 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyGenNet: An Efficient Framework for Audio-Driven Gesture Video Generation Based on Diffusion Model
Apr 11, 2025Audio-driven cospeech video generation typically involves two stages: speech-to-gesture and gesture-to-video. While significant advances have been made in speech-to-gesture generation, synthesizing natural expressions and gestures remains challenging in gesture-to-video systems. In order to improve the generation effect, previous works adopted complex input and training strategies and required a large amount of data sets for pre-training, which brought inconvenience to practical applications. We propose a simple one-stage training method and a temporal inference method based on a diffusion model to synthesize realistic and continuous gesture videos without the need for additional training of temporal modules.The entire model makes use of existing pre-trained weights, and only a few thousand frames of data are needed for each character at a time to complete fine-tuning. Built upon the video generator, we introduce a new audio-to-video pipeline to synthesize co-speech videos, using 2D human skeleton as the intermediate motion representation. Our experiments show that our method outperforms existing GAN-based and diffusion-based methods.
Data-free Knowledge Distillation with Diffusion Models
Apr 01, 2025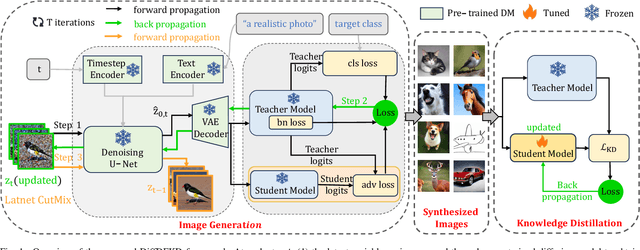
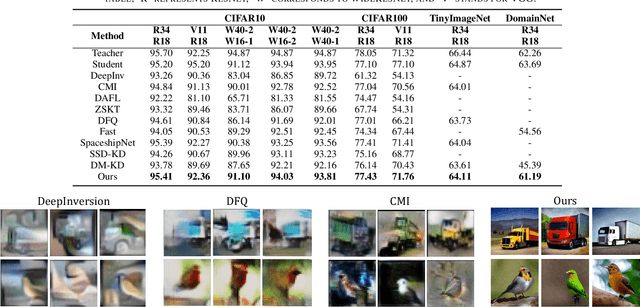
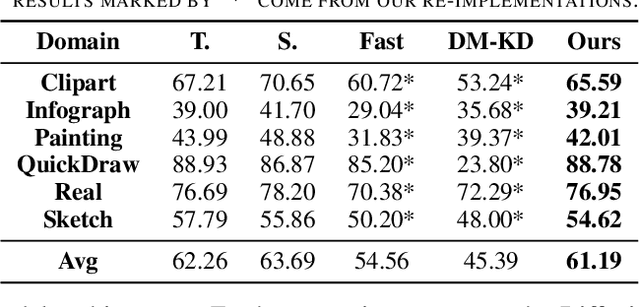

Recently Data-Free Knowledge Distillation (DFKD) has garnered attention and can transfer knowledge from a teacher neural network to a student neural network without requiring any access to training data. Although diffusion models are adept at synthesizing high-fidelity photorealistic images across various domains, existing methods cannot be easiliy implemented to DFKD. To bridge that gap, this paper proposes a novel approach based on diffusion models, DiffDFKD. Specifically, DiffDFKD involves targeted optimizations in two key areas. Firstly, DiffDFKD utilizes valuable information from teacher models to guide the pre-trained diffusion models' data synthesis, generating datasets that mirror the training data distribution and effectively bridge domain gaps. Secondly, to reduce computational burdens, DiffDFKD introduces Latent CutMix Augmentation, an efficient technique, to enhance the diversity of diffusion model-generated images for DFKD while preserving key attributes for effective knowledge transfer. Extensive experiments validate the efficacy of DiffDFKD, yielding state-of-the-art results exceeding existing DFKD approaches. We release our code at https://github.com/xhqi0109/DiffDFKD.
