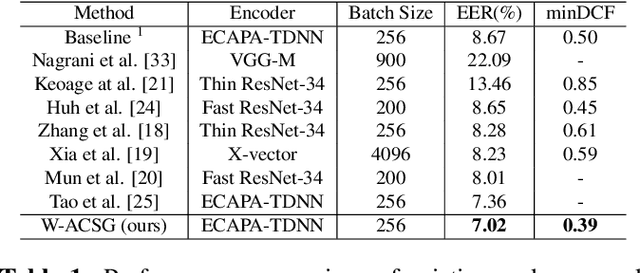
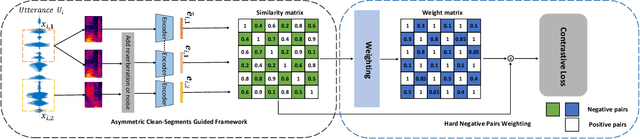

Contrastive self-supervised learning (CSL) for speaker verification (SV) has drawn increasing interest recently due to its ability to exploit unlabeled data. Performing data augmentation on raw waveforms, such as adding noise or reverberation, plays a pivotal role in achieving promising results in SV. Data augmentation, however, demands meticulous calibration to ensure intact speaker-specific information, which is difficult to achieve without speaker labels. To address this issue, we introduce a novel framework by incorporating clean and augmented segments into the contrastive training pipeline. The clean segments are repurposed to pair with noisy segments to form additional positive and negative pairs. Moreover, the contrastive loss is weighted to increase the difference between the clean and augmented embeddings of different speakers. Experimental results on Voxceleb1 suggest that the proposed framework can achieve a remarkable 19% improvement over the conventional methods, and it surpasses many existing state-of-the-art techniques.