 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass Unbiasing for Generalization in Medical Diagnosis
Aug 09, 2025Medical diagnosis might fail due to bias. In this work, we identified class-feature bias, which refers to models' potential reliance on features that are strongly correlated with only a subset of classes, leading to biased performance and poor generalization on other classes. We aim to train a class-unbiased model (Cls-unbias) that mitigates both class imbalance and class-feature bias simultaneously. Specifically, we propose a class-wise inequality loss which promotes equal contributions of classification loss from positive-class and negative-class samples. We propose to optimize a class-wise group distributionally robust optimization objective-a class-weighted training objective that upweights underperforming classes-to enhance the effectiveness of the inequality loss under class imbalance. Through synthetic and real-world datasets, we empirically demonstrate that class-feature bias can negatively impact model performance. Our proposed method effectively mitigates both class-feature bias and class imbalance, thereby improving the model's generalization ability.
Phonetic-aware speaker embedding for far-field speaker verification
Nov 27, 2023When a speaker verification (SV) system operates far from the sound sourced, significant challenges arise due to the interference of noise and reverberation. Studies have shown that incorporating phonetic information into speaker embedding can improve the performance of text-independent SV. Inspired by this observation, we propose a joint-training speech recognition and speaker recognition (JTSS) framework to exploit phonetic content for far-field SV. The framework encourages speaker embeddings to preserve phonetic information by matching the frame-based feature maps of a speaker embedding network with wav2vec's vectors. The intuition is that phonetic information can preserve low-level acoustic dynamics with speaker information and thus partly compensate for the degradation due to noise and reverberation. Results show that the proposed framework outperforms the standard speaker embedding on the VOiCES Challenge 2019 evaluation set and the VoxCeleb1 test set. This indicates that leveraging phonetic information under far-field conditions is effective for learning robust speaker representations.
Contrastive Speaker Embedding With Sequential Disentanglement
Sep 23, 2023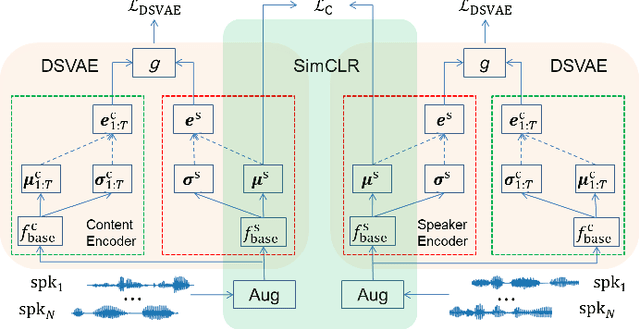
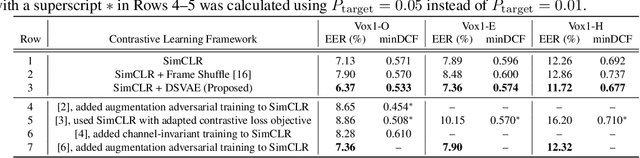
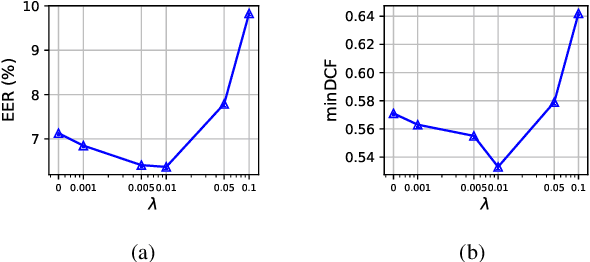
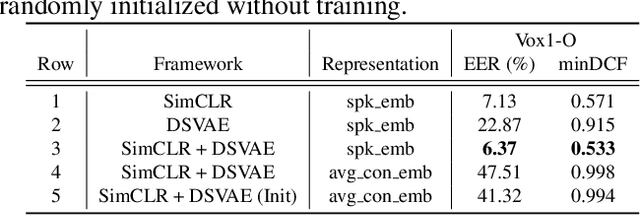
Contrastive speaker embedding assumes that the contrast between the positive and negative pairs of speech segments is attributed to speaker identity only. However, this assumption is incorrect because speech signals contain not only speaker identity but also linguistic content. In this paper, we propose a contrastive learning framework with sequential disentanglement to remove linguistic content by incorporating a disentangled sequential variational autoencoder (DSVAE) into the conventional SimCLR framework. The DSVAE aims to disentangle speaker factors from content factors in an embedding space so that only the speaker factors are used for constructing a contrastive loss objective. Because content factors have been removed from the contrastive learning, the resulting speaker embeddings will be content-invariant. Experimental results on VoxCeleb1-test show that the proposed method consistently outperforms SimCLR. This suggests that applying sequential disentanglement is beneficial to learning speaker-discriminative embeddings.
Self-supervised Neural Factor Analysis for Disentangling Utterance-level Speech Representations
May 18, 2023Self-supervised learning (SSL) speech models such as wav2vec and HuBERT have demonstrated state-of-the-art performance on automatic speech recognition (ASR) and proved to be extremely useful in low label-resource settings. However, the success of SSL models has yet to transfer to utterance-level tasks such as speaker, emotion, and language recognition, which still require supervised fine-tuning of the SSL models to obtain good performance. We argue that the problem is caused by the lack of disentangled representations and an utterance-level learning objective for these tasks. Inspired by how HuBERT uses clustering to discover hidden acoustic units, we formulate a factor analysis (FA) model that uses the discovered hidden acoustic units to align the SSL features. The underlying utterance-level representations are disentangled from the content of speech using probabilistic inference on the aligned features. Furthermore, the variational lower bound derived from the FA model provides an utterance-level objective, allowing error gradients to be backpropagated to the Transformer layers to learn highly discriminative acoustic units. When used in conjunction with HuBERT's masked prediction training, our models outperform the current best model, WavLM, on all utterance-level non-semantic tasks on the SUPERB benchmark with only 20% of labeled data.