 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Emotions in Prompts Matter? Effects of Emotional Framing on Large Language Models
Apr 02, 2026Emotional tone is pervasive in human communication, yet its influence on large language model (LLM) behaviour remains unclear. Here, we examine how first-person emotional framing in user-side queries affect LLM performance across six benchmark domains, including mathematical reasoning, medical question answering, reading comprehension, commonsense reasoning and social inference. Across models and tasks, static emotional prefixes usually produce only small changes in accuracy, suggesting that affective phrasing is typically a mild perturbation rather than a reliable general-purpose intervention. This stability is not uniform: effects are more variable in socially grounded tasks, where emotional context more plausibly interacts with interpersonal reasoning. Additional analyses show that stronger emotional wording induces only modest extra change, and that human-written prefixes reproduce the same qualitative pattern as LLM-generated ones. We then introduce EmotionRL, an adaptive emotional prompting framework that selects emotional framing adaptively for each query. Although no single emotion is consistently beneficial, adaptive selection yields more reliable gains than fixed emotional prompting. Together, these findings show that emotional tone is neither a dominant driver of LLM performance nor irrelevant noise, but a weak and input-dependent signal that can be exploited through adaptive control.
TrailBlazer: History-Guided Reinforcement Learning for Black-Box LLM Jailbreaking
Feb 06, 2026Large Language Models (LLMs) have become integral to many domains, making their safety a critical priority. Prior jailbreaking research has explored diverse approaches, including prompt optimization, automated red teaming, obfuscation, and reinforcement learning (RL) based methods. However, most existing techniques fail to effectively leverage vulnerabilities revealed in earlier interaction turns, resulting in inefficient and unstable attacks. Since jailbreaking involves sequential interactions in which each response influences future actions, reinforcement learning provides a natural framework for this problem. Motivated by this, we propose a history-aware RL-based jailbreak framework that analyzes and reweights vulnerability signals from prior steps to guide future decisions. We show that incorporating historical information alone improves jailbreak success rates. Building on this insight, we introduce an attention-based reweighting mechanism that highlights critical vulnerabilities within the interaction history, enabling more efficient exploration with fewer queries. Extensive experiments on AdvBench and HarmBench demonstrate that our method achieves state-of-the-art jailbreak performance while significantly improving query efficiency. These results underscore the importance of historical vulnerability signals in reinforcement learning-driven jailbreak strategies and offer a principled pathway for advancing adversarial research on LLM safeguards.
Grading Scale Impact on LLM-as-a-Judge: Human-LLM Alignment Is Highest on 0-5 Grading Scale
Jan 06, 2026Large language models (LLMs) are increasingly used as automated evaluators, yet prior works demonstrate that these LLM judges often lack consistency in scoring when the prompt is altered. However, the effect of the grading scale itself remains underexplored. We study the LLM-as-a-judge problem by comparing two kinds of raters: humans and LLMs. We collect ratings from both groups on three scales and across six benchmarks that include objective, open-ended subjective, and mixed tasks. Using intraclass correlation coefficients (ICC) to measure absolute agreement, we find that LLM judgments are not perfectly consistent across scales on subjective benchmarks, and that the choice of scale substantially shifts human-LLM agreement, even when within-group panel reliability is high. Aggregated over tasks, the grading scale of 0-5 yields the strongest human-LLM alignment. We further demonstrate that pooled reliability can mask benchmark heterogeneity and reveal systematic subgroup differences in alignment across gender groups, strengthening the importance of scale design and sub-level diagnostics as essential components of LLM-as-a-judge protocols.
EasyCraft: A Robust and Efficient Framework for Automatic Avatar Crafting
Mar 03, 2025Character customization, or 'face crafting,' is a vital feature in role-playing games (RPGs), enhancing player engagement by enabling the creation of personalized avatars. Existing automated methods often struggle with generalizability across diverse game engines due to their reliance on the intermediate constraints of specific image domain and typically support only one type of input, either text or image. To overcome these challenges, we introduce EasyCraft, an innovative end-to-end feedforward framework that automates character crafting by uniquely supporting both text and image inputs. Our approach employs a translator capable of converting facial images of any style into crafting parameters. We first establish a unified feature distribution in the translator's image encoder through self-supervised learning on a large-scale dataset, enabling photos of any style to be embedded into a unified feature representation. Subsequently, we map this unified feature distribution to crafting parameters specific to a game engine, a process that can be easily adapted to most game engines and thus enhances EasyCraft's generalizability. By integrating text-to-image techniques with our translator, EasyCraft also facilitates precise, text-based character crafting. EasyCraft's ability to integrate diverse inputs significantly enhances the versatility and accuracy of avatar creation. Extensive experiments on two RPG games demonstrate the effectiveness of our method, achieving state-of-the-art results and facilitating adaptability across various avatar engines.
