 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyGenNet: An Efficient Framework for Audio-Driven Gesture Video Generation Based on Diffusion Model
Apr 11, 2025Audio-driven cospeech video generation typically involves two stages: speech-to-gesture and gesture-to-video. While significant advances have been made in speech-to-gesture generation, synthesizing natural expressions and gestures remains challenging in gesture-to-video systems. In order to improve the generation effect, previous works adopted complex input and training strategies and required a large amount of data sets for pre-training, which brought inconvenience to practical applications. We propose a simple one-stage training method and a temporal inference method based on a diffusion model to synthesize realistic and continuous gesture videos without the need for additional training of temporal modules.The entire model makes use of existing pre-trained weights, and only a few thousand frames of data are needed for each character at a time to complete fine-tuning. Built upon the video generator, we introduce a new audio-to-video pipeline to synthesize co-speech videos, using 2D human skeleton as the intermediate motion representation. Our experiments show that our method outperforms existing GAN-based and diffusion-based methods.
Data-free Knowledge Distillation with Diffusion Models
Apr 01, 2025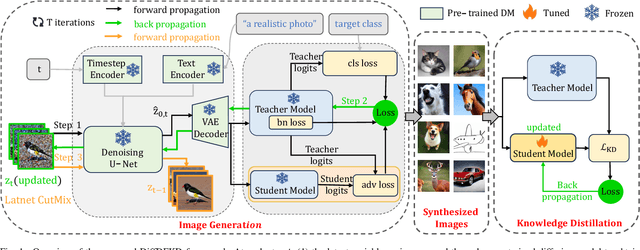
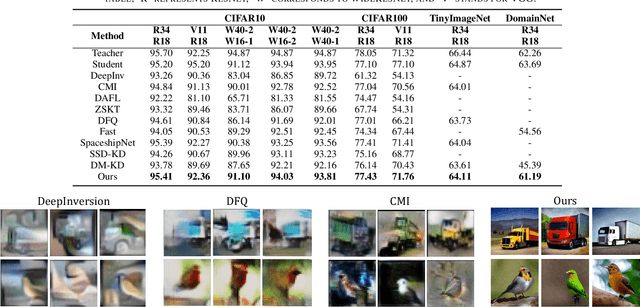
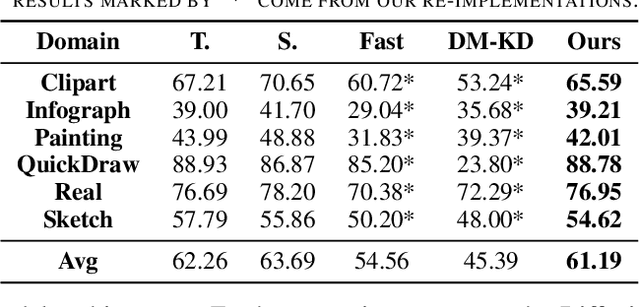

Recently Data-Free Knowledge Distillation (DFKD) has garnered attention and can transfer knowledge from a teacher neural network to a student neural network without requiring any access to training data. Although diffusion models are adept at synthesizing high-fidelity photorealistic images across various domains, existing methods cannot be easiliy implemented to DFKD. To bridge that gap, this paper proposes a novel approach based on diffusion models, DiffDFKD. Specifically, DiffDFKD involves targeted optimizations in two key areas. Firstly, DiffDFKD utilizes valuable information from teacher models to guide the pre-trained diffusion models' data synthesis, generating datasets that mirror the training data distribution and effectively bridge domain gaps. Secondly, to reduce computational burdens, DiffDFKD introduces Latent CutMix Augmentation, an efficient technique, to enhance the diversity of diffusion model-generated images for DFKD while preserving key attributes for effective knowledge transfer. Extensive experiments validate the efficacy of DiffDFKD, yielding state-of-the-art results exceeding existing DFKD approaches. We release our code at https://github.com/xhqi0109/DiffDFKD.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.
Federated Generative Learning with Foundation Models
Jun 28, 2023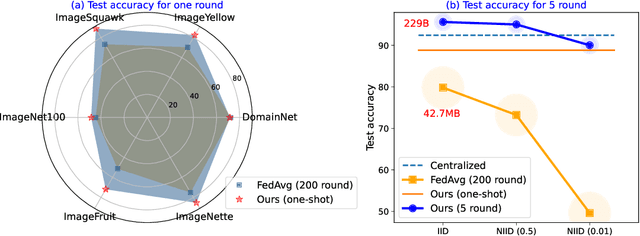



Existing federated learning solutions focus on transmitting features, parameters or gadients between clients and server, which suffer from serious low-efficiency and privacy-leakage problems. Thanks to the emerging foundation generative models, we propose a novel federated learning framework, namely Federated Generative Learning, that transmits prompts associated with distributed training data between clients and server. The informative training data can be synthesized remotely based on received prompts containing little privacy and the foundation generative models. The new framework possesses multiple advantages, including improved communication efficiency, better resilience to distribution shift, substantial performance gains, and enhanced privacy protection, which are verified in extensive experiments on ImageNet and DomainNet datasets.
