 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond External Guidance: Unleashing the Semantic Richness Inside Diffusion Transformers for Improved Training
Jan 12, 2026Recent works such as REPA have shown that guiding diffusion models with external semantic features (e.g., DINO) can significantly accelerate the training of diffusion transformers (DiTs). However, this requires the use of pretrained external networks, introducing additional dependencies and reducing flexibility. In this work, we argue that DiTs actually have the power to guide the training of themselves, and propose \textbf{Self-Transcendence}, a simple yet effective method that achieves fast convergence using internal feature supervision only. It is found that the slow convergence in DiT training primarily stems from the difficulty of representation learning in shallow layers. To address this, we initially train the DiT model by aligning its shallow features with the latent representations from the pretrained VAE for a short phase (e.g., 40 epochs), then apply classifier-free guidance to the intermediate features, enhancing their discriminative capability and semantic expressiveness. These enriched internal features, learned entirely within the model, are used as supervision signals to guide a new DiT training. Compared to existing self-contained methods, our approach brings a significant performance boost. It can even surpass REPA in terms of generation quality and convergence speed, but without the need for any external pretrained models. Our method is not only more flexible for different backbones but also has the potential to be adopted for a wider range of diffusion-based generative tasks. The source code of our method can be found at https://github.com/csslc/Self-Transcendence.
DP$^2$O-SR: Direct Perceptual Preference Optimization for Real-World Image Super-Resolution
Oct 21, 2025Benefiting from pre-trained text-to-image (T2I) diffusion models, real-world image super-resolution (Real-ISR) methods can synthesize rich and realistic details. However, due to the inherent stochasticity of T2I models, different noise inputs often lead to outputs with varying perceptual quality. Although this randomness is sometimes seen as a limitation, it also introduces a wider perceptual quality range, which can be exploited to improve Real-ISR performance. To this end, we introduce Direct Perceptual Preference Optimization for Real-ISR (DP$^2$O-SR), a framework that aligns generative models with perceptual preferences without requiring costly human annotations. We construct a hybrid reward signal by combining full-reference and no-reference image quality assessment (IQA) models trained on large-scale human preference datasets. This reward encourages both structural fidelity and natural appearance. To better utilize perceptual diversity, we move beyond the standard best-vs-worst selection and construct multiple preference pairs from outputs of the same model. Our analysis reveals that the optimal selection ratio depends on model capacity: smaller models benefit from broader coverage, while larger models respond better to stronger contrast in supervision. Furthermore, we propose hierarchical preference optimization, which adaptively weights training pairs based on intra-group reward gaps and inter-group diversity, enabling more efficient and stable learning. Extensive experiments across both diffusion- and flow-based T2I backbones demonstrate that DP$^2$O-SR significantly improves perceptual quality and generalizes well to real-world benchmarks.
NSARM: Next-Scale Autoregressive Modeling for Robust Real-World Image Super-Resolution
Oct 01, 2025