PromptDet: A Lightweight 3D Object Detection Framework with LiDAR Prompts
Dec 17, 2024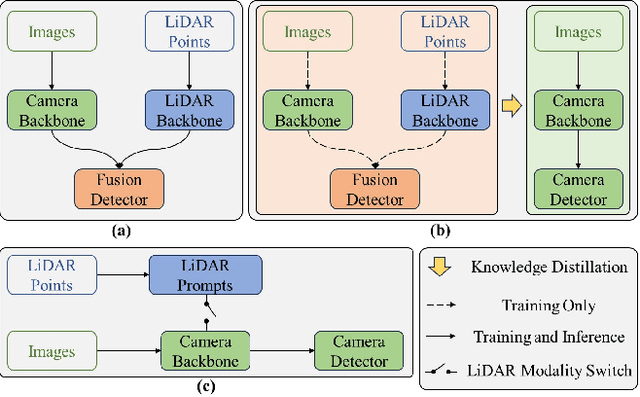
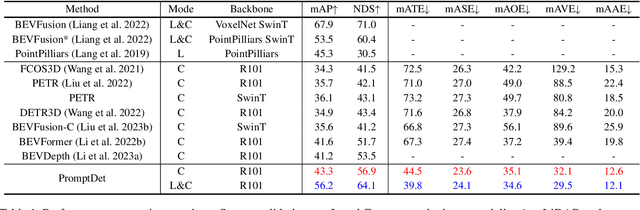
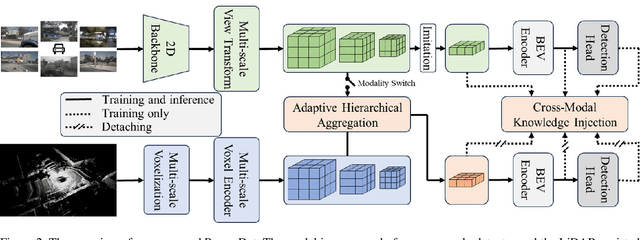
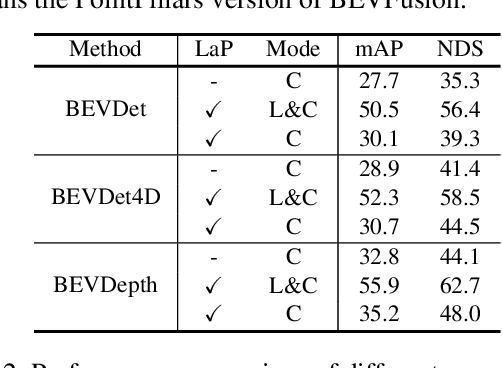
Multi-camera 3D object detection aims to detect and localize objects in 3D space using multiple cameras, which has attracted more attention due to its cost-effectiveness trade-off. However, these methods often struggle with the lack of accurate depth estimation caused by the natural weakness of the camera in ranging. Recently, multi-modal fusion and knowledge distillation methods for 3D object detection have been proposed to solve this problem, which are time-consuming during the training phase and not friendly to memory cost. In light of this, we propose PromptDet, a lightweight yet effective 3D object detection framework motivated by the success of prompt learning in 2D foundation model. Our proposed framework, PromptDet, comprises two integral components: a general camera-based detection module, exemplified by models like BEVDet and BEVDepth, and a LiDAR-assisted prompter. The LiDAR-assisted prompter leverages the LiDAR points as a complementary signal, enriched with a minimal set of additional trainable parameters. Notably, our framework is flexible due to our prompt-like design, which can not only be used as a lightweight multi-modal fusion method but also as a camera-only method for 3D object detection during the inference phase. Extensive experiments on nuScenes validate the effectiveness of the proposed PromptDet. As a multi-modal detector, PromptDet improves the mAP and NDS by at most 22.8\% and 21.1\% with fewer than 2\% extra parameters compared with the camera-only baseline. Without LiDAR points, PromptDet still achieves an improvement of at most 2.4\% mAP and 4.0\% NDS with almost no impact on camera detection inference time.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.