Landscape of Policy Optimization for Finite Horizon MDPs with General State and Action
Sep 25, 2024Policy gradient methods are widely used in reinforcement learning. Yet, the nonconvexity of policy optimization imposes significant challenges in understanding the global convergence of policy gradient methods. For a class of finite-horizon Markov Decision Processes (MDPs) with general state and action spaces, we develop a framework that provides a set of easily verifiable assumptions to ensure the Kurdyka-Lojasiewicz (KL) condition of the policy optimization. Leveraging the KL condition, policy gradient methods converge to the globally optimal policy with a non-asymptomatic rate despite nonconvexity. Our results find applications in various control and operations models, including entropy-regularized tabular MDPs, Linear Quadratic Regulator (LQR) problems, stochastic inventory models, and stochastic cash balance problems, for which we show an $\epsilon$-optimal policy can be obtained using a sample size in $\tilde{\mathcal{O}}(\epsilon^{-1})$ and polynomial in terms of the planning horizon by stochastic policy gradient methods. Our result establishes the first sample complexity for multi-period inventory systems with Markov-modulated demands and stochastic cash balance problems in the literature.
EfficientDreamer: High-Fidelity and Robust 3D Creation via Orthogonal-view Diffusion Prior
Aug 25, 2023



While the image diffusion model has made significant strides in text-driven 3D content creation, it often falls short in accurately capturing the intended meaning of the text prompt, particularly with respect to direction information. This shortcoming gives rise to the Janus problem, where multi-faced 3D models are produced with the guidance of such diffusion models. In this paper, we present a robust pipeline for generating high-fidelity 3D content with orthogonal-view image guidance. Specifically, we introduce a novel 2D diffusion model that generates an image consisting of four orthogonal-view sub-images for the given text prompt. The 3D content is then created with this diffusion model, which enhances 3D consistency and provides strong structured semantic priors. This addresses the infamous Janus problem and significantly promotes generation efficiency. Additionally, we employ a progressive 3D synthesis strategy that results in substantial improvement in the quality of the created 3D contents. Both quantitative and qualitative evaluations show that our method demonstrates a significant improvement over previous text-to-3D techniques.
Beyond First Impressions: Integrating Joint Multi-modal Cues for Comprehensive 3D Representation
Aug 06, 2023

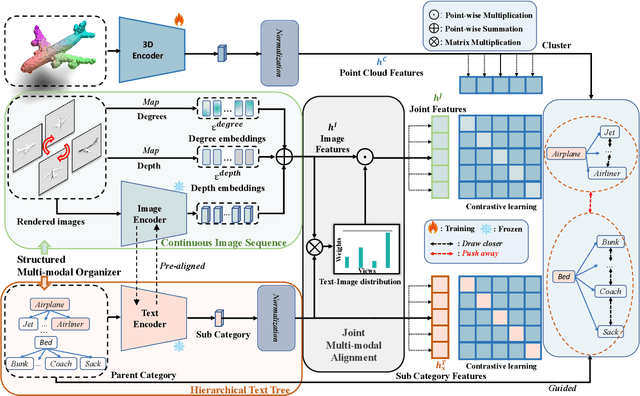

In recent years, 3D representation learning has turned to 2D vision-language pre-trained models to overcome data scarcity challenges. However, existing methods simply transfer 2D alignment strategies, aligning 3D representations with single-view 2D images and coarse-grained parent category text. These approaches introduce information degradation and insufficient synergy issues, leading to performance loss. Information degradation arises from overlooking the fact that a 3D representation should be equivalent to a series of multi-view images and more fine-grained subcategory text. Insufficient synergy neglects the idea that a robust 3D representation should align with the joint vision-language space, rather than independently aligning with each modality. In this paper, we propose a multi-view joint modality modeling approach, termed JM3D, to obtain a unified representation for point cloud, text, and image. Specifically, a novel Structured Multimodal Organizer (SMO) is proposed to address the information degradation issue, which introduces contiguous multi-view images and hierarchical text to enrich the representation of vision and language modalities. A Joint Multi-modal Alignment (JMA) is designed to tackle the insufficient synergy problem, which models the joint modality by incorporating language knowledge into the visual modality. Extensive experiments on ModelNet40 and ScanObjectNN demonstrate the effectiveness of our proposed method, JM3D, which achieves state-of-the-art performance in zero-shot 3D classification. JM3D outperforms ULIP by approximately 4.3% on PointMLP and achieves an improvement of up to 6.5% accuracy on PointNet++ in top-1 accuracy for zero-shot 3D classification on ModelNet40. The source code and trained models for all our experiments are publicly available at https://github.com/Mr-Neko/JM3D.
