 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Diffusion Compression for Real-World Image Super-Resolution
Nov 20, 2024



Real-world image super-resolution (Real-ISR) aims to reconstruct high-resolution images from low-resolution inputs degraded by complex, unknown processes. While many Stable Diffusion (SD)-based Real-ISR methods have achieved remarkable success, their slow, multi-step inference hinders practical deployment. Recent SD-based one-step networks like OSEDiff and S3Diff alleviate this issue but still incur high computational costs due to their reliance on large pretrained SD models. This paper proposes a novel Real-ISR method, AdcSR, by distilling the one-step diffusion network OSEDiff into a streamlined diffusion-GAN model under our Adversarial Diffusion Compression (ADC) framework. We meticulously examine the modules of OSEDiff, categorizing them into two types: (1) Removable (VAE encoder, prompt extractor, text encoder, etc.) and (2) Prunable (denoising UNet and VAE decoder). Since direct removal and pruning can degrade the model's generation capability, we pretrain our pruned VAE decoder to restore its ability to decode images and employ adversarial distillation to compensate for performance loss. This ADC-based diffusion-GAN hybrid design effectively reduces complexity by 73% in inference time, 78% in computation, and 74% in parameters, while preserving the model's generation capability. Experiments manifest that our proposed AdcSR achieves competitive recovery quality on both synthetic and real-world datasets, offering up to 9.3$\times$ speedup over previous one-step diffusion-based methods. Code and models will be made available.
NTIRE 2024 Restore Any Image Model in the Wild Challenge
May 16, 2024
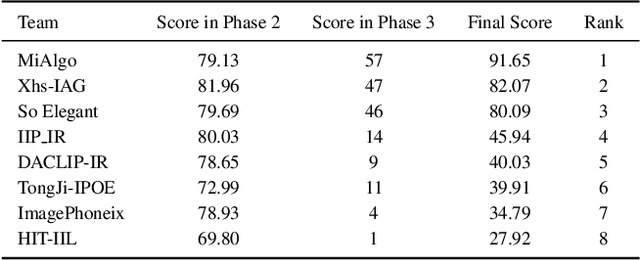

In this paper, we review the NTIRE 2024 challenge on Restore Any Image Model (RAIM) in the Wild. The RAIM challenge constructed a benchmark for image restoration in the wild, including real-world images with/without reference ground truth in various scenarios from real applications. The participants were required to restore the real-captured images from complex and unknown degradation, where generative perceptual quality and fidelity are desired in the restoration result. The challenge consisted of two tasks. Task one employed real referenced data pairs, where quantitative evaluation is available. Task two used unpaired images, and a comprehensive user study was conducted. The challenge attracted more than 200 registrations, where 39 of them submitted results with more than 400 submissions. Top-ranked methods improved the state-of-the-art restoration performance and obtained unanimous recognition from all 18 judges. The proposed datasets are available at https://drive.google.com/file/d/1DqbxUoiUqkAIkExu3jZAqoElr_nu1IXb/view?usp=sharing and the homepage of this challenge is at https://codalab.lisn.upsaclay.fr/competitions/17632.
UniVS: Unified and Universal Video Segmentation with Prompts as Queries
Feb 28, 2024Despite the recent advances in unified image segmentation (IS), developing a unified video segmentation (VS) model remains a challenge. This is mainly because generic category-specified VS tasks need to detect all objects and track them across consecutive frames, while prompt-guided VS tasks require re-identifying the target with visual/text prompts throughout the entire video, making it hard to handle the different tasks with the same architecture. We make an attempt to address these issues and present a novel unified VS architecture, namely UniVS, by using prompts as queries. UniVS averages the prompt features of the target from previous frames as its initial query to explicitly decode masks, and introduces a target-wise prompt cross-attention layer in the mask decoder to integrate prompt features in the memory pool. By taking the predicted masks of entities from previous frames as their visual prompts, UniVS converts different VS tasks into prompt-guided target segmentation, eliminating the heuristic inter-frame matching process. Our framework not only unifies the different VS tasks but also naturally achieves universal training and testing, ensuring robust performance across different scenarios. UniVS shows a commendable balance between performance and universality on 10 challenging VS benchmarks, covering video instance, semantic, panoptic, object, and referring segmentation tasks. Code can be found at \url{https://github.com/MinghanLi/UniVS}.
* 21 pages, 11 figures, 10 tabels, CVPR2024
Generalized Large-Scale Data Condensation via Various Backbone and Statistical Matching
Nov 29, 2023