The Second Monocular Depth Estimation Challenge
Apr 26, 2023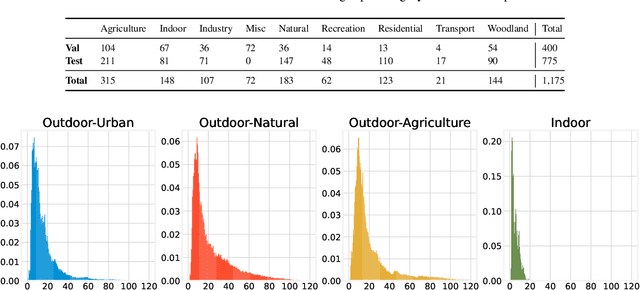
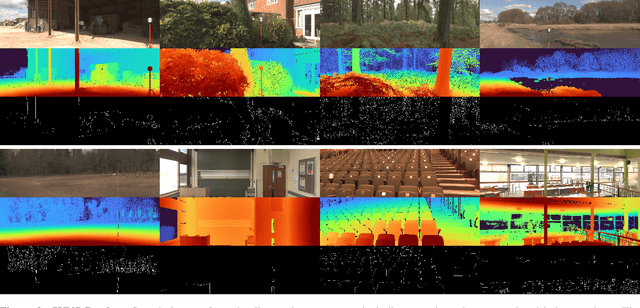
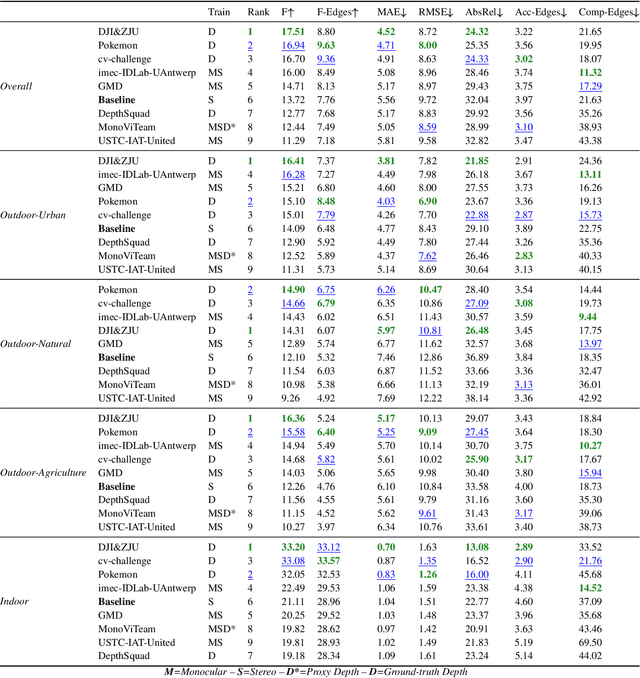
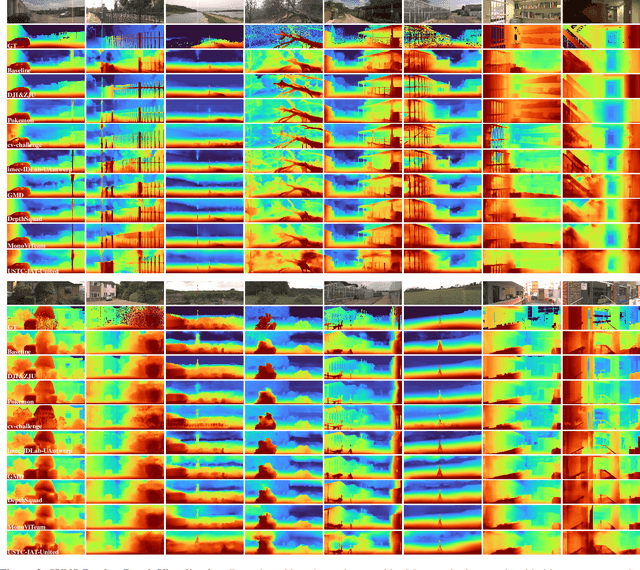
This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.