 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoto3D: Advancing Photorealistic 3D Generation through Structure-Aligned Detail Enhancement
Dec 09, 2025Although recent 3D-native generators have made great progress in synthesizing reliable geometry, they still fall short in achieving realistic appearances. A key obstacle lies in the lack of diverse and high-quality real-world 3D assets with rich texture details, since capturing such data is intrinsically difficult due to the diverse scales of scenes, non-rigid motions of objects, and the limited precision of 3D scanners. We introduce Photo3D, a framework for advancing photorealistic 3D generation, which is driven by the image data generated by the GPT-4o-Image model. Considering that the generated images can distort 3D structures due to their lack of multi-view consistency, we design a structure-aligned multi-view synthesis pipeline and construct a detail-enhanced multi-view dataset paired with 3D geometry. Building on it, we present a realistic detail enhancement scheme that leverages perceptual feature adaptation and semantic structure matching to enforce appearance consistency with realistic details while preserving the structural consistency with the 3D-native geometry. Our scheme is general to different 3D-native generators, and we present dedicated training strategies to facilitate the optimization of geometry-texture coupled and decoupled 3D-native generation paradigms. Experiments demonstrate that Photo3D generalizes well across diverse 3D-native generation paradigms and achieves state-of-the-art photorealistic 3D generation performance.
EduBench: A Comprehensive Benchmarking Dataset for Evaluating Large Language Models in Diverse Educational Scenarios
May 22, 2025As large language models continue to advance, their application in educational contexts remains underexplored and under-optimized. In this paper, we address this gap by introducing the first diverse benchmark tailored for educational scenarios, incorporating synthetic data containing 9 major scenarios and over 4,000 distinct educational contexts. To enable comprehensive assessment, we propose a set of multi-dimensional evaluation metrics that cover 12 critical aspects relevant to both teachers and students. We further apply human annotation to ensure the effectiveness of the model-generated evaluation responses. Additionally, we succeed to train a relatively small-scale model on our constructed dataset and demonstrate that it can achieve performance comparable to state-of-the-art large models (e.g., Deepseek V3, Qwen Max) on the test set. Overall, this work provides a practical foundation for the development and evaluation of education-oriented language models. Code and data are released at https://github.com/ybai-nlp/EduBench.
Progressive Rendering Distillation: Adapting Stable Diffusion for Instant Text-to-Mesh Generation without 3D Data
Mar 27, 2025



It is highly desirable to obtain a model that can generate high-quality 3D meshes from text prompts in just seconds. While recent attempts have adapted pre-trained text-to-image diffusion models, such as Stable Diffusion (SD), into generators of 3D representations (e.g., Triplane), they often suffer from poor quality due to the lack of sufficient high-quality 3D training data. Aiming at overcoming the data shortage, we propose a novel training scheme, termed as Progressive Rendering Distillation (PRD), eliminating the need for 3D ground-truths by distilling multi-view diffusion models and adapting SD into a native 3D generator. In each iteration of training, PRD uses the U-Net to progressively denoise the latent from random noise for a few steps, and in each step it decodes the denoised latent into 3D output. Multi-view diffusion models, including MVDream and RichDreamer, are used in joint with SD to distill text-consistent textures and geometries into the 3D outputs through score distillation. Since PRD supports training without 3D ground-truths, we can easily scale up the training data and improve generation quality for challenging text prompts with creative concepts. Meanwhile, PRD can accelerate the inference speed of the generation model in just a few steps. With PRD, we train a Triplane generator, namely TriplaneTurbo, which adds only $2.5\%$ trainable parameters to adapt SD for Triplane generation. TriplaneTurbo outperforms previous text-to-3D generators in both efficiency and quality. Specifically, it can produce high-quality 3D meshes in 1.2 seconds and generalize well for challenging text input. The code is available at https://github.com/theEricMa/TriplaneTurbo.
Copy-Move Forgery Detection and Question Answering for Remote Sensing Image
Dec 03, 2024



This paper introduces the task of Remote Sensing Copy-Move Question Answering (RSCMQA). Unlike traditional Remote Sensing Visual Question Answering (RSVQA), RSCMQA focuses on interpreting complex tampering scenarios and inferring relationships between objects. Based on the practical needs of national defense security and land resource monitoring, we have developed an accurate and comprehensive global dataset for remote sensing image copy-move question answering, named RS-CMQA-2.1M. These images were collected from 29 different regions across 14 countries. Additionally, we have refined a balanced dataset, RS-CMQA-B, to address the long-standing issue of long-tail data in the remote sensing field. Furthermore, we propose a region-discriminative guided multimodal CMQA model, which enhances the accuracy of answering questions about tampered images by leveraging prompt about the differences and connections between the source and tampered domains. Extensive experiments demonstrate that our method provides a stronger benchmark for RS-CMQA compared to general VQA and RSVQA models. Our dataset and code are available at https://github.com/shenyedepisa/RSCMQA.
PSPO*: An Effective Process-supervised Policy Optimization for Reasoning Alignment
Nov 18, 2024



