 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePUFM++: Point Cloud Upsampling via Enhanced Flow Matching
Dec 24, 2025Recent advances in generative modeling have demonstrated strong promise for high-quality point cloud upsampling. In this work, we present PUFM++, an enhanced flow-matching framework for reconstructing dense and accurate point clouds from sparse, noisy, and partial observations. PUFM++ improves flow matching along three key axes: (i) geometric fidelity, (ii) robustness to imperfect input, and (iii) consistency with downstream surface-based tasks. We introduce a two-stage flow-matching strategy that first learns a direct, straight-path flow from sparse inputs to dense targets, and then refines it using noise-perturbed samples to approximate the terminal marginal distribution better. To accelerate and stabilize inference, we propose a data-driven adaptive time scheduler that improves sampling efficiency based on interpolation behavior. We further impose on-manifold constraints during sampling to ensure that generated points remain aligned with the underlying surface. Finally, we incorporate a recurrent interface network~(RIN) to strengthen hierarchical feature interactions and boost reconstruction quality. Extensive experiments on synthetic benchmarks and real-world scans show that PUFM++ sets a new state of the art in point cloud upsampling, delivering superior visual fidelity and quantitative accuracy across a wide range of tasks. Code and pretrained models are publicly available at https://github.com/Holmes-Alan/Enhanced_PUFM.
Efficient Point Clouds Upsampling via Flow Matching
Jan 25, 2025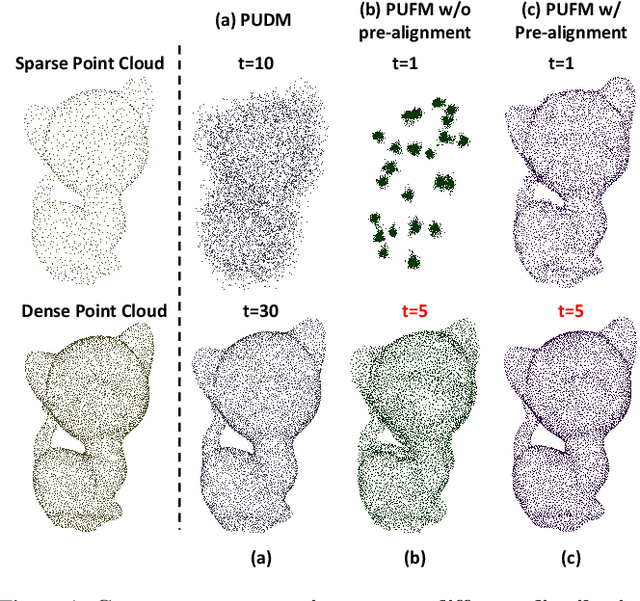
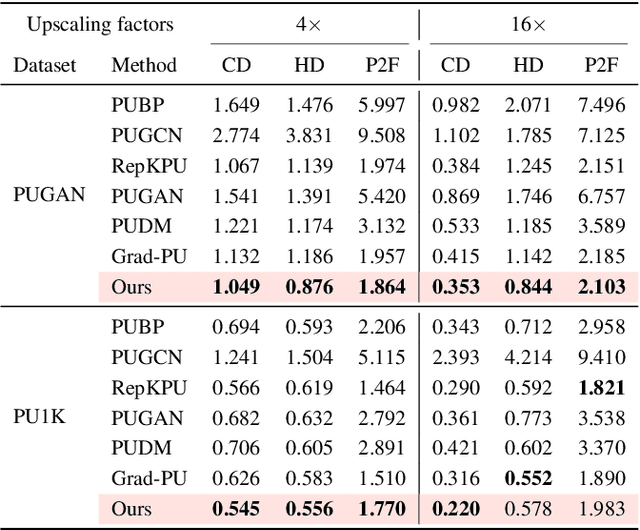
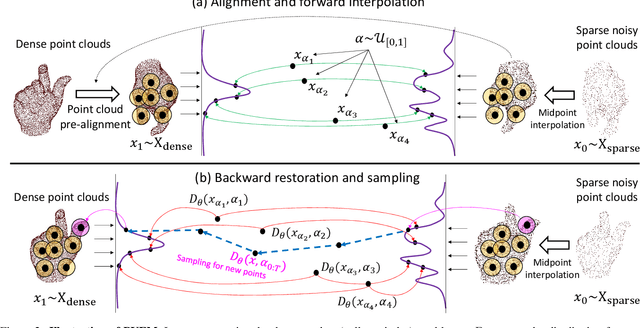
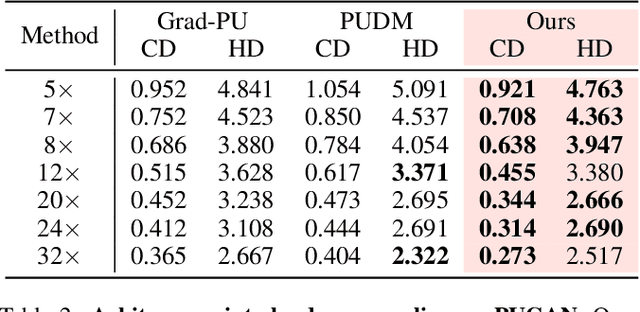
Diffusion models are a powerful framework for tackling ill-posed problems, with recent advancements extending their use to point cloud upsampling. Despite their potential, existing diffusion models struggle with inefficiencies as they map Gaussian noise to real point clouds, overlooking the geometric information inherent in sparse point clouds. To address these inefficiencies, we propose PUFM, a flow matching approach to directly map sparse point clouds to their high-fidelity dense counterparts. Our method first employs midpoint interpolation to sparse point clouds, resolving the density mismatch between sparse and dense point clouds. Since point clouds are unordered representations, we introduce a pre-alignment method based on Earth Mover's Distance (EMD) optimization to ensure coherent interpolation between sparse and dense point clouds, which enables a more stable learning path in flow matching. Experiments on synthetic datasets demonstrate that our method delivers superior upsampling quality but with fewer sampling steps. Further experiments on ScanNet and KITTI also show that our approach generalizes well on RGB-D point clouds and LiDAR point clouds, making it more practical for real-world applications.
