 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Forging Spatial Intelligence: A Roadmap of Multi-Modal Data Pre-Training for Autonomous Systems
Dec 30, 2025The rapid advancement of autonomous systems, including self-driving vehicles and drones, has intensified the need to forge true Spatial Intelligence from multi-modal onboard sensor data. While foundation models excel in single-modal contexts, integrating their capabilities across diverse sensors like cameras and LiDAR to create a unified understanding remains a formidable challenge. This paper presents a comprehensive framework for multi-modal pre-training, identifying the core set of techniques driving progress toward this goal. We dissect the interplay between foundational sensor characteristics and learning strategies, evaluating the role of platform-specific datasets in enabling these advancements. Our central contribution is the formulation of a unified taxonomy for pre-training paradigms: ranging from single-modality baselines to sophisticated unified frameworks that learn holistic representations for advanced tasks like 3D object detection and semantic occupancy prediction. Furthermore, we investigate the integration of textual inputs and occupancy representations to facilitate open-world perception and planning. Finally, we identify critical bottlenecks, such as computational efficiency and model scalability, and propose a roadmap toward general-purpose multi-modal foundation models capable of achieving robust Spatial Intelligence for real-world deployment.
Vision-Language-Action Models for Autonomous Driving: Past, Present, and Future
Dec 18, 2025Autonomous driving has long relied on modular "Perception-Decision-Action" pipelines, where hand-crafted interfaces and rule-based components often break down in complex or long-tailed scenarios. Their cascaded design further propagates perception errors, degrading downstream planning and control. Vision-Action (VA) models address some limitations by learning direct mappings from visual inputs to actions, but they remain opaque, sensitive to distribution shifts, and lack structured reasoning or instruction-following capabilities. Recent progress in Large Language Models (LLMs) and multimodal learning has motivated the emergence of Vision-Language-Action (VLA) frameworks, which integrate perception with language-grounded decision making. By unifying visual understanding, linguistic reasoning, and actionable outputs, VLAs offer a pathway toward more interpretable, generalizable, and human-aligned driving policies. This work provides a structured characterization of the emerging VLA landscape for autonomous driving. We trace the evolution from early VA approaches to modern VLA frameworks and organize existing methods into two principal paradigms: End-to-End VLA, which integrates perception, reasoning, and planning within a single model, and Dual-System VLA, which separates slow deliberation (via VLMs) from fast, safety-critical execution (via planners). Within these paradigms, we further distinguish subclasses such as textual vs. numerical action generators and explicit vs. implicit guidance mechanisms. We also summarize representative datasets and benchmarks for evaluating VLA-based driving systems and highlight key challenges and open directions, including robustness, interpretability, and instruction fidelity. Overall, this work aims to establish a coherent foundation for advancing human-compatible autonomous driving systems.
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Dec 11, 2025Generative world models are reshaping embodied AI, enabling agents to synthesize realistic 4D driving environments that look convincing but often fail physically or behaviorally. Despite rapid progress, the field still lacks a unified way to assess whether generated worlds preserve geometry, obey physics, or support reliable control. We introduce WorldLens, a full-spectrum benchmark evaluating how well a model builds, understands, and behaves within its generated world. It spans five aspects -- Generation, Reconstruction, Action-Following, Downstream Task, and Human Preference -- jointly covering visual realism, geometric consistency, physical plausibility, and functional reliability. Across these dimensions, no existing world model excels universally: those with strong textures often violate physics, while geometry-stable ones lack behavioral fidelity. To align objective metrics with human judgment, we further construct WorldLens-26K, a large-scale dataset of human-annotated videos with numerical scores and textual rationales, and develop WorldLens-Agent, an evaluation model distilled from these annotations to enable scalable, explainable scoring. Together, the benchmark, dataset, and agent form a unified ecosystem for measuring world fidelity -- standardizing how future models are judged not only by how real they look, but by how real they behave.
