 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Speaker Embedding With Sequential Disentanglement
Paper and Code
Sep 23, 2023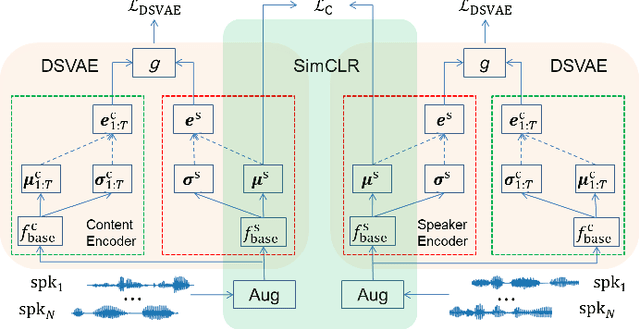
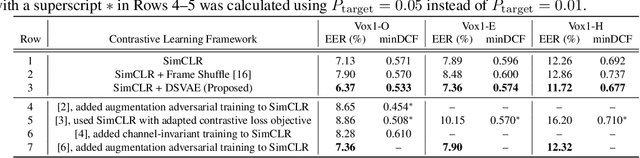
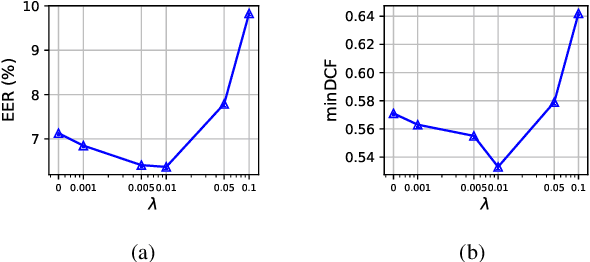
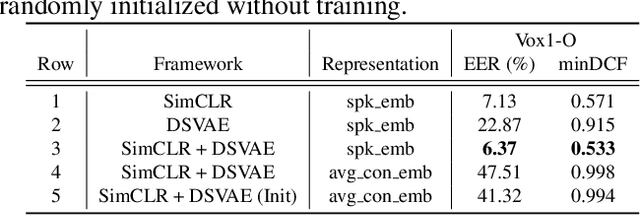
Contrastive speaker embedding assumes that the contrast between the positive and negative pairs of speech segments is attributed to speaker identity only. However, this assumption is incorrect because speech signals contain not only speaker identity but also linguistic content. In this paper, we propose a contrastive learning framework with sequential disentanglement to remove linguistic content by incorporating a disentangled sequential variational autoencoder (DSVAE) into the conventional SimCLR framework. The DSVAE aims to disentangle speaker factors from content factors in an embedding space so that only the speaker factors are used for constructing a contrastive loss objective. Because content factors have been removed from the contrastive learning, the resulting speaker embeddings will be content-invariant. Experimental results on VoxCeleb1-test show that the proposed method consistently outperforms SimCLR. This suggests that applying sequential disentanglement is beneficial to learning speaker-discriminative embeddings.