Dense Multimodal Alignment for Open-Vocabulary 3D Scene Understanding
Jul 13, 2024



Recent vision-language pre-training models have exhibited remarkable generalization ability in zero-shot recognition tasks. Previous open-vocabulary 3D scene understanding methods mostly focus on training 3D models using either image or text supervision while neglecting the collective strength of all modalities. In this work, we propose a Dense Multimodal Alignment (DMA) framework to densely co-embed different modalities into a common space for maximizing their synergistic benefits. Instead of extracting coarse view- or region-level text prompts, we leverage large vision-language models to extract complete category information and scalable scene descriptions to build the text modality, and take image modality as the bridge to build dense point-pixel-text associations. Besides, in order to enhance the generalization ability of the 2D model for downstream 3D tasks without compromising the open-vocabulary capability, we employ a dual-path integration approach to combine frozen CLIP visual features and learnable mask features. Extensive experiments show that our DMA method produces highly competitive open-vocabulary segmentation performance on various indoor and outdoor tasks.
LAPT: Label-driven Automated Prompt Tuning for OOD Detection with Vision-Language Models
Jul 12, 2024Out-of-distribution (OOD) detection is crucial for model reliability, as it identifies samples from unknown classes and reduces errors due to unexpected inputs. Vision-Language Models (VLMs) such as CLIP are emerging as powerful tools for OOD detection by integrating multi-modal information. However, the practical application of such systems is challenged by manual prompt engineering, which demands domain expertise and is sensitive to linguistic nuances. In this paper, we introduce Label-driven Automated Prompt Tuning (LAPT), a novel approach to OOD detection that reduces the need for manual prompt engineering. We develop distribution-aware prompts with in-distribution (ID) class names and negative labels mined automatically. Training samples linked to these class labels are collected autonomously via image synthesis and retrieval methods, allowing for prompt learning without manual effort. We utilize a simple cross-entropy loss for prompt optimization, with cross-modal and cross-distribution mixing strategies to reduce image noise and explore the intermediate space between distributions, respectively. The LAPT framework operates autonomously, requiring only ID class names as input and eliminating the need for manual intervention. With extensive experiments, LAPT consistently outperforms manually crafted prompts, setting a new standard for OOD detection. Moreover, LAPT not only enhances the distinction between ID and OOD samples, but also improves the ID classification accuracy and strengthens the generalization robustness to covariate shifts, resulting in outstanding performance in challenging full-spectrum OOD detection tasks. Codes are available at \url{https://github.com/YBZh/LAPT}.