Learning to Remove Lens Flare in Event Camera
Dec 09, 2025Event cameras have the potential to revolutionize vision systems with their high temporal resolution and dynamic range, yet they remain susceptible to lens flare, a fundamental optical artifact that causes severe degradation. In event streams, this optical artifact forms a complex, spatio-temporal distortion that has been largely overlooked. We present E-Deflare, the first systematic framework for removing lens flare from event camera data. We first establish the theoretical foundation by deriving a physics-grounded forward model of the non-linear suppression mechanism. This insight enables the creation of the E-Deflare Benchmark, a comprehensive resource featuring a large-scale simulated training set, E-Flare-2.7K, and the first-ever paired real-world test set, E-Flare-R, captured by our novel optical system. Empowered by this benchmark, we design E-DeflareNet, which achieves state-of-the-art restoration performance. Extensive experiments validate our approach and demonstrate clear benefits for downstream tasks. Code and datasets are publicly available.
SEE4D: Pose-Free 4D Generation via Auto-Regressive Video Inpainting
Oct 30, 2025Immersive applications call for synthesizing spatiotemporal 4D content from casual videos without costly 3D supervision. Existing video-to-4D methods typically rely on manually annotated camera poses, which are labor-intensive and brittle for in-the-wild footage. Recent warp-then-inpaint approaches mitigate the need for pose labels by warping input frames along a novel camera trajectory and using an inpainting model to fill missing regions, thereby depicting the 4D scene from diverse viewpoints. However, this trajectory-to-trajectory formulation often entangles camera motion with scene dynamics and complicates both modeling and inference. We introduce SEE4D, a pose-free, trajectory-to-camera framework that replaces explicit trajectory prediction with rendering to a bank of fixed virtual cameras, thereby separating camera control from scene modeling. A view-conditional video inpainting model is trained to learn a robust geometry prior by denoising realistically synthesized warped images and to inpaint occluded or missing regions across virtual viewpoints, eliminating the need for explicit 3D annotations. Building on this inpainting core, we design a spatiotemporal autoregressive inference pipeline that traverses virtual-camera splines and extends videos with overlapping windows, enabling coherent generation at bounded per-step complexity. We validate See4D on cross-view video generation and sparse reconstruction benchmarks. Across quantitative metrics and qualitative assessments, our method achieves superior generalization and improved performance relative to pose- or trajectory-conditioned baselines, advancing practical 4D world modeling from casual videos.
Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence
Oct 23, 2025Most video reasoning models only generate textual reasoning traces without indicating when and where key evidence appears. Recent models such as OpenAI-o3 have sparked wide interest in evidence-centered reasoning for images, yet extending this ability to videos is more challenging, as it requires joint temporal tracking and spatial localization across dynamic scenes. We introduce Open-o3 Video, a non-agent framework that integrates explicit spatio-temporal evidence into video reasoning, and carefully collect training data and design training strategies to address the aforementioned challenges. The model highlights key timestamps, objects, and bounding boxes alongside its answers, allowing reasoning to be grounded in concrete visual observations. To enable this functionality, we first curate and build two high-quality datasets, STGR-CoT-30k for SFT and STGR-RL-36k for RL, with carefully constructed temporal and spatial annotations, since most existing datasets offer either temporal spans for videos or spatial boxes on images, lacking unified spatio-temporal supervision and reasoning traces. Then, we adopt a cold-start reinforcement learning strategy with multiple specially designed rewards that jointly encourage answer accuracy, temporal alignment, and spatial precision. On V-STAR benchmark, Open-o3 Video achieves state-of-the-art performance, raising mAM by 14.4% and mLGM by 24.2% on the Qwen2.5-VL baseline. Consistent improvements are also observed on a broad range of video understanding benchmarks, including VideoMME, WorldSense, VideoMMMU, and TVGBench. Beyond accuracy, the reasoning traces produced by Open-o3 Video also provide valuable signals for test-time scaling, enabling confidence-aware verification and improving answer reliability.
