 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
Uni-Inter: Unifying 3D Human Motion Synthesis Across Diverse Interaction Contexts
Nov 17, 2025We present Uni-Inter, a unified framework for human motion generation that supports a wide range of interaction scenarios: including human-human, human-object, and human-scene-within a single, task-agnostic architecture. In contrast to existing methods that rely on task-specific designs and exhibit limited generalization, Uni-Inter introduces the Unified Interactive Volume (UIV), a volumetric representation that encodes heterogeneous interactive entities into a shared spatial field. This enables consistent relational reasoning and compound interaction modeling. Motion generation is formulated as joint-wise probabilistic prediction over the UIV, allowing the model to capture fine-grained spatial dependencies and produce coherent, context-aware behaviors. Experiments across three representative interaction tasks demonstrate that Uni-Inter achieves competitive performance and generalizes well to novel combinations of entities. These results suggest that unified modeling of compound interactions offers a promising direction for scalable motion synthesis in complex environments.
Towards a Generalizable Bimanual Foundation Policy via Flow-based Video Prediction
May 30, 2025Learning a generalizable bimanual manipulation policy is extremely challenging for embodied agents due to the large action space and the need for coordinated arm movements. Existing approaches rely on Vision-Language-Action (VLA) models to acquire bimanual policies. However, transferring knowledge from single-arm datasets or pre-trained VLA models often fails to generalize effectively, primarily due to the scarcity of bimanual data and the fundamental differences between single-arm and bimanual manipulation. In this paper, we propose a novel bimanual foundation policy by fine-tuning the leading text-to-video models to predict robot trajectories and training a lightweight diffusion policy for action generation. Given the lack of embodied knowledge in text-to-video models, we introduce a two-stage paradigm that fine-tunes independent text-to-flow and flow-to-video models derived from a pre-trained text-to-video model. Specifically, optical flow serves as an intermediate variable, providing a concise representation of subtle movements between images. The text-to-flow model predicts optical flow to concretize the intent of language instructions, and the flow-to-video model leverages this flow for fine-grained video prediction. Our method mitigates the ambiguity of language in single-stage text-to-video prediction and significantly reduces the robot-data requirement by avoiding direct use of low-level actions. In experiments, we collect high-quality manipulation data for real dual-arm robot, and the results of simulation and real-world experiments demonstrate the effectiveness of our method.
Metric-Solver: Sliding Anchored Metric Depth Estimation from a Single Image
Apr 16, 2025Accurate and generalizable metric depth estimation is crucial for various computer vision applications but remains challenging due to the diverse depth scales encountered in indoor and outdoor environments. In this paper, we introduce Metric-Solver, a novel sliding anchor-based metric depth estimation method that dynamically adapts to varying scene scales. Our approach leverages an anchor-based representation, where a reference depth serves as an anchor to separate and normalize the scene depth into two components: scaled near-field depth and tapered far-field depth. The anchor acts as a normalization factor, enabling the near-field depth to be normalized within a consistent range while mapping far-field depth smoothly toward zero. Through this approach, any depth from zero to infinity in the scene can be represented within a unified representation, effectively eliminating the need to manually account for scene scale variations. More importantly, for the same scene, the anchor can slide along the depth axis, dynamically adjusting to different depth scales. A smaller anchor provides higher resolution in the near-field, improving depth precision for closer objects while a larger anchor improves depth estimation in far regions. This adaptability enables the model to handle depth predictions at varying distances and ensure strong generalization across datasets. Our design enables a unified and adaptive depth representation across diverse environments. Extensive experiments demonstrate that Metric-Solver outperforms existing methods in both accuracy and cross-dataset generalization.