Voxel Mamba: Group-Free State Space Models for Point Cloud based 3D Object Detection
Jun 18, 2024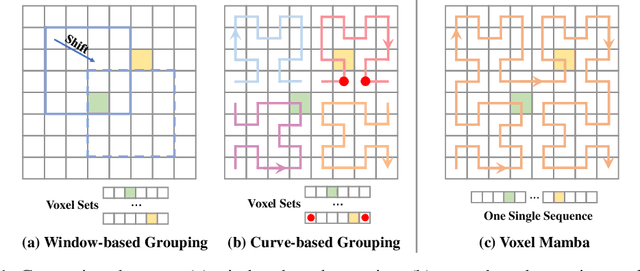
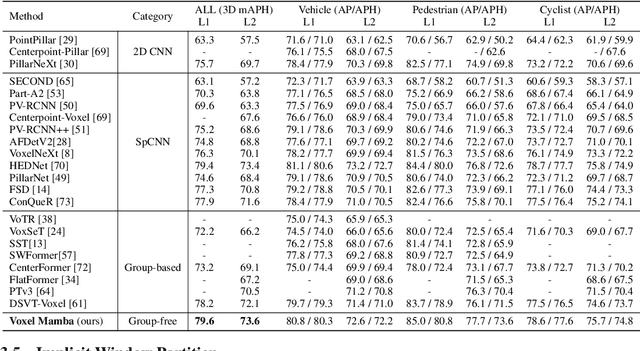
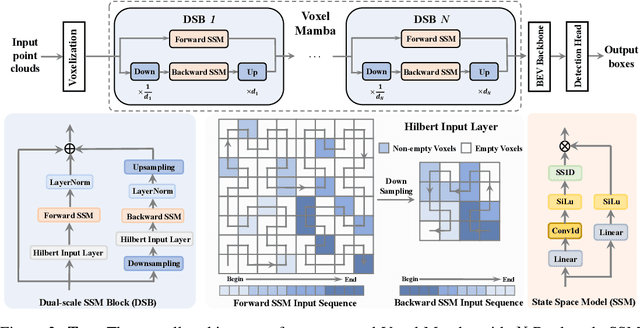
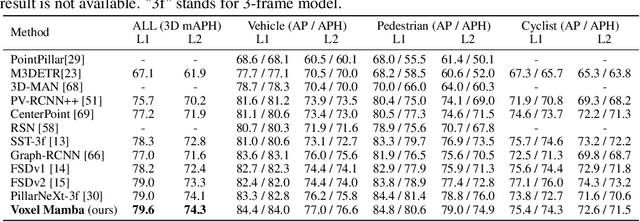
Serialization-based methods, which serialize the 3D voxels and group them into multiple sequences before inputting to Transformers, have demonstrated their effectiveness in 3D object detection. However, serializing 3D voxels into 1D sequences will inevitably sacrifice the voxel spatial proximity. Such an issue is hard to be addressed by enlarging the group size with existing serialization-based methods due to the quadratic complexity of Transformers with feature sizes. Inspired by the recent advances of state space models (SSMs), we present a Voxel SSM, termed as Voxel Mamba, which employs a group-free strategy to serialize the whole space of voxels into a single sequence. The linear complexity of SSMs encourages our group-free design, alleviating the loss of spatial proximity of voxels. To further enhance the spatial proximity, we propose a Dual-scale SSM Block to establish a hierarchical structure, enabling a larger receptive field in the 1D serialization curve, as well as more complete local regions in 3D space. Moreover, we implicitly apply window partition under the group-free framework by positional encoding, which further enhances spatial proximity by encoding voxel positional information. Our experiments on Waymo Open Dataset and nuScenes dataset show that Voxel Mamba not only achieves higher accuracy than state-of-the-art methods, but also demonstrates significant advantages in computational efficiency.
