 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Generalized Image Quality Assessment: Relaxing the Perfect Reference Quality Assumption
Mar 14, 2025



Full-reference image quality assessment (FR-IQA) generally assumes that reference images are of perfect quality. However, this assumption is flawed due to the sensor and optical limitations of modern imaging systems. Moreover, recent generative enhancement methods are capable of producing images of higher quality than their original. All of these challenge the effectiveness and applicability of current FR-IQA models. To relax the assumption of perfect reference image quality, we build a large-scale IQA database, namely DiffIQA, containing approximately 180,000 images generated by a diffusion-based image enhancer with adjustable hyper-parameters. Each image is annotated by human subjects as either worse, similar, or better quality compared to its reference. Building on this, we present a generalized FR-IQA model, namely Adaptive Fidelity-Naturalness Evaluator (A-FINE), to accurately assess and adaptively combine the fidelity and naturalness of a test image. A-FINE aligns well with standard FR-IQA when the reference image is much more natural than the test image. We demonstrate by extensive experiments that A-FINE surpasses standard FR-IQA models on well-established IQA datasets and our newly created DiffIQA. To further validate A-FINE, we additionally construct a super-resolution IQA benchmark (SRIQA-Bench), encompassing test images derived from ten state-of-the-art SR methods with reliable human quality annotations. Tests on SRIQA-Bench re-affirm the advantages of A-FINE. The code and dataset are available at https://tianhewu.github.io/A-FINE-page.github.io/.
Generalized and Efficient 2D Gaussian Splatting for Arbitrary-scale Super-Resolution
Jan 14, 2025



Equipped with the continuous representation capability of Multi-Layer Perceptron (MLP), Implicit Neural Representation (INR) has been successfully employed for Arbitrary-scale Super-Resolution (ASR). However, the limited receptive field of the linear layers in MLP restricts the representation capability of INR, while it is computationally expensive to query the MLP numerous times to render each pixel. Recently, Gaussian Splatting (GS) has shown its advantages over INR in both visual quality and rendering speed in 3D tasks, which motivates us to explore whether GS can be employed for the ASR task. However, directly applying GS to ASR is exceptionally challenging because the original GS is an optimization-based method through overfitting each single scene, while in ASR we aim to learn a single model that can generalize to different images and scaling factors. We overcome these challenges by developing two novel techniques. Firstly, to generalize GS for ASR, we elaborately design an architecture to predict the corresponding image-conditioned Gaussians of the input low-resolution image in a feed-forward manner. Secondly, we implement an efficient differentiable 2D GPU/CUDA-based scale-aware rasterization to render super-resolved images by sampling discrete RGB values from the predicted contiguous Gaussians. Via end-to-end training, our optimized network, namely GSASR, can perform ASR for any image and unseen scaling factors. Extensive experiments validate the effectiveness of our proposed method. The project page can be found at \url{https://mt-cly.github.io/GSASR.github.io/}.
SSL: A Self-similarity Loss for Improving Generative Image Super-resolution
Aug 11, 2024Generative adversarial networks (GAN) and generative diffusion models (DM) have been widely used in real-world image super-resolution (Real-ISR) to enhance the image perceptual quality. However, these generative models are prone to generating visual artifacts and false image structures, resulting in unnatural Real-ISR results. Based on the fact that natural images exhibit high self-similarities, i.e., a local patch can have many similar patches to it in the whole image, in this work we propose a simple yet effective self-similarity loss (SSL) to improve the performance of generative Real-ISR models, enhancing the hallucination of structural and textural details while reducing the unpleasant visual artifacts. Specifically, we compute a self-similarity graph (SSG) of the ground-truth image, and enforce the SSG of Real-ISR output to be close to it. To reduce the training cost and focus on edge areas, we generate an edge mask from the ground-truth image, and compute the SSG only on the masked pixels. The proposed SSL serves as a general plug-and-play penalty, which could be easily applied to the off-the-shelf Real-ISR models. Our experiments demonstrate that, by coupling with SSL, the performance of many state-of-the-art Real-ISR models, including those GAN and DM based ones, can be largely improved, reproducing more perceptually realistic image details and eliminating many false reconstructions and visual artifacts. Codes and supplementary material can be found at https://github.com/ChrisDud0257/SSL
Orion-14B: Open-source Multilingual Large Language Models
Jan 20, 2024In this study, we introduce Orion-14B, a collection of multilingual large language models with 14 billion parameters. We utilize a data scheduling approach to train a foundational model on a diverse corpus of 2.5 trillion tokens, sourced from texts in English, Chinese, Japanese, Korean, and other languages. Additionally, we fine-tuned a series of models tailored for conversational applications and other specific use cases. Our evaluation results demonstrate that Orion-14B achieves state-of-the-art performance across a broad spectrum of tasks. We make the Orion-14B model family and its associated code publicly accessible https://github.com/OrionStarAI/Orion, aiming to inspire future research and practical applications in the field.
Human Guided Ground-truth Generation for Realistic Image Super-resolution
Mar 23, 2023