Process supervision enhances the performance of large language models in reasoning tasks by providing feedback at each step of chain-of-thought reasoning. However, due to the lack of effective process supervision methods, even advanced large language models are prone to logical errors and redundant reasoning. We claim that the effectiveness of process supervision significantly depends on both the accuracy and the length of reasoning chains. Moreover, we identify that these factors exhibit a nonlinear relationship with the overall reward score of the reasoning process. Inspired by these insights, we propose a novel process supervision paradigm, PSPO*, which systematically outlines the workflow from reward model training to policy optimization, and highlights the importance of nonlinear rewards in process supervision. Based on PSPO*, we develop the PSPO-WRS, which considers the number of reasoning steps in determining reward scores and utilizes an adjusted Weibull distribution for nonlinear reward shaping. Experimental results on six mathematical reasoning datasets demonstrate that PSPO-WRS consistently outperforms current mainstream models.
EfficientDreamer: High-Fidelity and Robust 3D Creation via Orthogonal-view Diffusion Prior
Aug 25, 2023



While the image diffusion model has made significant strides in text-driven 3D content creation, it often falls short in accurately capturing the intended meaning of the text prompt, particularly with respect to direction information. This shortcoming gives rise to the Janus problem, where multi-faced 3D models are produced with the guidance of such diffusion models. In this paper, we present a robust pipeline for generating high-fidelity 3D content with orthogonal-view image guidance. Specifically, we introduce a novel 2D diffusion model that generates an image consisting of four orthogonal-view sub-images for the given text prompt. The 3D content is then created with this diffusion model, which enhances 3D consistency and provides strong structured semantic priors. This addresses the infamous Janus problem and significantly promotes generation efficiency. Additionally, we employ a progressive 3D synthesis strategy that results in substantial improvement in the quality of the created 3D contents. Both quantitative and qualitative evaluations show that our method demonstrates a significant improvement over previous text-to-3D techniques.
Where and How: Mitigating Confusion in Neural Radiance Fields from Sparse Inputs
Aug 05, 2023Neural Radiance Fields from Sparse input} (NeRF-S) have shown great potential in synthesizing novel views with a limited number of observed viewpoints. However, due to the inherent limitations of sparse inputs and the gap between non-adjacent views, rendering results often suffer from over-fitting and foggy surfaces, a phenomenon we refer to as "CONFUSION" during volume rendering. In this paper, we analyze the root cause of this confusion and attribute it to two fundamental questions: "WHERE" and "HOW". To this end, we present a novel learning framework, WaH-NeRF, which effectively mitigates confusion by tackling the following challenges: (i)"WHERE" to Sample? in NeRF-S -- we introduce a Deformable Sampling strategy and a Weight-based Mutual Information Loss to address sample-position confusion arising from the limited number of viewpoints; and (ii) "HOW" to Predict? in NeRF-S -- we propose a Semi-Supervised NeRF learning Paradigm based on pose perturbation and a Pixel-Patch Correspondence Loss to alleviate prediction confusion caused by the disparity between training and testing viewpoints. By integrating our proposed modules and loss functions, WaH-NeRF outperforms previous methods under the NeRF-S setting. Code is available https://github.com/bbbbby-99/WaH-NeRF.
Use of Deterministic Transforms to Design Weight Matrices of a Neural Network
Oct 06, 2021