You Only Train Once: Learning a General Anomaly Enhancement Network with Random Masks for Hyperspectral Anomaly Detection
Mar 31, 2023



In this paper, we introduce a new approach to address the challenge of generalization in hyperspectral anomaly detection (AD). Our method eliminates the need for adjusting parameters or retraining on new test scenes as required by most existing methods. Employing an image-level training paradigm, we achieve a general anomaly enhancement network for hyperspectral AD that only needs to be trained once. Trained on a set of anomaly-free hyperspectral images with random masks, our network can learn the spatial context characteristics between anomalies and background in an unsupervised way. Additionally, a plug-and-play model selection module is proposed to search for a spatial-spectral transform domain that is more suitable for AD task than the original data. To establish a unified benchmark to comprehensively evaluate our method and existing methods, we develop a large-scale hyperspectral AD dataset (HAD100) that includes 100 real test scenes with diverse anomaly targets. In comparison experiments, we combine our network with a parameter-free detector and achieve the optimal balance between detection accuracy and inference speed among state-of-the-art AD methods. Experimental results also show that our method still achieves competitive performance when the training and test set are captured by different sensor devices. Our code is available at https://github.com/ZhaoxuLi123/AETNet.
Ranking-Based Siamese Visual Tracking
May 24, 2022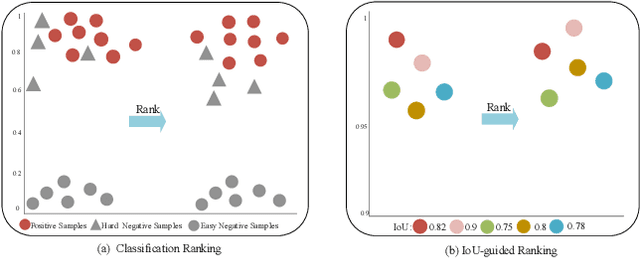



Current Siamese-based trackers mainly formulate the visual tracking into two independent subtasks, including classification and localization. They learn the classification subnetwork by processing each sample separately and neglect the relationship among positive and negative samples. Moreover, such tracking paradigm takes only the classification confidence of proposals for the final prediction, which may yield the misalignment between classification and localization. To resolve these issues, this paper proposes a ranking-based optimization algorithm to explore the relationship among different proposals. To this end, we introduce two ranking losses, including the classification one and the IoU-guided one, as optimization constraints. The classification ranking loss can ensure that positive samples rank higher than hard negative ones, i.e., distractors, so that the trackers can select the foreground samples successfully without being fooled by the distractors. The IoU-guided ranking loss aims to align classification confidence scores with the Intersection over Union(IoU) of the corresponding localization prediction for positive samples, enabling the well-localized prediction to be represented by high classification confidence. Specifically, the proposed two ranking losses are compatible with most Siamese trackers and incur no additional computation for inference. Extensive experiments on seven tracking benchmarks, including OTB100, UAV123, TC128, VOT2016, NFS30, GOT-10k and LaSOT, demonstrate the effectiveness of the proposed ranking-based optimization algorithm. The code and raw results are available at https://github.com/sansanfree/RBO.
Multi-model Ensemble Learning Method for Human Expression Recognition
Mar 28, 2022



Analysis of human affect plays a vital role in human-computer interaction (HCI) systems. Due to the difficulty in capturing large amounts of real-life data, most of the current methods have mainly focused on controlled environments, which limit their application scenarios. To tackle this problem, we propose our solution based on the ensemble learning method. Specifically, we formulate the problem as a classification task, and then train several expression classification models with different types of backbones--ResNet, EfficientNet and InceptionNet. After that, the outputs of several models are fused via model ensemble method to predict the final results. Moreover, we introduce the multi-fold ensemble method to train and ensemble several models with the same architecture but different data distributions to enhance the performance of our solution. We conduct many experiments on the AffWild2 dataset of the ABAW2022 Challenge, and the results demonstrate the effectiveness of our solution.