The lightweight "local-match-global" matching introduced by SRe2L successfully creates a distilled dataset with comprehensive information on the full 224x224 ImageNet-1k. However, this one-sided approach is limited to a particular backbone, layer, and statistics, which limits the improvement of the generalization of a distilled dataset. We suggest that sufficient and various "local-match-global" matching are more precise and effective than a single one and has the ability to create a distilled dataset with richer information and better generalization. We call this perspective "generalized matching" and propose Generalized Various Backbone and Statistical Matching (G-VBSM) in this work, which aims to create a synthetic dataset with densities, ensuring consistency with the complete dataset across various backbones, layers, and statistics. As experimentally demonstrated, G-VBSM is the first algorithm to obtain strong performance across both small-scale and large-scale datasets. Specifically, G-VBSM achieves a performance of 38.7% on CIFAR-100 with 128-width ConvNet, 47.6% on Tiny-ImageNet with ResNet18, and 31.4% on the full 224x224 ImageNet-1k with ResNet18, under images per class (IPC) 10, 50, and 10, respectively. These results surpass all SOTA methods by margins of 3.9%, 6.5%, and 10.1%, respectively.
Human Guided Ground-truth Generation for Realistic Image Super-resolution
Mar 23, 2023



How to generate the ground-truth (GT) image is a critical issue for training realistic image super-resolution (Real-ISR) models. Existing methods mostly take a set of high-resolution (HR) images as GTs and apply various degradations to simulate their low-resolution (LR) counterparts. Though great progress has been achieved, such an LR-HR pair generation scheme has several limitations. First, the perceptual quality of HR images may not be high enough, limiting the quality of Real-ISR outputs. Second, existing schemes do not consider much human perception in GT generation, and the trained models tend to produce over-smoothed results or unpleasant artifacts. With the above considerations, we propose a human guided GT generation scheme. We first elaborately train multiple image enhancement models to improve the perceptual quality of HR images, and enable one LR image having multiple HR counterparts. Human subjects are then involved to annotate the high quality regions among the enhanced HR images as GTs, and label the regions with unpleasant artifacts as negative samples. A human guided GT image dataset with both positive and negative samples is then constructed, and a loss function is proposed to train the Real-ISR models. Experiments show that the Real-ISR models trained on our dataset can produce perceptually more realistic results with less artifacts. Dataset and codes can be found at https://github.com/ChrisDud0257/HGGT
Spatial-Frequency Attention for Image Denoising
Feb 27, 2023The recently developed transformer networks have achieved impressive performance in image denoising by exploiting the self-attention (SA) in images. However, the existing methods mostly use a relatively small window to compute SA due to the quadratic complexity of it, which limits the model's ability to model long-term image information. In this paper, we propose the spatial-frequency attention network (SFANet) to enhance the network's ability in exploiting long-range dependency. For spatial attention module (SAM), we adopt dilated SA to model long-range dependency. In the frequency attention module (FAM), we exploit more global information by using Fast Fourier Transform (FFT) by designing a window-based frequency channel attention (WFCA) block to effectively model deep frequency features and their dependencies. To make our module applicable to images of different sizes and keep the model consistency between training and inference, we apply window-based FFT with a set of fixed window sizes. In addition, channel attention is computed on both real and imaginary parts of the Fourier spectrum, which further improves restoration performance. The proposed WFCA block can effectively model image long-range dependency with acceptable complexity. Experiments on multiple denoising benchmarks demonstrate the leading performance of SFANet network.
Efficient Long-Range Attention Network for Image Super-resolution
Mar 13, 2022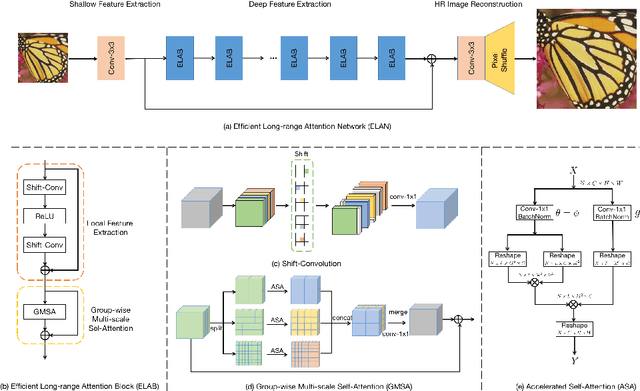



