 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond External Guidance: Unleashing the Semantic Richness Inside Diffusion Transformers for Improved Training
Jan 12, 2026Recent works such as REPA have shown that guiding diffusion models with external semantic features (e.g., DINO) can significantly accelerate the training of diffusion transformers (DiTs). However, this requires the use of pretrained external networks, introducing additional dependencies and reducing flexibility. In this work, we argue that DiTs actually have the power to guide the training of themselves, and propose \textbf{Self-Transcendence}, a simple yet effective method that achieves fast convergence using internal feature supervision only. It is found that the slow convergence in DiT training primarily stems from the difficulty of representation learning in shallow layers. To address this, we initially train the DiT model by aligning its shallow features with the latent representations from the pretrained VAE for a short phase (e.g., 40 epochs), then apply classifier-free guidance to the intermediate features, enhancing their discriminative capability and semantic expressiveness. These enriched internal features, learned entirely within the model, are used as supervision signals to guide a new DiT training. Compared to existing self-contained methods, our approach brings a significant performance boost. It can even surpass REPA in terms of generation quality and convergence speed, but without the need for any external pretrained models. Our method is not only more flexible for different backbones but also has the potential to be adopted for a wider range of diffusion-based generative tasks. The source code of our method can be found at https://github.com/csslc/Self-Transcendence.
DP$^2$O-SR: Direct Perceptual Preference Optimization for Real-World Image Super-Resolution
Oct 21, 2025Benefiting from pre-trained text-to-image (T2I) diffusion models, real-world image super-resolution (Real-ISR) methods can synthesize rich and realistic details. However, due to the inherent stochasticity of T2I models, different noise inputs often lead to outputs with varying perceptual quality. Although this randomness is sometimes seen as a limitation, it also introduces a wider perceptual quality range, which can be exploited to improve Real-ISR performance. To this end, we introduce Direct Perceptual Preference Optimization for Real-ISR (DP$^2$O-SR), a framework that aligns generative models with perceptual preferences without requiring costly human annotations. We construct a hybrid reward signal by combining full-reference and no-reference image quality assessment (IQA) models trained on large-scale human preference datasets. This reward encourages both structural fidelity and natural appearance. To better utilize perceptual diversity, we move beyond the standard best-vs-worst selection and construct multiple preference pairs from outputs of the same model. Our analysis reveals that the optimal selection ratio depends on model capacity: smaller models benefit from broader coverage, while larger models respond better to stronger contrast in supervision. Furthermore, we propose hierarchical preference optimization, which adaptively weights training pairs based on intra-group reward gaps and inter-group diversity, enabling more efficient and stable learning. Extensive experiments across both diffusion- and flow-based T2I backbones demonstrate that DP$^2$O-SR significantly improves perceptual quality and generalizes well to real-world benchmarks.
One-Step Diffusion for Detail-Rich and Temporally Consistent Video Super-Resolution
Jun 18, 2025

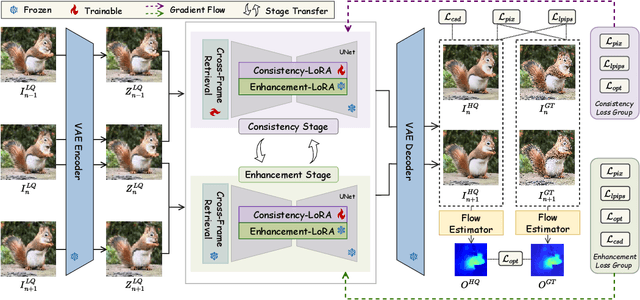

It is a challenging problem to reproduce rich spatial details while maintaining temporal consistency in real-world video super-resolution (Real-VSR), especially when we leverage pre-trained generative models such as stable diffusion (SD) for realistic details synthesis. Existing SD-based Real-VSR methods often compromise spatial details for temporal coherence, resulting in suboptimal visual quality. We argue that the key lies in how to effectively extract the degradation-robust temporal consistency priors from the low-quality (LQ) input video and enhance the video details while maintaining the extracted consistency priors. To achieve this, we propose a Dual LoRA Learning (DLoRAL) paradigm to train an effective SD-based one-step diffusion model, achieving realistic frame details and temporal consistency simultaneously. Specifically, we introduce a Cross-Frame Retrieval (CFR) module to aggregate complementary information across frames, and train a Consistency-LoRA (C-LoRA) to learn robust temporal representations from degraded inputs. After consistency learning, we fix the CFR and C-LoRA modules and train a Detail-LoRA (D-LoRA) to enhance spatial details while aligning with the temporal space defined by C-LoRA to keep temporal coherence. The two phases alternate iteratively for optimization, collaboratively delivering consistent and detail-rich outputs. During inference, the two LoRA branches are merged into the SD model, allowing efficient and high-quality video restoration in a single diffusion step. Experiments show that DLoRAL achieves strong performance in both accuracy and speed. Code and models are available at https://github.com/yjsunnn/DLoRAL.
Generalized and Efficient 2D Gaussian Splatting for Arbitrary-scale Super-Resolution
Jan 14, 2025