Most recent real-world image super-resolution (Real-ISR) methods employ pre-trained text-to-image (T2I) diffusion models to synthesize the high-quality image either from random Gaussian noise, which yields realistic results but is slow due to iterative denoising, or directly from the input low-quality image, which is efficient but at the price of lower output quality. These approaches train ControlNet or LoRA modules while keeping the pre-trained model fixed, which often introduces over-enhanced artifacts and hallucinations, suffering from the robustness to inputs of varying degradations. Recent visual autoregressive (AR) models, such as pre-trained Infinity, can provide strong T2I generation capabilities while offering superior efficiency by using the bitwise next-scale prediction strategy. Building upon next-scale prediction, we introduce a robust Real-ISR framework, namely Next-Scale Autoregressive Modeling (NSARM). Specifically, we train NSARM in two stages: a transformation network is first trained to map the input low-quality image to preliminary scales, followed by an end-to-end full-model fine-tuning. Such a comprehensive fine-tuning enhances the robustness of NSARM in Real-ISR tasks without compromising its generative capability. Extensive quantitative and qualitative evaluations demonstrate that as a pure AR model, NSARM achieves superior visual results over existing Real-ISR methods while maintaining a fast inference speed. Most importantly, it demonstrates much higher robustness to the quality of input images, showing stronger generalization performance. Project page: https://github.com/Xiangtaokong/NSARM
Fine-structure Preserved Real-world Image Super-resolution via Transfer VAE Training
Jul 27, 2025Impressive results on real-world image super-resolution (Real-ISR) have been achieved by employing pre-trained stable diffusion (SD) models. However, one critical issue of such methods lies in their poor reconstruction of image fine structures, such as small characters and textures, due to the aggressive resolution reduction of the VAE (eg., 8$\times$ downsampling) in the SD model. One solution is to employ a VAE with a lower downsampling rate for diffusion; however, adapting its latent features with the pre-trained UNet while mitigating the increased computational cost poses new challenges. To address these issues, we propose a Transfer VAE Training (TVT) strategy to transfer the 8$\times$ downsampled VAE into a 4$\times$ one while adapting to the pre-trained UNet. Specifically, we first train a 4$\times$ decoder based on the output features of the original VAE encoder, then train a 4$\times$ encoder while keeping the newly trained decoder fixed. Such a TVT strategy aligns the new encoder-decoder pair with the original VAE latent space while enhancing image fine details. Additionally, we introduce a compact VAE and compute-efficient UNet by optimizing their network architectures, reducing the computational cost while capturing high-resolution fine-scale features. Experimental results demonstrate that our TVT method significantly improves fine-structure preservation, which is often compromised by other SD-based methods, while requiring fewer FLOPs than state-of-the-art one-step diffusion models. The official code can be found at https://github.com/Joyies/TVT.
One-Step Diffusion for Detail-Rich and Temporally Consistent Video Super-Resolution
Jun 18, 2025

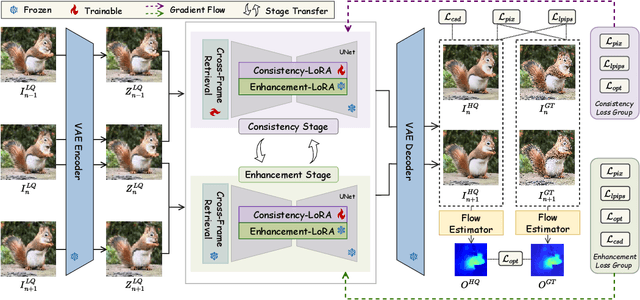

It is a challenging problem to reproduce rich spatial details while maintaining temporal consistency in real-world video super-resolution (Real-VSR), especially when we leverage pre-trained generative models such as stable diffusion (SD) for realistic details synthesis. Existing SD-based Real-VSR methods often compromise spatial details for temporal coherence, resulting in suboptimal visual quality. We argue that the key lies in how to effectively extract the degradation-robust temporal consistency priors from the low-quality (LQ) input video and enhance the video details while maintaining the extracted consistency priors. To achieve this, we propose a Dual LoRA Learning (DLoRAL) paradigm to train an effective SD-based one-step diffusion model, achieving realistic frame details and temporal consistency simultaneously. Specifically, we introduce a Cross-Frame Retrieval (CFR) module to aggregate complementary information across frames, and train a Consistency-LoRA (C-LoRA) to learn robust temporal representations from degraded inputs. After consistency learning, we fix the CFR and C-LoRA modules and train a Detail-LoRA (D-LoRA) to enhance spatial details while aligning with the temporal space defined by C-LoRA to keep temporal coherence. The two phases alternate iteratively for optimization, collaboratively delivering consistent and detail-rich outputs. During inference, the two LoRA branches are merged into the SD model, allowing efficient and high-quality video restoration in a single diffusion step. Experiments show that DLoRAL achieves strong performance in both accuracy and speed. Code and models are available at https://github.com/yjsunnn/DLoRAL.
Progressive Rendering Distillation: Adapting Stable Diffusion for Instant Text-to-Mesh Generation without 3D Data
Mar 27, 2025