Stochastic Steffensen method
Nov 28, 2022
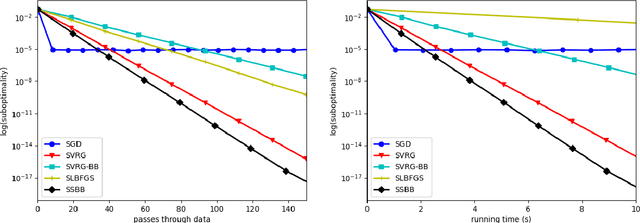
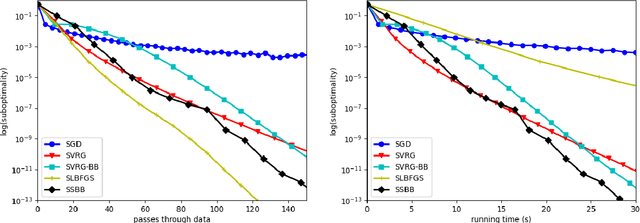
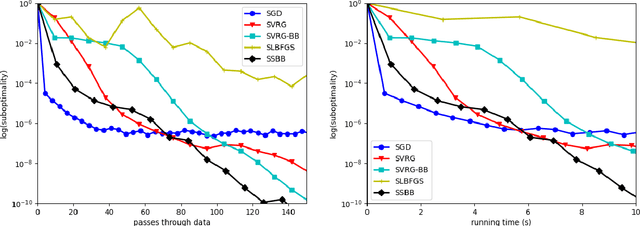
Is it possible for a first-order method, i.e., only first derivatives allowed, to be quadratically convergent? For univariate loss functions, the answer is yes -- the Steffensen method avoids second derivatives and is still quadratically convergent like Newton method. By incorporating an optimal step size we can even push its convergence order beyond quadratic to $1+\sqrt{2} \approx 2.414$. While such high convergence orders are a pointless overkill for a deterministic algorithm, they become rewarding when the algorithm is randomized for problems of massive sizes, as randomization invariably compromises convergence speed. We will introduce two adaptive learning rates inspired by the Steffensen method, intended for use in a stochastic optimization setting and requires no hyperparameter tuning aside from batch size. Extensive experiments show that they compare favorably with several existing first-order methods. When restricted to a quadratic objective, our stochastic Steffensen methods reduce to randomized Kaczmarz method -- note that this is not true for SGD or SLBFGS -- and thus we may also view our methods as a generalization of randomized Kaczmarz to arbitrary objectives.
Adaptively Meshed Video Stabilization
Jun 14, 2020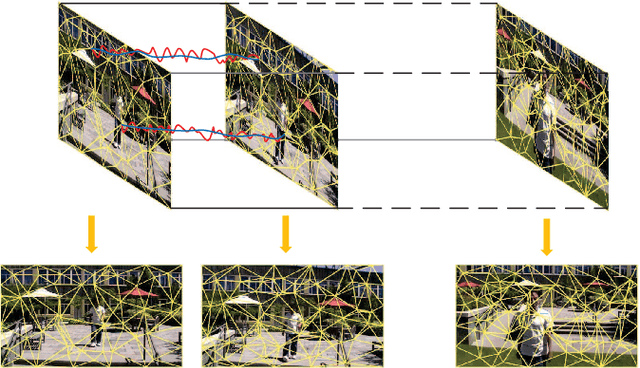
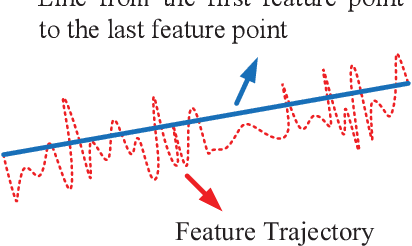

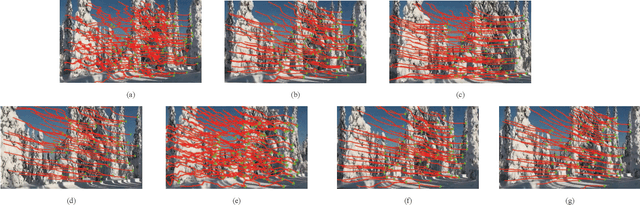
Video stabilization is essential for improving visual quality of shaky videos. The current video stabilization methods usually take feature trajectories in the background to estimate one global transformation matrix or several transformation matrices based on a fixed mesh, and warp shaky frames into their stabilized views. However, these methods may not model the shaky camera motion well in complicated scenes, such as scenes containing large foreground objects or strong parallax, and may result in notable visual artifacts in the stabilized videos. To resolve the above issues, this paper proposes an adaptively meshed method to stabilize a shaky video based on all of its feature trajectories and an adaptive blocking strategy. More specifically, we first extract feature trajectories of the shaky video and then generate a triangle mesh according to the distribution of the feature trajectories in each frame. Then transformations between shaky frames and their stabilized views over all triangular grids of the mesh are calculated to stabilize the shaky video. Since more feature trajectories can usually be extracted from all regions, including both background and foreground regions, a finer mesh will be obtained and provided for camera motion estimation and frame warping. We estimate the mesh-based transformations of each frame by solving a two-stage optimization problem. Moreover, foreground and background feature trajectories are no longer distinguished and both contribute to the estimation of the camera motion in the proposed optimization problem, which yields better estimation performance than previous works, particularly in challenging videos with large foreground objects or strong parallax.