Equipped with the continuous representation capability of Multi-Layer Perceptron (MLP), Implicit Neural Representation (INR) has been successfully employed for Arbitrary-scale Super-Resolution (ASR). However, the limited receptive field of the linear layers in MLP restricts the representation capability of INR, while it is computationally expensive to query the MLP numerous times to render each pixel. Recently, Gaussian Splatting (GS) has shown its advantages over INR in both visual quality and rendering speed in 3D tasks, which motivates us to explore whether GS can be employed for the ASR task. However, directly applying GS to ASR is exceptionally challenging because the original GS is an optimization-based method through overfitting each single scene, while in ASR we aim to learn a single model that can generalize to different images and scaling factors. We overcome these challenges by developing two novel techniques. Firstly, to generalize GS for ASR, we elaborately design an architecture to predict the corresponding image-conditioned Gaussians of the input low-resolution image in a feed-forward manner. Secondly, we implement an efficient differentiable 2D GPU/CUDA-based scale-aware rasterization to render super-resolved images by sampling discrete RGB values from the predicted contiguous Gaussians. Via end-to-end training, our optimized network, namely GSASR, can perform ASR for any image and unseen scaling factors. Extensive experiments validate the effectiveness of our proposed method. The project page can be found at \url{https://mt-cly.github.io/GSASR.github.io/}.
FreCaS: Efficient Higher-Resolution Image Generation via Frequency-aware Cascaded Sampling
Oct 24, 2024



While image generation with diffusion models has achieved a great success, generating images of higher resolution than the training size remains a challenging task due to the high computational cost. Current methods typically perform the entire sampling process at full resolution and process all frequency components simultaneously, contradicting with the inherent coarse-to-fine nature of latent diffusion models and wasting computations on processing premature high-frequency details at early diffusion stages. To address this issue, we introduce an efficient $\textbf{Fre}$quency-aware $\textbf{Ca}$scaded $\textbf{S}$ampling framework, $\textbf{FreCaS}$ in short, for higher-resolution image generation. FreCaS decomposes the sampling process into cascaded stages with gradually increased resolutions, progressively expanding frequency bands and refining the corresponding details. We propose an innovative frequency-aware classifier-free guidance (FA-CFG) strategy to assign different guidance strengths for different frequency components, directing the diffusion model to add new details in the expanded frequency domain of each stage. Additionally, we fuse the cross-attention maps of previous and current stages to avoid synthesizing unfaithful layouts. Experiments demonstrate that FreCaS significantly outperforms state-of-the-art methods in image quality and generation speed. In particular, FreCaS is about 2.86$\times$ and 6.07$\times$ faster than ScaleCrafter and DemoFusion in generating a 2048$\times$2048 image using a pre-trained SDXL model and achieves an FID$_b$ improvement of 11.6 and 3.7, respectively. FreCaS can be easily extended to more complex models such as SD3. The source code of FreCaS can be found at $\href{\text{https://github.com/xtudbxk/FreCaS}}{https://github.com/xtudbxk/FreCaS}$.
Spatial-Mamba: Effective Visual State Space Models via Structure-Aware State Fusion
Oct 19, 2024