How to generate the ground-truth (GT) image is a critical issue for training realistic image super-resolution (Real-ISR) models. Existing methods mostly take a set of high-resolution (HR) images as GTs and apply various degradations to simulate their low-resolution (LR) counterparts. Though great progress has been achieved, such an LR-HR pair generation scheme has several limitations. First, the perceptual quality of HR images may not be high enough, limiting the quality of Real-ISR outputs. Second, existing schemes do not consider much human perception in GT generation, and the trained models tend to produce over-smoothed results or unpleasant artifacts. With the above considerations, we propose a human guided GT generation scheme. We first elaborately train multiple image enhancement models to improve the perceptual quality of HR images, and enable one LR image having multiple HR counterparts. Human subjects are then involved to annotate the high quality regions among the enhanced HR images as GTs, and label the regions with unpleasant artifacts as negative samples. A human guided GT image dataset with both positive and negative samples is then constructed, and a loss function is proposed to train the Real-ISR models. Experiments show that the Real-ISR models trained on our dataset can produce perceptually more realistic results with less artifacts. Dataset and codes can be found at https://github.com/ChrisDud0257/HGGT
Deep Neural Network for Fast and Accurate Single Image Super-Resolution via Channel-Attention-based Fusion of Orientation-aware Features
Dec 09, 2019


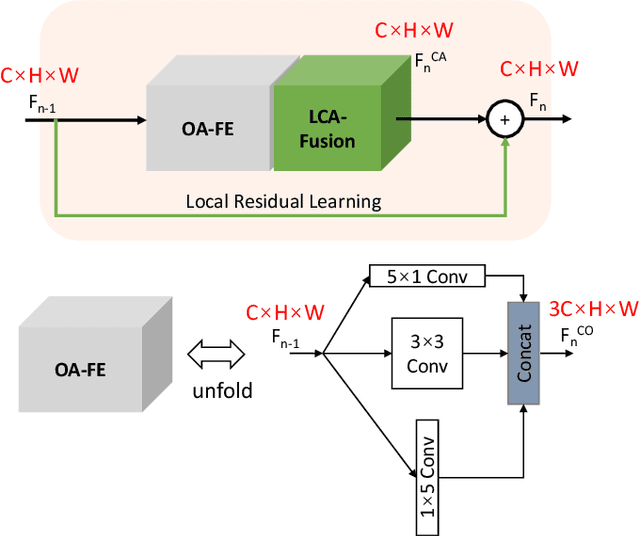
Recently, Convolutional Neural Networks (CNNs) have been successfully adopted to solve the ill-posed single image super-resolution (SISR) problem. A commonly used strategy to boost the performance of CNN-based SISR models is deploying very deep networks, which inevitably incurs many obvious drawbacks (e.g., a large number of network parameters, heavy computational loads, and difficult model training). In this paper, we aim to build more accurate and faster SISR models via developing better-performing feature extraction and fusion techniques. Firstly, we proposed a novel Orientation-Aware feature extraction and fusion Module (OAM), which contains a mixture of 1D and 2D convolutional kernels (i.e., 5 x 1, 1 x 5, and 3 x 3) for extracting orientation-aware features. Secondly, we adopt the channel attention mechanism as an effective technique to adaptively fuse features extracted in different directions and in hierarchically stacked convolutional stages. Based on these two important improvements, we present a compact but powerful CNN-based model for high-quality SISR via Channel Attention-based fusion of Orientation-Aware features (SISR-CA-OA). Extensive experimental results verify the superiority of the proposed SISR-CA-OA model, performing favorably against the state-of-the-art SISR models in terms of both restoration accuracy and computational efficiency. The source codes will be made publicly available.