It is highly desirable to obtain a model that can generate high-quality 3D meshes from text prompts in just seconds. While recent attempts have adapted pre-trained text-to-image diffusion models, such as Stable Diffusion (SD), into generators of 3D representations (e.g., Triplane), they often suffer from poor quality due to the lack of sufficient high-quality 3D training data. Aiming at overcoming the data shortage, we propose a novel training scheme, termed as Progressive Rendering Distillation (PRD), eliminating the need for 3D ground-truths by distilling multi-view diffusion models and adapting SD into a native 3D generator. In each iteration of training, PRD uses the U-Net to progressively denoise the latent from random noise for a few steps, and in each step it decodes the denoised latent into 3D output. Multi-view diffusion models, including MVDream and RichDreamer, are used in joint with SD to distill text-consistent textures and geometries into the 3D outputs through score distillation. Since PRD supports training without 3D ground-truths, we can easily scale up the training data and improve generation quality for challenging text prompts with creative concepts. Meanwhile, PRD can accelerate the inference speed of the generation model in just a few steps. With PRD, we train a Triplane generator, namely TriplaneTurbo, which adds only $2.5\%$ trainable parameters to adapt SD for Triplane generation. TriplaneTurbo outperforms previous text-to-3D generators in both efficiency and quality. Specifically, it can produce high-quality 3D meshes in 1.2 seconds and generalize well for challenging text input. The code is available at https://github.com/theEricMa/TriplaneTurbo.
Pixel-level and Semantic-level Adjustable Super-resolution: A Dual-LoRA Approach
Dec 04, 2024



Diffusion prior-based methods have shown impressive results in real-world image super-resolution (SR). However, most existing methods entangle pixel-level and semantic-level SR objectives in the training process, struggling to balance pixel-wise fidelity and perceptual quality. Meanwhile, users have varying preferences on SR results, thus it is demanded to develop an adjustable SR model that can be tailored to different fidelity-perception preferences during inference without re-training. We present Pixel-level and Semantic-level Adjustable SR (PiSA-SR), which learns two LoRA modules upon the pre-trained stable-diffusion (SD) model to achieve improved and adjustable SR results. We first formulate the SD-based SR problem as learning the residual between the low-quality input and the high-quality output, then show that the learning objective can be decoupled into two distinct LoRA weight spaces: one is characterized by the $\ell_2$-loss for pixel-level regression, and another is characterized by the LPIPS and classifier score distillation losses to extract semantic information from pre-trained classification and SD models. In its default setting, PiSA-SR can be performed in a single diffusion step, achieving leading real-world SR results in both quality and efficiency. By introducing two adjustable guidance scales on the two LoRA modules to control the strengths of pixel-wise fidelity and semantic-level details during inference, PiSASR can offer flexible SR results according to user preference without re-training. Codes and models can be found at https://github.com/csslc/PiSA-SR.
Adversarial Diffusion Compression for Real-World Image Super-Resolution
Nov 20, 2024