VoxGenesis: Unsupervised Discovery of Latent Speaker Manifold for Speech Synthesis
Mar 01, 2024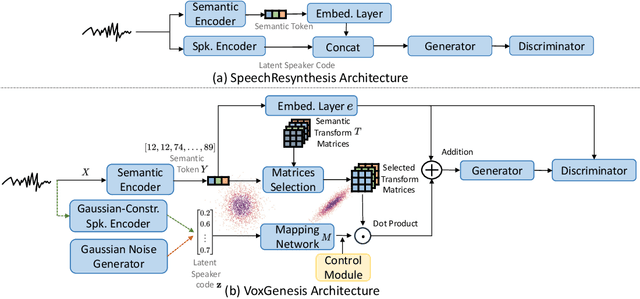
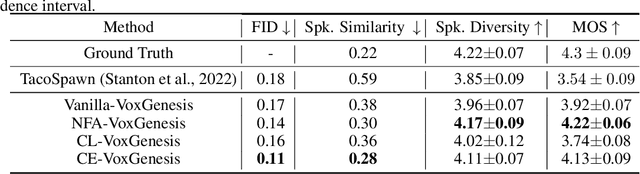
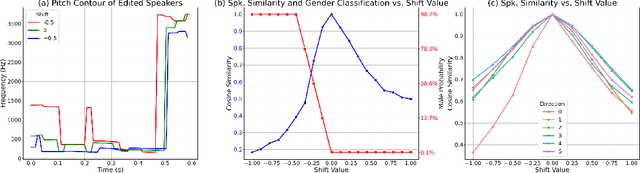

Achieving nuanced and accurate emulation of human voice has been a longstanding goal in artificial intelligence. Although significant progress has been made in recent years, the mainstream of speech synthesis models still relies on supervised speaker modeling and explicit reference utterances. However, there are many aspects of human voice, such as emotion, intonation, and speaking style, for which it is hard to obtain accurate labels. In this paper, we propose VoxGenesis, a novel unsupervised speech synthesis framework that can discover a latent speaker manifold and meaningful voice editing directions without supervision. VoxGenesis is conceptually simple. Instead of mapping speech features to waveforms deterministically, VoxGenesis transforms a Gaussian distribution into speech distributions conditioned and aligned by semantic tokens. This forces the model to learn a speaker distribution disentangled from the semantic content. During the inference, sampling from the Gaussian distribution enables the creation of novel speakers with distinct characteristics. More importantly, the exploration of latent space uncovers human-interpretable directions associated with specific speaker characteristics such as gender attributes, pitch, tone, and emotion, allowing for voice editing by manipulating the latent codes along these identified directions. We conduct extensive experiments to evaluate the proposed VoxGenesis using both subjective and objective metrics, finding that it produces significantly more diverse and realistic speakers with distinct characteristics than the previous approaches. We also show that latent space manipulation produces consistent and human-identifiable effects that are not detrimental to the speech quality, which was not possible with previous approaches. Audio samples of VoxGenesis can be found at: \url{https://bit.ly/VoxGenesis}.
ScatterFormer: Efficient Voxel Transformer with Scattered Linear Attention
Jan 01, 2024



Window-based transformers have demonstrated strong ability in large-scale point cloud understanding by capturing context-aware representations with affordable attention computation in a more localized manner. However, because of the sparse nature of point clouds, the number of voxels per window varies significantly. Current methods partition the voxels in each window into multiple subsets of equal size, which cost expensive overhead in sorting and padding the voxels, making them run slower than sparse convolution based methods. In this paper, we present ScatterFormer, which, for the first time to our best knowledge, could directly perform attention on voxel sets with variable length. The key of ScatterFormer lies in the innovative Scatter Linear Attention (SLA) module, which leverages the linear attention mechanism to process in parallel all voxels scattered in different windows. Harnessing the hierarchical computation units of the GPU and matrix blocking algorithm, we reduce the latency of the proposed SLA module to less than 1 ms on moderate GPUs. Besides, we develop a cross-window interaction module to simultaneously enhance the local representation and allow the information flow across windows, eliminating the need for window shifting. Our proposed ScatterFormer demonstrates 73 mAP (L2) on the large-scale Waymo Open Dataset and 70.5 NDS on the NuScenes dataset, running at an outstanding detection rate of 28 FPS. Code is available at https://github.com/skyhehe123/ScatterFormer
Motion-Guided Latent Diffusion for Temporally Consistent Real-world Video Super-resolution
Dec 01, 2023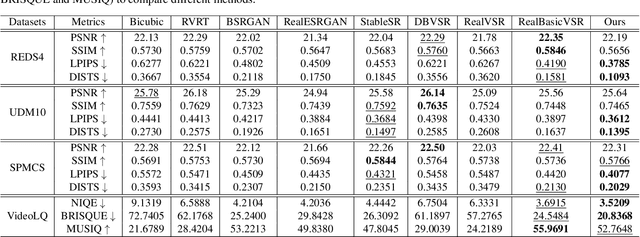
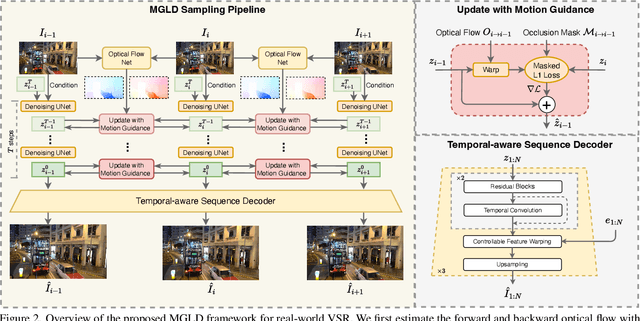