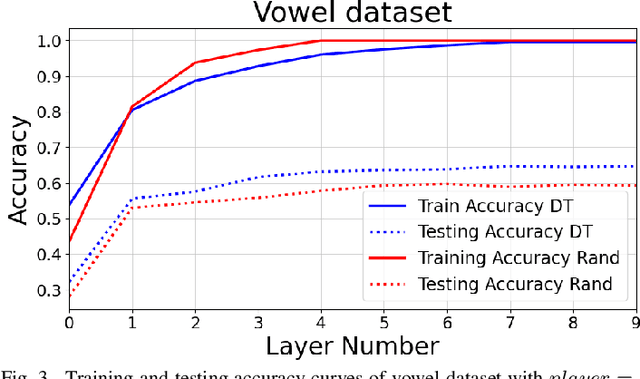

Self size-estimating feedforward network (SSFN) is a feedforward multilayer network. For the existing SSFN, a part of each weight matrix is trained using a layer-wise convex optimization approach (a supervised training), while the other part is chosen as a random matrix instance (an unsupervised training). In this article, the use of deterministic transforms instead of random matrix instances for the SSFN weight matrices is explored. The use of deterministic transforms provides a reduction in computational complexity. The use of several deterministic transforms is investigated, such as discrete cosine transform, Hadamard transform, Hartley transform, and wavelet transforms. The choice of a deterministic transform among a set of transforms is made in an unsupervised manner. To this end, two methods based on features' statistical parameters are developed. The proposed methods help to design a neural net where deterministic transforms can vary across its layers' weight matrices. The effectiveness of the proposed approach vis-a-vis the SSFN is illustrated for object classification tasks using several benchmark datasets.
A Low Complexity Decentralized Neural Net with Centralized Equivalence using Layer-wise Learning
Sep 29, 2020
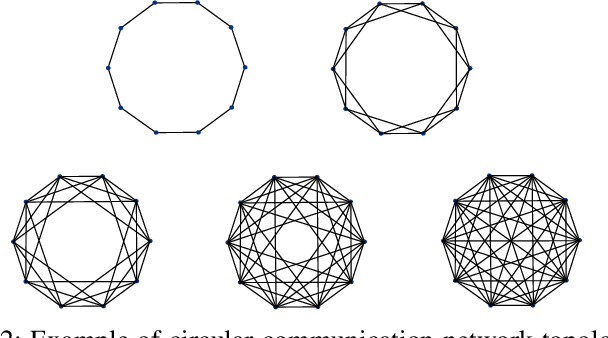

