 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Flow Matching for Sparse-View CT Reconstruction
Feb 27, 2026Generative models, particularly Diffusion Models (DM), have shown strong potential for Computed Tomography (CT) reconstruction serving as expressive priors for solving ill-posed inverse problems. However, diffusion-based reconstruction relies on Stochastic Differential Equations (SDEs) for forward diffusion and reverse denoising, where such stochasticity can interfere with repeated data consistency corrections in CT reconstruction. Since CT reconstruction is often time-critical in clinical and interventional scenarios, improving reconstruction efficiency is essential. In contrast, Flow Matching (FM) models sampling as a deterministic Ordinary Differential Equation (ODE), yielding smooth trajectories without stochastic noise injection. This deterministic formulation is naturally compatible with repeated data consistency operations. Furthermore, we observe that FM-predicted velocity fields exhibit strong correlations across adjacent steps. Motivated by this, we propose an FM-based CT reconstruction framework (FMCT) and an efficient variant (EFMCT) that reuses previously predicted velocity fields over consecutive steps to substantially reduce the number of Neural network Function Evaluations (NFEs), thereby improving inference efficiency. We provide theoretical analysis showing that the error introduced by velocity reuse is bounded when combined with data consistency operations. Extensive experiments demonstrate that FMCT/EFMCT achieve competitive reconstruction quality while significantly improving computational efficiency compared with diffusion-based methods. The codebase is open-sourced at https://github.com/EFMCT/EFMCT.
Constructing Industrial-Scale Optimization Modeling Benchmark
Feb 11, 2026Optimization modeling underpins decision-making in logistics, manufacturing, energy, and finance, yet translating natural-language requirements into correct optimization formulations and solver-executable code remains labor-intensive. Although large language models (LLMs) have been explored for this task, evaluation is still dominated by toy-sized or synthetic benchmarks, masking the difficulty of industrial problems with $10^{3}$--$10^{6}$ (or more) variables and constraints. A key bottleneck is the lack of benchmarks that align natural-language specifications with reference formulations/solver code grounded in real optimization models. To fill in this gap, we introduce MIPLIB-NL, built via a structure-aware reverse construction methodology from real mixed-integer linear programs in MIPLIB~2017. Our pipeline (i) recovers compact, reusable model structure from flat solver formulations, (ii) reverse-generates natural-language specifications explicitly tied to this recovered structure under a unified model--data separation format, and (iii) performs iterative semantic validation through expert review and human--LLM interaction with independent reconstruction checks. This yields 223 one-to-one reconstructions that preserve the mathematical content of the original instances while enabling realistic natural-language-to-optimization evaluation. Experiments show substantial performance degradation on MIPLIB-NL for systems that perform strongly on existing benchmarks, exposing failure modes invisible at toy scale.
AscendCraft: Automatic Ascend NPU Kernel Generation via DSL-Guided Transcompilation
Jan 30, 2026The performance of deep learning models critically depends on efficient kernel implementations, yet developing high-performance kernels for specialized accelerators remains time-consuming and expertise-intensive. While recent work demonstrates that large language models (LLMs) can generate correct and performant GPU kernels, kernel generation for neural processing units (NPUs) remains largely underexplored due to domain-specific programming models, limited public examples, and sparse documentation. Consequently, directly generating AscendC kernels with LLMs yields extremely low correctness, highlighting a substantial gap between GPU and NPU kernel generation. We present AscendCraft, a DSL-guided approach for automatic AscendC kernel generation. AscendCraft introduces a lightweight DSL that abstracts non-essential complexity while explicitly modeling Ascend-specific execution semantics. Kernels are first generated in the DSL using category-specific expert examples and then transcompiled into AscendC through structured, constraint-driven LLM lowering passes. Evaluated on MultiKernelBench across seven operator categories, AscendCraft achieves 98.1% compilation success and 90.4% functional correctness. Moreover, 46.2% of generated kernels match or exceed PyTorch eager execution performance, demonstrating that DSL-guided transcompilation can enable LLMs to generate both correct and competitive NPU kernels. Beyond benchmarks, AscendCraft further demonstrates its generality by successfully generating two correct kernels for newly proposed mHC architecture, achieving performance that substantially surpasses PyTorch eager execution.