Real-world low-resolution (LR) videos have diverse and complex degradations, imposing great challenges on video super-resolution (VSR) algorithms to reproduce their high-resolution (HR) counterparts with high quality. Recently, the diffusion models have shown compelling performance in generating realistic details for image restoration tasks. However, the diffusion process has randomness, making it hard to control the contents of restored images. This issue becomes more serious when applying diffusion models to VSR tasks because temporal consistency is crucial to the perceptual quality of videos. In this paper, we propose an effective real-world VSR algorithm by leveraging the strength of pre-trained latent diffusion models. To ensure the content consistency among adjacent frames, we exploit the temporal dynamics in LR videos to guide the diffusion process by optimizing the latent sampling path with a motion-guided loss, ensuring that the generated HR video maintains a coherent and continuous visual flow. To further mitigate the discontinuity of generated details, we insert temporal module to the decoder and fine-tune it with an innovative sequence-oriented loss. The proposed motion-guided latent diffusion (MGLD) based VSR algorithm achieves significantly better perceptual quality than state-of-the-arts on real-world VSR benchmark datasets, validating the effectiveness of the proposed model design and training strategies.
Self-supervised Neural Factor Analysis for Disentangling Utterance-level Speech Representations
May 18, 2023Self-supervised learning (SSL) speech models such as wav2vec and HuBERT have demonstrated state-of-the-art performance on automatic speech recognition (ASR) and proved to be extremely useful in low label-resource settings. However, the success of SSL models has yet to transfer to utterance-level tasks such as speaker, emotion, and language recognition, which still require supervised fine-tuning of the SSL models to obtain good performance. We argue that the problem is caused by the lack of disentangled representations and an utterance-level learning objective for these tasks. Inspired by how HuBERT uses clustering to discover hidden acoustic units, we formulate a factor analysis (FA) model that uses the discovered hidden acoustic units to align the SSL features. The underlying utterance-level representations are disentangled from the content of speech using probabilistic inference on the aligned features. Furthermore, the variational lower bound derived from the FA model provides an utterance-level objective, allowing error gradients to be backpropagated to the Transformer layers to learn highly discriminative acoustic units. When used in conjunction with HuBERT's masked prediction training, our models outperform the current best model, WavLM, on all utterance-level non-semantic tasks on the SUPERB benchmark with only 20% of labeled data.
One-to-Few Label Assignment for End-to-End Dense Detection
Mar 21, 2023



One-to-one (o2o) label assignment plays a key role for transformer based end-to-end detection, and it has been recently introduced in fully convolutional detectors for end-to-end dense detection. However, o2o can degrade the feature learning efficiency due to the limited number of positive samples. Though extra positive samples are introduced to mitigate this issue in recent DETRs, the computation of self- and cross- attentions in the decoder limits its practical application to dense and fully convolutional detectors. In this work, we propose a simple yet effective one-to-few (o2f) label assignment strategy for end-to-end dense detection. Apart from defining one positive and many negative anchors for each object, we define several soft anchors, which serve as positive and negative samples simultaneously. The positive and negative weights of these soft anchors are dynamically adjusted during training so that they can contribute more to ``representation learning'' in the early training stage, and contribute more to ``duplicated prediction removal'' in the later stage. The detector trained in this way can not only learn a strong feature representation but also perform end-to-end dense detection. Experiments on COCO and CrowdHuman datasets demonstrate the effectiveness of the o2f scheme. Code is available at https://github.com/strongwolf/o2f.