Real-world image super-resolution (Real-ISR) aims to reconstruct high-resolution images from low-resolution inputs degraded by complex, unknown processes. While many Stable Diffusion (SD)-based Real-ISR methods have achieved remarkable success, their slow, multi-step inference hinders practical deployment. Recent SD-based one-step networks like OSEDiff and S3Diff alleviate this issue but still incur high computational costs due to their reliance on large pretrained SD models. This paper proposes a novel Real-ISR method, AdcSR, by distilling the one-step diffusion network OSEDiff into a streamlined diffusion-GAN model under our Adversarial Diffusion Compression (ADC) framework. We meticulously examine the modules of OSEDiff, categorizing them into two types: (1) Removable (VAE encoder, prompt extractor, text encoder, etc.) and (2) Prunable (denoising UNet and VAE decoder). Since direct removal and pruning can degrade the model's generation capability, we pretrain our pruned VAE decoder to restore its ability to decode images and employ adversarial distillation to compensate for performance loss. This ADC-based diffusion-GAN hybrid design effectively reduces complexity by 73% in inference time, 78% in computation, and 74% in parameters, while preserving the model's generation capability. Experiments manifest that our proposed AdcSR achieves competitive recovery quality on both synthetic and real-world datasets, offering up to 9.3$\times$ speedup over previous one-step diffusion-based methods. Code and models will be made available.
One-Step Effective Diffusion Network for Real-World Image Super-Resolution
Jun 12, 2024The pre-trained text-to-image diffusion models have been increasingly employed to tackle the real-world image super-resolution (Real-ISR) problem due to their powerful generative image priors. Most of the existing methods start from random noise to reconstruct the high-quality (HQ) image under the guidance of the given low-quality (LQ) image. While promising results have been achieved, such Real- ISR methods require multiple diffusion steps to reproduce the HQ image, increasing the computational cost. Meanwhile, the random noise introduces uncertainty in the output, which is unfriendly to image restoration tasks. To address these issues, we propose a one-step effective diffusion network, namely OSEDiff, for the Real- ISR problem. We argue that the LQ image contains rich information to restore its HQ counterpart, and hence the given LQ image can be directly taken as the starting point for diffusion, eliminating the uncertainty introduced by random noise sampling. We finetune the pre-trained diffusion network with trainable layers to adapt it to complex image degradations. To ensure that the one-step diffusion model could yield HQ Real-ISR output, we apply variational score distillation in the latent space to conduct KL-divergence regularization. As a result, our OSEDiff model can efficiently and effectively generate HQ images in just one diffusion step. Our experiments demonstrate that OSEDiff achieves comparable or even better Real-ISR results, in terms of both objective metrics and subjective evaluations, than previous diffusion model based Real-ISR methods that require dozens or hundreds of steps. The source codes will be released at https://github.com/cswry/OSEDiff.
NTIRE 2024 Restore Any Image Model in the Wild Challenge
May 16, 2024
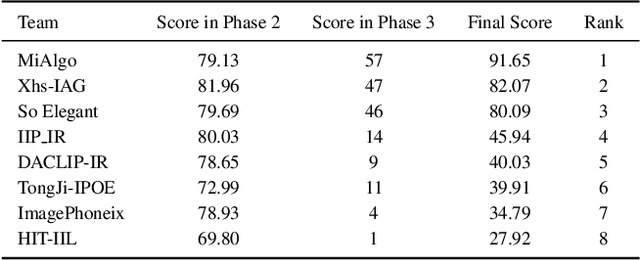

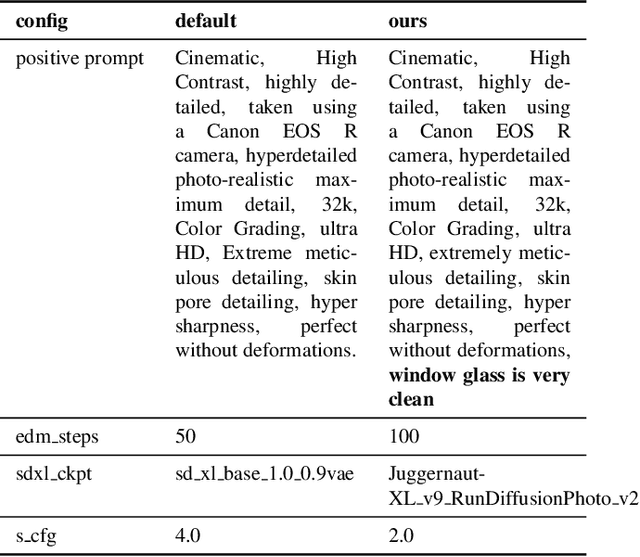
In this paper, we review the NTIRE 2024 challenge on Restore Any Image Model (RAIM) in the Wild. The RAIM challenge constructed a benchmark for image restoration in the wild, including real-world images with/without reference ground truth in various scenarios from real applications. The participants were required to restore the real-captured images from complex and unknown degradation, where generative perceptual quality and fidelity are desired in the restoration result. The challenge consisted of two tasks. Task one employed real referenced data pairs, where quantitative evaluation is available. Task two used unpaired images, and a comprehensive user study was conducted. The challenge attracted more than 200 registrations, where 39 of them submitted results with more than 400 submissions. Top-ranked methods improved the state-of-the-art restoration performance and obtained unanimous recognition from all 18 judges. The proposed datasets are available at https://drive.google.com/file/d/1DqbxUoiUqkAIkExu3jZAqoElr_nu1IXb/view?usp=sharing and the homepage of this challenge is at https://codalab.lisn.upsaclay.fr/competitions/17632.