Recently, transformer-based methods have demonstrated impressive results in various vision tasks, including image super-resolution (SR), by exploiting the self-attention (SA) for feature extraction. However, the computation of SA in most existing transformer based models is very expensive, while some employed operations may be redundant for the SR task. This limits the range of SA computation and consequently the SR performance. In this work, we propose an efficient long-range attention network (ELAN) for image SR. Specifically, we first employ shift convolution (shift-conv) to effectively extract the image local structural information while maintaining the same level of complexity as 1x1 convolution, then propose a group-wise multi-scale self-attention (GMSA) module, which calculates SA on non-overlapped groups of features using different window sizes to exploit the long-range image dependency. A highly efficient long-range attention block (ELAB) is then built by simply cascading two shift-conv with a GMSA module, which is further accelerated by using a shared attention mechanism. Without bells and whistles, our ELAN follows a fairly simple design by sequentially cascading the ELABs. Extensive experiments demonstrate that ELAN obtains even better results against the transformer-based SR models but with significantly less complexity. The source code can be found at https://github.com/xindongzhang/ELAN.
Real-Time Quantized Image Super-Resolution on Mobile NPUs, Mobile AI 2021 Challenge: Report
May 17, 2021
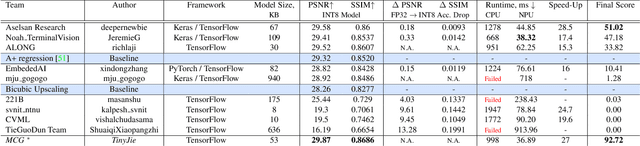
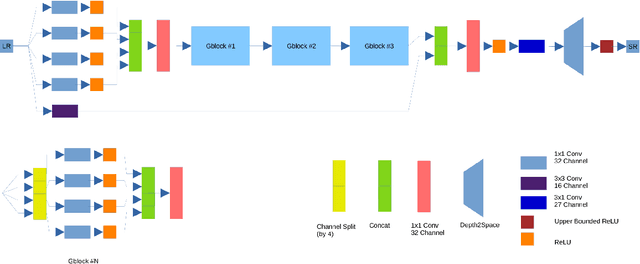
Image super-resolution is one of the most popular computer vision problems with many important applications to mobile devices. While many solutions have been proposed for this task, they are usually not optimized even for common smartphone AI hardware, not to mention more constrained smart TV platforms that are often supporting INT8 inference only. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image super-resolution solutions that can demonstrate a real-time performance on mobile or edge NPUs. For this, the participants were provided with the DIV2K dataset and trained quantized models to do an efficient 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated NPU capable of accelerating quantized neural networks. The proposed solutions are fully compatible with all major mobile AI accelerators and are capable of reconstructing Full HD images under 40-60 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.