OmniVDiff: Omni Controllable Video Diffusion for Generation and Understanding
Apr 15, 2025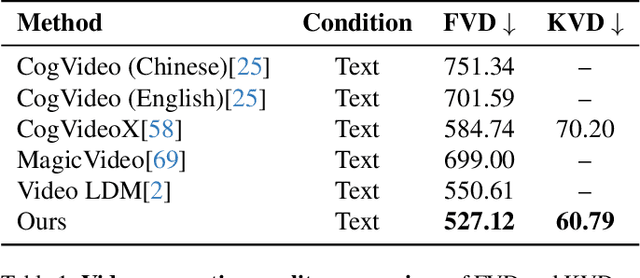
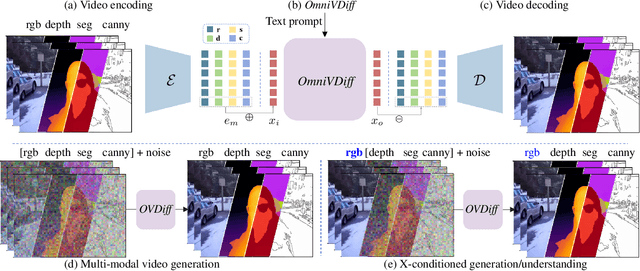
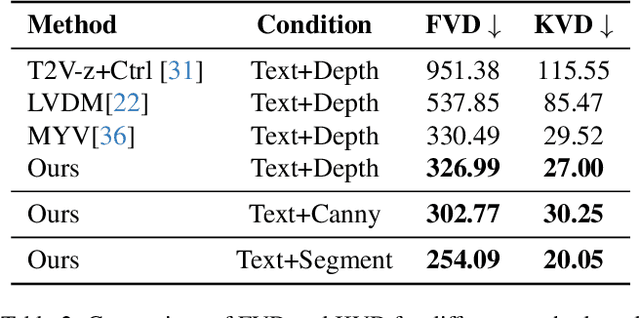

In this paper, we propose a novel framework for controllable video diffusion, OmniVDiff, aiming to synthesize and comprehend multiple video visual content in a single diffusion model. To achieve this, OmniVDiff treats all video visual modalities in the color space to learn a joint distribution, while employing an adaptive control strategy that dynamically adjusts the role of each visual modality during the diffusion process, either as a generation modality or a conditioning modality. This allows flexible manipulation of each modality's role, enabling support for a wide range of tasks. Consequently, our model supports three key functionalities: (1) Text-conditioned video generation: multi-modal visual video sequences (i.e., rgb, depth, canny, segmentaion) are generated based on the text conditions in one diffusion process; (2) Video understanding: OmniVDiff can estimate the depth, canny map, and semantic segmentation across the input rgb frames while ensuring coherence with the rgb input; and (3) X-conditioned video generation: OmniVDiff generates videos conditioned on fine-grained attributes (e.g., depth maps or segmentation maps). By integrating these diverse tasks into a unified video diffusion framework, OmniVDiff enhances the flexibility and scalability for controllable video diffusion, making it an effective tool for a variety of downstream applications, such as video-to-video translation. Extensive experiments demonstrate the effectiveness of our approach, highlighting its potential for various video-related applications.
MMGen: Unified Multi-modal Image Generation and Understanding in One Go
Mar 26, 2025A unified diffusion framework for multi-modal generation and understanding has the transformative potential to achieve seamless and controllable image diffusion and other cross-modal tasks. In this paper, we introduce MMGen, a unified framework that integrates multiple generative tasks into a single diffusion model. This includes: (1) multi-modal category-conditioned generation, where multi-modal outputs are generated simultaneously through a single inference process, given category information; (2) multi-modal visual understanding, which accurately predicts depth, surface normals, and segmentation maps from RGB images; and (3) multi-modal conditioned generation, which produces corresponding RGB images based on specific modality conditions and other aligned modalities. Our approach develops a novel diffusion transformer that flexibly supports multi-modal output, along with a simple modality-decoupling strategy to unify various tasks. Extensive experiments and applications demonstrate the effectiveness and superiority of MMGen across diverse tasks and conditions, highlighting its potential for applications that require simultaneous generation and understanding.
MVTokenFlow: High-quality 4D Content Generation using Multiview Token Flow
Feb 17, 2025In this paper, we present MVTokenFlow for high-quality 4D content creation from monocular videos. Recent advancements in generative models such as video diffusion models and multiview diffusion models enable us to create videos or 3D models. However, extending these generative models for dynamic 4D content creation is still a challenging task that requires the generated content to be consistent spatially and temporally. To address this challenge, MVTokenFlow utilizes the multiview diffusion model to generate multiview images on different timesteps, which attains spatial consistency across different viewpoints and allows us to reconstruct a reasonable coarse 4D field. Then, MVTokenFlow further regenerates all the multiview images using the rendered 2D flows as guidance. The 2D flows effectively associate pixels from different timesteps and improve the temporal consistency by reusing tokens in the regeneration process. Finally, the regenerated images are spatiotemporally consistent and utilized to refine the coarse 4D field to get a high-quality 4D field. Experiments demonstrate the effectiveness of our design and show significantly improved quality than baseline methods.