Bits for Privacy: Evaluating Post-Training Quantization via Membership Inference
Dec 17, 2025Deep neural networks are widely deployed with quantization techniques to reduce memory and computational costs by lowering the numerical precision of their parameters. While quantization alters model parameters and their outputs, existing privacy analyses primarily focus on full-precision models, leaving a gap in understanding how bit-width reduction can affect privacy leakage. We present the first systematic study of the privacy-utility relationship in post-training quantization (PTQ), a versatile family of methods that can be applied to pretrained models without further training. Using membership inference attacks as our evaluation framework, we analyze three popular PTQ algorithms-AdaRound, BRECQ, and OBC-across multiple precision levels (4-bit, 2-bit, and 1.58-bit) on CIFAR-10, CIFAR-100, and TinyImageNet datasets. Our findings consistently show that low-precision PTQs can reduce privacy leakage. In particular, lower-precision models demonstrate up to an order of magnitude reduction in membership inference vulnerability compared to their full-precision counterparts, albeit at the cost of decreased utility. Additional ablation studies on the 1.58-bit quantization level show that quantizing only the last layer at higher precision enables fine-grained control over the privacy-utility trade-off. These results offer actionable insights for practitioners to balance efficiency, utility, and privacy protection in real-world deployments.
DualMat: PBR Material Estimation via Coherent Dual-Path Diffusion
Aug 07, 2025We present DualMat, a novel dual-path diffusion framework for estimating Physically Based Rendering (PBR) materials from single images under complex lighting conditions. Our approach operates in two distinct latent spaces: an albedo-optimized path leveraging pretrained visual knowledge through RGB latent space, and a material-specialized path operating in a compact latent space designed for precise metallic and roughness estimation. To ensure coherent predictions between the albedo-optimized and material-specialized paths, we introduce feature distillation during training. We employ rectified flow to enhance efficiency by reducing inference steps while maintaining quality. Our framework extends to high-resolution and multi-view inputs through patch-based estimation and cross-view attention, enabling seamless integration into image-to-3D pipelines. DualMat achieves state-of-the-art performance on both Objaverse and real-world data, significantly outperforming existing methods with up to 28% improvement in albedo estimation and 39% reduction in metallic-roughness prediction errors.
Data Whisperer: Efficient Data Selection for Task-Specific LLM Fine-Tuning via Few-Shot In-Context Learning
May 18, 2025Fine-tuning large language models (LLMs) on task-specific data is essential for their effective deployment. As dataset sizes grow, efficiently selecting optimal subsets for training becomes crucial to balancing performance and computational costs. Traditional data selection methods often require fine-tuning a scoring model on the target dataset, which is time-consuming and resource-intensive, or rely on heuristics that fail to fully leverage the model's predictive capabilities. To address these challenges, we propose Data Whisperer, an efficient, training-free, attention-based method that leverages few-shot in-context learning with the model to be fine-tuned. Comprehensive evaluations were conducted on both raw and synthetic datasets across diverse tasks and models. Notably, Data Whisperer achieves superior performance compared to the full GSM8K dataset on the Llama-3-8B-Instruct model, using just 10% of the data, and outperforms existing methods with a 3.1-point improvement and a 7.4$\times$ speedup.
PanoDreamer: Consistent Text to 360-Degree Scene Generation
Apr 07, 2025



Automatically generating a complete 3D scene from a text description, a reference image, or both has significant applications in fields like virtual reality and gaming. However, current methods often generate low-quality textures and inconsistent 3D structures. This is especially true when extrapolating significantly beyond the field of view of the reference image. To address these challenges, we propose PanoDreamer, a novel framework for consistent, 3D scene generation with flexible text and image control. Our approach employs a large language model and a warp-refine pipeline, first generating an initial set of images and then compositing them into a 360-degree panorama. This panorama is then lifted into 3D to form an initial point cloud. We then use several approaches to generate additional images, from different viewpoints, that are consistent with the initial point cloud and expand/refine the initial point cloud. Given the resulting set of images, we utilize 3D Gaussian Splatting to create the final 3D scene, which can then be rendered from different viewpoints. Experiments demonstrate the effectiveness of PanoDreamer in generating high-quality, geometrically consistent 3D scenes.