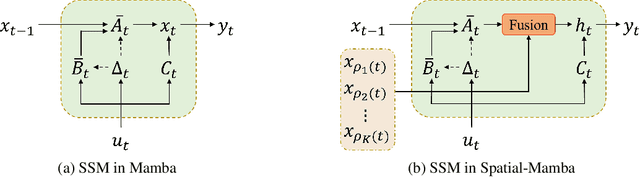

Selective state space models (SSMs), such as Mamba, highly excel at capturing long-range dependencies in 1D sequential data, while their applications to 2D vision tasks still face challenges. Current visual SSMs often convert images into 1D sequences and employ various scanning patterns to incorporate local spatial dependencies. However, these methods are limited in effectively capturing the complex image spatial structures and the increased computational cost caused by the lengthened scanning paths. To address these limitations, we propose Spatial-Mamba, a novel approach that establishes neighborhood connectivity directly in the state space. Instead of relying solely on sequential state transitions, we introduce a structure-aware state fusion equation, which leverages dilated convolutions to capture image spatial structural dependencies, significantly enhancing the flow of visual contextual information. Spatial-Mamba proceeds in three stages: initial state computation in a unidirectional scan, spatial context acquisition through structure-aware state fusion, and final state computation using the observation equation. Our theoretical analysis shows that Spatial-Mamba unifies the original Mamba and linear attention under the same matrix multiplication framework, providing a deeper understanding of our method. Experimental results demonstrate that Spatial-Mamba, even with a single scan, attains or surpasses the state-of-the-art SSM-based models in image classification, detection and segmentation. Source codes and trained models can be found at $\href{https://github.com/EdwardChasel/Spatial-Mamba}{\text{this https URL}}$.
SSL: A Self-similarity Loss for Improving Generative Image Super-resolution
Aug 11, 2024Generative adversarial networks (GAN) and generative diffusion models (DM) have been widely used in real-world image super-resolution (Real-ISR) to enhance the image perceptual quality. However, these generative models are prone to generating visual artifacts and false image structures, resulting in unnatural Real-ISR results. Based on the fact that natural images exhibit high self-similarities, i.e., a local patch can have many similar patches to it in the whole image, in this work we propose a simple yet effective self-similarity loss (SSL) to improve the performance of generative Real-ISR models, enhancing the hallucination of structural and textural details while reducing the unpleasant visual artifacts. Specifically, we compute a self-similarity graph (SSG) of the ground-truth image, and enforce the SSG of Real-ISR output to be close to it. To reduce the training cost and focus on edge areas, we generate an edge mask from the ground-truth image, and compute the SSG only on the masked pixels. The proposed SSL serves as a general plug-and-play penalty, which could be easily applied to the off-the-shelf Real-ISR models. Our experiments demonstrate that, by coupling with SSL, the performance of many state-of-the-art Real-ISR models, including those GAN and DM based ones, can be largely improved, reproducing more perceptually realistic image details and eliminating many false reconstructions and visual artifacts. Codes and supplementary material can be found at https://github.com/ChrisDud0257/SSL
Dense Multimodal Alignment for Open-Vocabulary 3D Scene Understanding
Jul 13, 2024



Recent vision-language pre-training models have exhibited remarkable generalization ability in zero-shot recognition tasks. Previous open-vocabulary 3D scene understanding methods mostly focus on training 3D models using either image or text supervision while neglecting the collective strength of all modalities. In this work, we propose a Dense Multimodal Alignment (DMA) framework to densely co-embed different modalities into a common space for maximizing their synergistic benefits. Instead of extracting coarse view- or region-level text prompts, we leverage large vision-language models to extract complete category information and scalable scene descriptions to build the text modality, and take image modality as the bridge to build dense point-pixel-text associations. Besides, in order to enhance the generalization ability of the 2D model for downstream 3D tasks without compromising the open-vocabulary capability, we employ a dual-path integration approach to combine frozen CLIP visual features and learnable mask features. Extensive experiments show that our DMA method produces highly competitive open-vocabulary segmentation performance on various indoor and outdoor tasks.
SyncNoise: Geometrically Consistent Noise Prediction for Text-based 3D Scene Editing
Jun 25, 2024Text-based 2D diffusion models have demonstrated impressive capabilities in image generation and editing. Meanwhile, the 2D diffusion models also exhibit substantial potentials for 3D editing tasks. However, how to achieve consistent edits across multiple viewpoints remains a challenge. While the iterative dataset update method is capable of achieving global consistency, it suffers from slow convergence and over-smoothed textures. We propose SyncNoise, a novel geometry-guided multi-view consistent noise editing approach for high-fidelity 3D scene editing. SyncNoise synchronously edits multiple views with 2D diffusion models while enforcing multi-view noise predictions to be geometrically consistent, which ensures global consistency in both semantic structure and low-frequency appearance. To further enhance local consistency in high-frequency details, we set a group of anchor views and propagate them to their neighboring frames through cross-view reprojection. To improve the reliability of multi-view correspondences, we introduce depth supervision during training to enhance the reconstruction of precise geometries. Our method achieves high-quality 3D editing results respecting the textual instructions, especially in scenes with complex textures, by enhancing geometric consistency at the noise and pixel levels.
Improving the Stability of Diffusion Models for Content Consistent Super-Resolution
Dec 30, 2023



The generative priors of pre-trained latent diffusion models have demonstrated great potential to enhance the perceptual quality of image super-resolution (SR) results. Unfortunately, the existing diffusion prior-based SR methods encounter a common problem, i.e., they tend to generate rather different outputs for the same low-resolution image with different noise samples. Such stochasticity is desired for text-to-image generation tasks but problematic for SR tasks, where the image contents are expected to be well preserved. To improve the stability of diffusion prior-based SR, we propose to employ the diffusion models to refine image structures, while employing the generative adversarial training to enhance image fine details. Specifically, we propose a non-uniform timestep learning strategy to train a compact diffusion network, which has high efficiency and stability to reproduce the image main structures, and finetune the pre-trained decoder of variational auto-encoder (VAE) by adversarial training for detail enhancement. Extensive experiments show that our proposed method, namely content consistent super-resolution (CCSR), can significantly reduce the stochasticity of diffusion prior-based SR, improving the content consistency of SR outputs and speeding up the image generation process. Codes and models can be found at {https://github.com/csslc/CCSR}.