Cognitive Diagnosis with Explicit Student Vector Estimation and Unsupervised Question Matrix Learning
Mar 01, 2022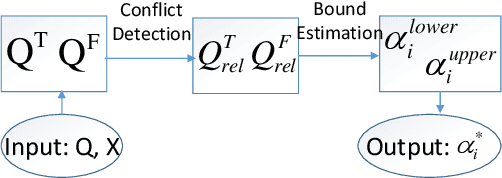
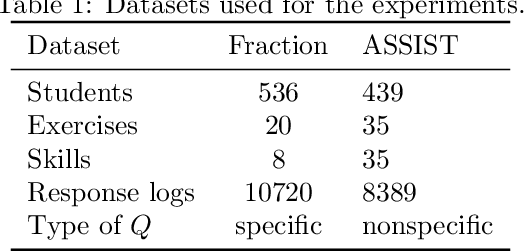
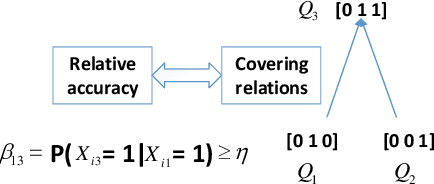
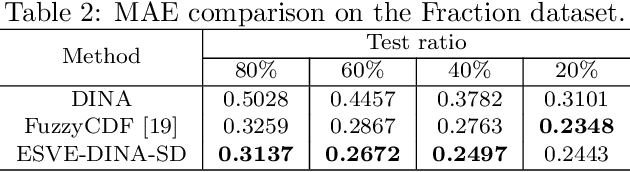
Cognitive diagnosis is an essential task in many educational applications. Many solutions have been designed in the literature. The deterministic input, noisy "and" gate (DINA) model is a classical cognitive diagnosis model and can provide interpretable cognitive parameters, e.g., student vectors. However, the assumption of the probabilistic part of DINA is too strong, because it assumes that the slip and guess rates of questions are student-independent. Besides, the question matrix (i.e., Q-matrix) recording the skill distribution of the questions in the cognitive diagnosis domain often requires precise labels given by domain experts. Thus, we propose an explicit student vector estimation (ESVE) method to estimate the student vectors of DINA with a local self-consistent test, which does not rely on any assumptions for the probabilistic part of DINA. Then, based on the estimated student vectors, the probabilistic part of DINA can be modified to a student dependent model that the slip and guess rates are related to student vectors. Furthermore, we propose an unsupervised method called heuristic bidirectional calibration algorithm (HBCA) to label the Q-matrix automatically, which connects the question difficulty relation and the answer results for initialization and uses the fault tolerance of ESVE-DINA for calibration. The experimental results on two real-world datasets show that ESVE-DINA outperforms the DINA model on accuracy and that the Q-matrix labeled automatically by HBCA can achieve performance comparable to that obtained with the manually labeled Q-matrix when using the same model structure.
BiSTF: Bilateral-Branch Self-Training Framework for Semi-Supervised Large-scale Fine-Grained Recognition
Jul 14, 2021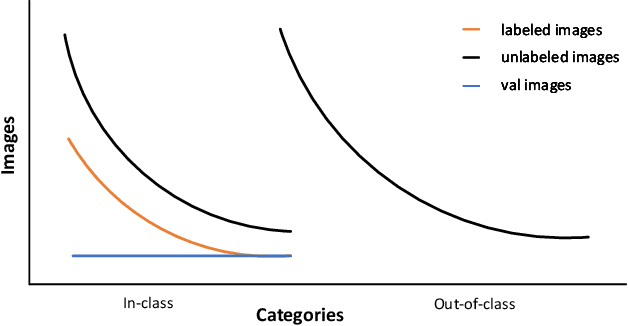
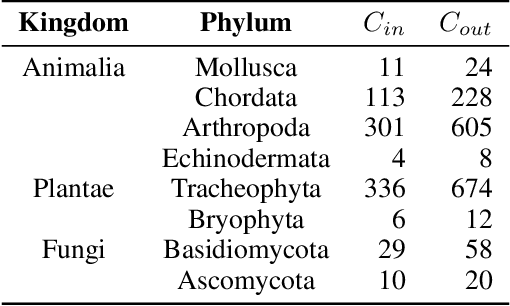
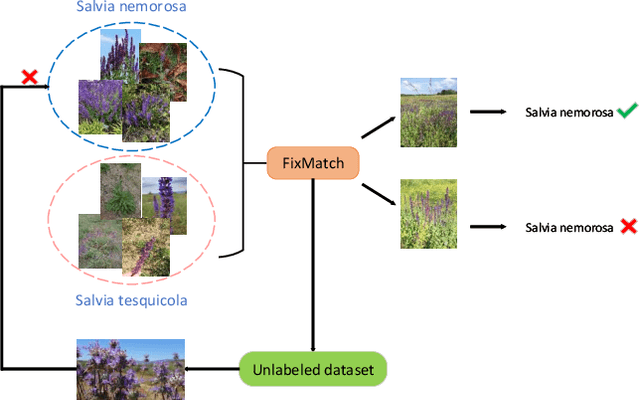
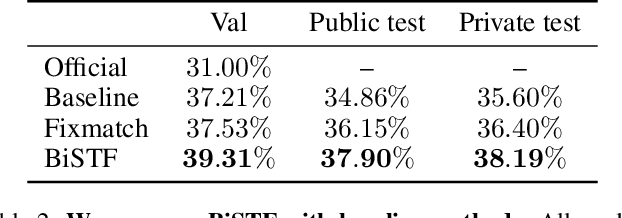
Semi-supervised Fine-Grained Recognition is a challenge task due to the difficulty of data imbalance, high inter-class similarity and domain mismatch. Recent years, this field has witnessed great progress and many methods has gained great performance. However, these methods can hardly generalize to the large-scale datasets, such as Semi-iNat, as they are prone to suffer from noise in unlabeled