VideoLucy: Deep Memory Backtracking for Long Video Understanding
Oct 14, 2025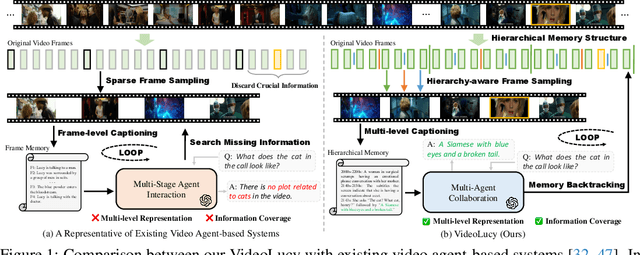
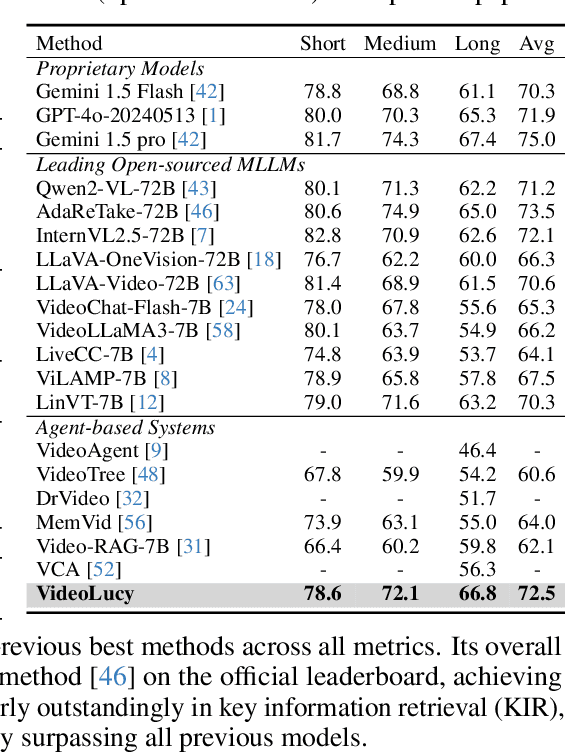
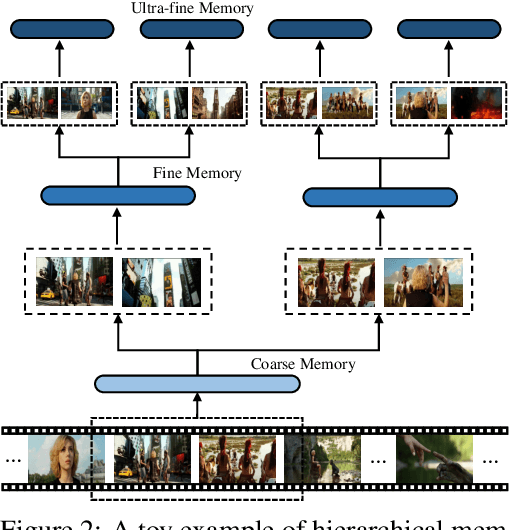

Recent studies have shown that agent-based systems leveraging large language models (LLMs) for key information retrieval and integration have emerged as a promising approach for long video understanding. However, these systems face two major challenges. First, they typically perform modeling and reasoning on individual frames, struggling to capture the temporal context of consecutive frames. Second, to reduce the cost of dense frame-level captioning, they adopt sparse frame sampling, which risks discarding crucial information. To overcome these limitations, we propose VideoLucy, a deep memory backtracking framework for long video understanding. Inspired by the human recollection process from coarse to fine, VideoLucy employs a hierarchical memory structure with progressive granularity. This structure explicitly defines the detail level and temporal scope of memory at different hierarchical depths. Through an agent-based iterative backtracking mechanism, VideoLucy systematically mines video-wide, question-relevant deep memories until sufficient information is gathered to provide a confident answer. This design enables effective temporal understanding of consecutive frames while preserving critical details. In addition, we introduce EgoMem, a new benchmark for long video understanding. EgoMem is designed to comprehensively evaluate a model's ability to understand complex events that unfold over time and capture fine-grained details in extremely long videos. Extensive experiments demonstrate the superiority of VideoLucy. Built on open-source models, VideoLucy significantly outperforms state-of-the-art methods on multiple long video understanding benchmarks, achieving performance even surpassing the latest proprietary models such as GPT-4o. Our code and dataset will be made publicly at https://videolucy.github.io