PanoSLAM: Panoptic 3D Scene Reconstruction via Gaussian SLAM
Dec 31, 2024



Understanding geometric, semantic, and instance information in 3D scenes from sequential video data is essential for applications in robotics and augmented reality. However, existing Simultaneous Localization and Mapping (SLAM) methods generally focus on either geometric or semantic reconstruction. In this paper, we introduce PanoSLAM, the first SLAM system to integrate geometric reconstruction, 3D semantic segmentation, and 3D instance segmentation within a unified framework. Our approach builds upon 3D Gaussian Splatting, modified with several critical components to enable efficient rendering of depth, color, semantic, and instance information from arbitrary viewpoints. To achieve panoptic 3D scene reconstruction from sequential RGB-D videos, we propose an online Spatial-Temporal Lifting (STL) module that transfers 2D panoptic predictions from vision models into 3D Gaussian representations. This STL module addresses the challenges of label noise and inconsistencies in 2D predictions by refining the pseudo labels across multi-view inputs, creating a coherent 3D representation that enhances segmentation accuracy. Our experiments show that PanoSLAM outperforms recent semantic SLAM methods in both mapping and tracking accuracy. For the first time, it achieves panoptic 3D reconstruction of open-world environments directly from the RGB-D video. (https://github.com/runnanchen/PanoSLAM)
OVGaussian: Generalizable 3D Gaussian Segmentation with Open Vocabularies
Dec 31, 2024Open-vocabulary scene understanding using 3D Gaussian (3DGS) representations has garnered considerable attention. However, existing methods mostly lift knowledge from large 2D vision models into 3DGS on a scene-by-scene basis, restricting the capabilities of open-vocabulary querying within their training scenes so that lacking the generalizability to novel scenes. In this work, we propose \textbf{OVGaussian}, a generalizable \textbf{O}pen-\textbf{V}ocabulary 3D semantic segmentation framework based on the 3D \textbf{Gaussian} representation. We first construct a large-scale 3D scene dataset based on 3DGS, dubbed \textbf{SegGaussian}, which provides detailed semantic and instance annotations for both Gaussian points and multi-view images. To promote semantic generalization across scenes, we introduce Generalizable Semantic Rasterization (GSR), which leverages a 3D neural network to learn and predict the semantic property for each 3D Gaussian point, where the semantic property can be rendered as multi-view consistent 2D semantic maps. In the next, we propose a Cross-modal Consistency Learning (CCL) framework that utilizes open-vocabulary annotations of 2D images and 3D Gaussians within SegGaussian to train the 3D neural network capable of open-vocabulary semantic segmentation across Gaussian-based 3D scenes. Experimental results demonstrate that OVGaussian significantly outperforms baseline methods, exhibiting robust cross-scene, cross-domain, and novel-view generalization capabilities. Code and the SegGaussian dataset will be released. (https://github.com/runnanchen/OVGaussian).
SolidGS: Consolidating Gaussian Surfel Splatting for Sparse-View Surface Reconstruction
Dec 19, 2024



Gaussian splatting has achieved impressive improvements for both novel-view synthesis and surface reconstruction from multi-view images. However, current methods still struggle to reconstruct high-quality surfaces from only sparse view input images using Gaussian splatting. In this paper, we propose a novel method called SolidGS to address this problem. We observed that the reconstructed geometry can be severely inconsistent across multi-views, due to the property of Gaussian function in geometry rendering. This motivates us to consolidate all Gaussians by adopting a more solid kernel function, which effectively improves the surface reconstruction quality. With the additional help of geometrical regularization and monocular normal estimation, our method achieves superior performance on the sparse view surface reconstruction than all the Gaussian splatting methods and neural field methods on the widely used DTU, Tanks-and-Temples, and LLFF datasets.