data and the incompetence for learning features from imbalanced fine-grained data. In this work, we propose Bilateral-Branch Self-Training Framework (BiSTF), a simple yet effective framework to improve existing semi-supervised learning methods on class-imbalanced and domain-shifted fine-grained data. By adjusting the update frequency through stochastic epoch update, BiSTF iteratively retrains a baseline SSL model with a labeled set expanded by selectively adding pseudo-labeled samples from an unlabeled set, where the distribution of pseudo-labeled samples are the same as the labeled data. We show that BiSTF outperforms the existing state-of-the-art SSL algorithm on Semi-iNat dataset.
Adaptively Meshed Video Stabilization
Jun 14, 2020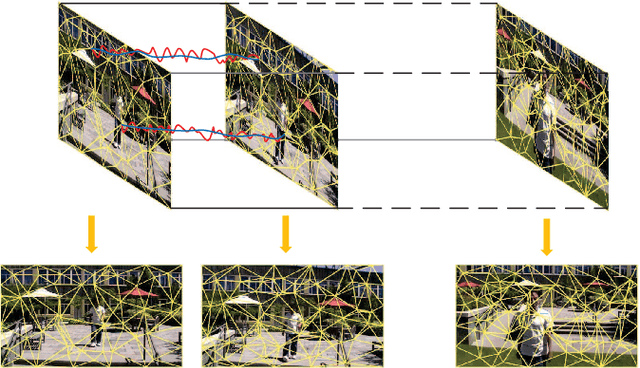
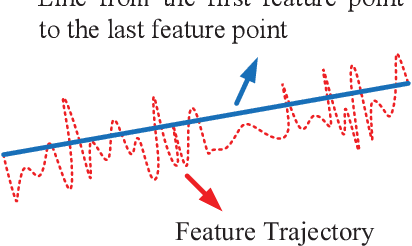

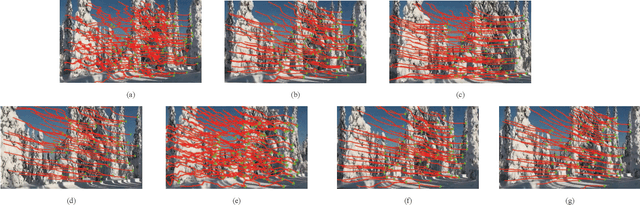
Video stabilization is essential for improving visual quality of shaky videos. The current video stabilization methods usually take feature trajectories in the background to estimate one global transformation matrix or several transformation matrices based on a fixed mesh, and warp shaky frames into their stabilized views. However, these methods may not model the shaky camera motion well in complicated scenes, such as scenes containing large foreground objects or strong parallax, and may result in notable visual artifacts in the stabilized videos. To resolve the above issues, this paper proposes an adaptively meshed method to stabilize a shaky video based on all of its feature trajectories and an adaptive blocking strategy. More specifically, we first extract feature trajectories of the shaky video and then generate a triangle mesh according to the distribution of the feature trajectories in each frame. Then transformations between shaky frames and their stabilized views over all triangular grids of the mesh are calculated to stabilize the shaky video. Since more feature trajectories can usually be extracted from all regions, including both background and foreground regions, a finer mesh will be obtained and provided for camera motion estimation and frame warping. We estimate the mesh-based transformations of each frame by solving a two-stage optimization problem. Moreover, foreground and background feature trajectories are no longer distinguished and both contribute to the estimation of the camera motion in the proposed optimization problem, which yields better estimation performance than previous works, particularly in challenging videos with large foreground objects or strong parallax.