We design a low complexity decentralized learning algorithm to train a recently proposed large neural network in distributed processing nodes (workers). We assume the communication network between the workers is synchronized and can be modeled as a doubly-stochastic mixing matrix without having any master node. In our setup, the training data is distributed among the workers but is not shared in the training process due to privacy and security concerns. Using alternating-direction-method-of-multipliers (ADMM) along with a layerwise convex optimization approach, we propose a decentralized learning algorithm which enjoys low computational complexity and communication cost among the workers. We show that it is possible to achieve equivalent learning performance as if the data is available in a single place. Finally, we experimentally illustrate the time complexity and convergence behavior of the algorithm.
Predictive Analysis of COVID-19 Time-series Data from Johns Hopkins University
May 22, 2020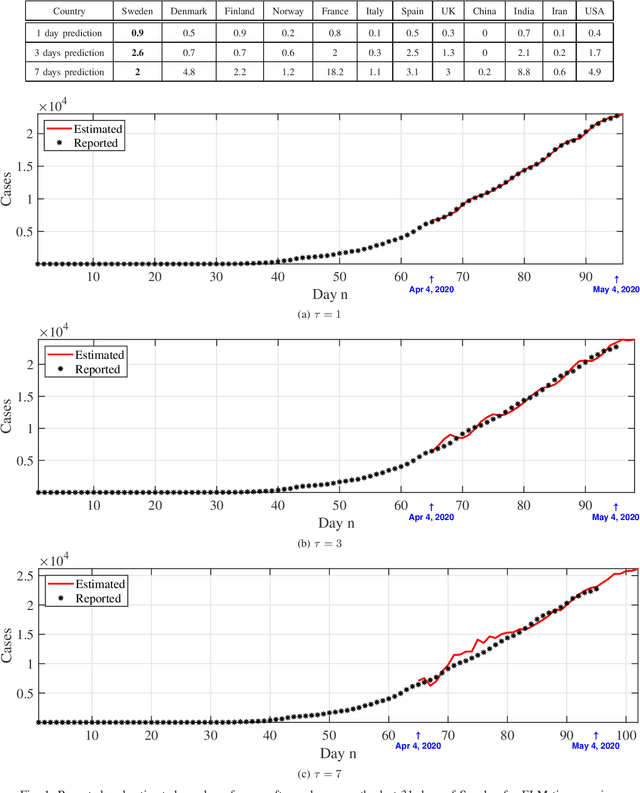
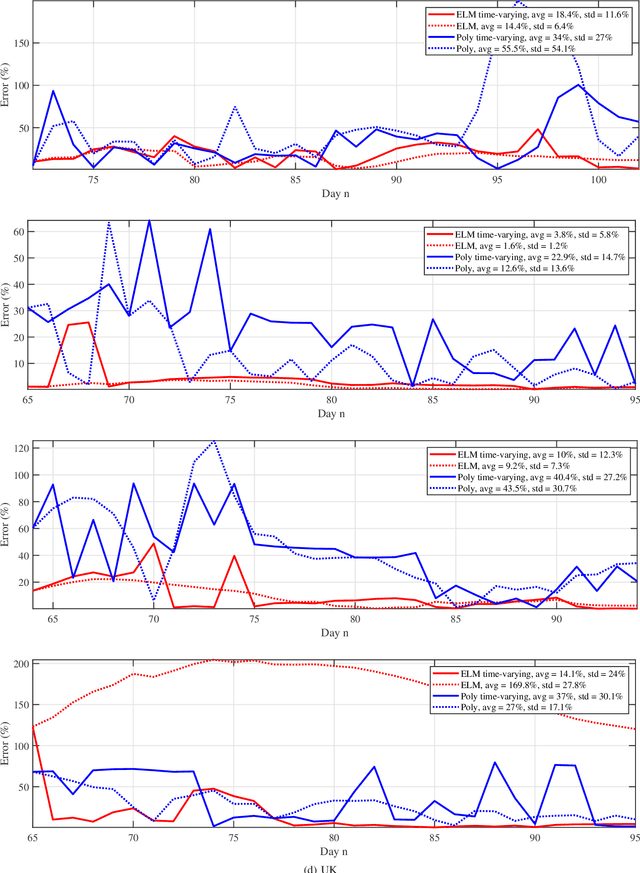
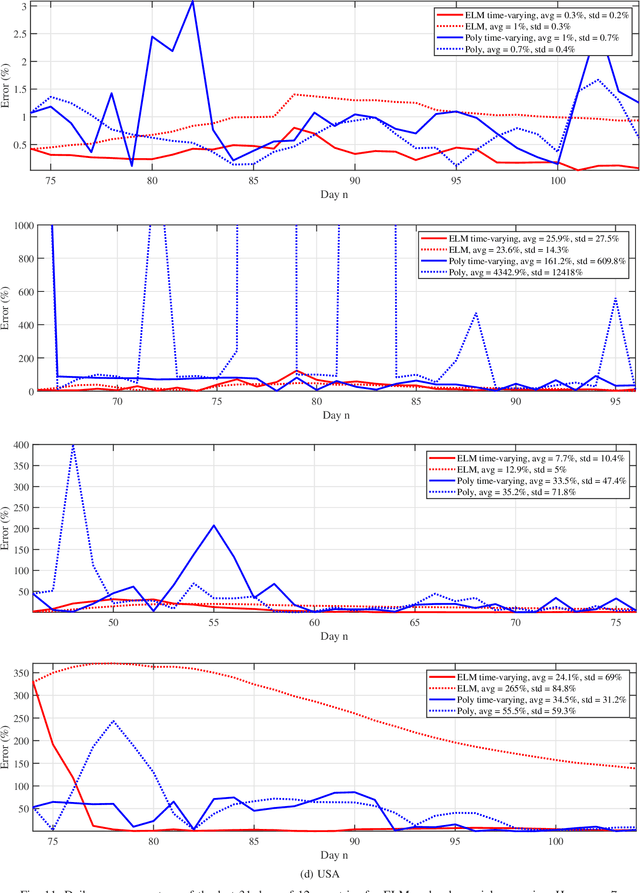
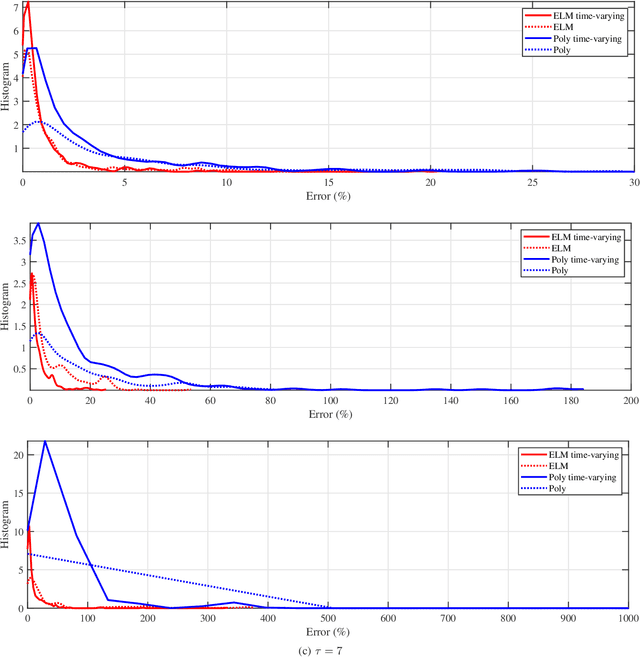
We provide a predictive analysis of the spread of COVID-19, also known as SARS-CoV-2, using the dataset made publicly available online by the Johns Hopkins University. Our main objective is to provide predictions of the number of infected people for different countries in the next 14 days. The predictive analysis is done using time-series data transformed on a logarithmic scale. We use two well-known methods for prediction: polynomial regression and neural network. As the number of training data for each country is limited, we use a single-layer neural network called the extreme learning machine (ELM) to avoid over-fitting. Due to the non-stationary nature of the time-series, a sliding window approach is used to provide a more accurate prediction.