RewardMap: Tackling Sparse Rewards in Fine-grained Visual Reasoning via Multi-Stage Reinforcement Learning
Oct 02, 2025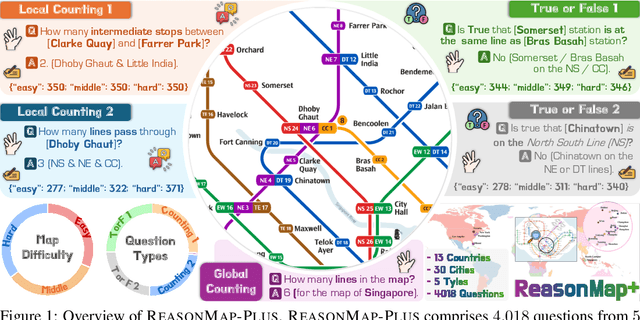
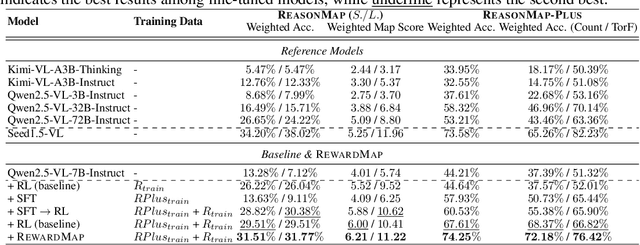
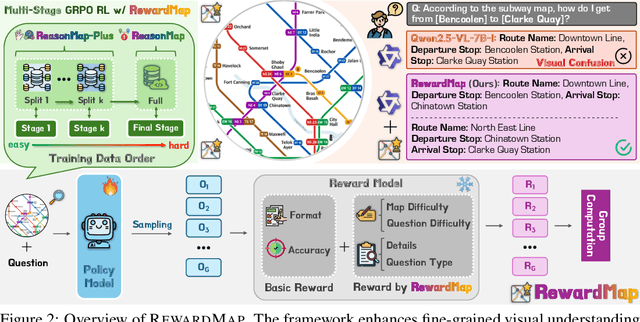
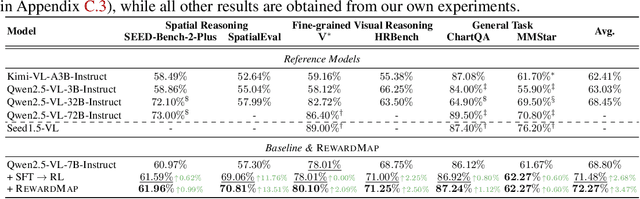
Fine-grained visual reasoning remains a core challenge for multimodal large language models (MLLMs). The recently introduced ReasonMap highlights this gap by showing that even advanced MLLMs struggle with spatial reasoning in structured and information-rich settings such as transit maps, a task of clear practical and scientific importance. However, standard reinforcement learning (RL) on such tasks is impeded by sparse rewards and unstable optimization. To address this, we first construct ReasonMap-Plus, an extended dataset that introduces dense reward signals through Visual Question Answering (VQA) tasks, enabling effective cold-start training of fine-grained visual understanding skills. Next, we propose RewardMap, a multi-stage RL framework designed to improve both visual understanding and reasoning capabilities of MLLMs. RewardMap incorporates two key designs. First, we introduce a difficulty-aware reward design that incorporates detail rewards, directly tackling the sparse rewards while providing richer supervision. Second, we propose a multi-stage RL scheme that bootstraps training from simple perception to complex reasoning tasks, offering a more effective cold-start strategy than conventional Supervised Fine-Tuning (SFT). Experiments on ReasonMap and ReasonMap-Plus demonstrate that each component of RewardMap contributes to consistent performance gains, while their combination yields the best results. Moreover, models trained with RewardMap achieve an average improvement of 3.47% across 6 benchmarks spanning spatial reasoning, fine-grained visual reasoning, and general tasks beyond transit maps, underscoring enhanced visual understanding and reasoning capabilities.