Diffusion Models for Tabular Data: Challenges, Current Progress, and Future Directions
Feb 24, 2025In recent years, generative models have achieved remarkable performance across diverse applications, including image generation, text synthesis, audio creation, video generation, and data augmentation. Diffusion models have emerged as superior alternatives to Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) by addressing their limitations, such as training instability, mode collapse, and poor representation of multimodal distributions. This success has spurred widespread research interest. In the domain of tabular data, diffusion models have begun to showcase similar advantages over GANs and VAEs, achieving significant performance breakthroughs and demonstrating their potential for addressing unique challenges in tabular data modeling. However, while domains like images and time series have numerous surveys summarizing advancements in diffusion models, there remains a notable gap in the literature for tabular data. Despite the increasing interest in diffusion models for tabular data, there has been little effort to systematically review and summarize these developments. This lack of a dedicated survey limits a clear understanding of the challenges, progress, and future directions in this critical area. This survey addresses this gap by providing a comprehensive review of diffusion models for tabular data. Covering works from June 2015, when diffusion models emerged, to December 2024, we analyze nearly all relevant studies, with updates maintained in a \href{https://github.com/Diffusion-Model-Leiden/awesome-diffusion-models-for-tabular-data}{GitHub repository}. Assuming readers possess foundational knowledge of statistics and diffusion models, we employ mathematical formulations to deliver a rigorous and detailed review, aiming to promote developments in this emerging and exciting area.
Towards Automated Self-Supervised Learning for Truly Unsupervised Graph Anomaly Detection
Jan 24, 2025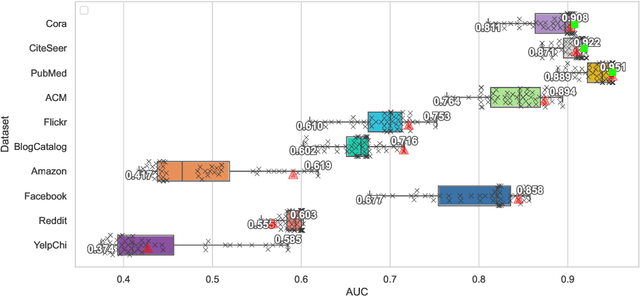
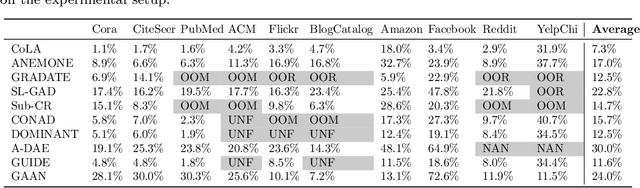
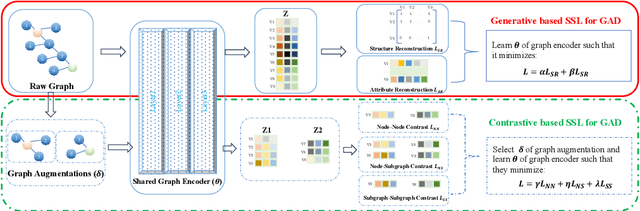
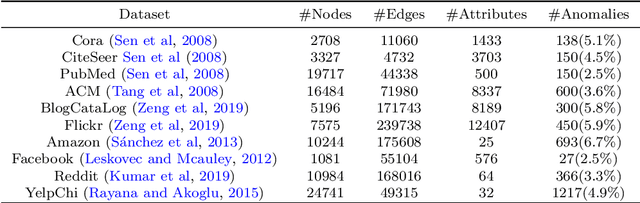
Self-supervised learning (SSL) is an emerging paradigm that exploits supervisory signals generated from the data itself, and many recent studies have leveraged SSL to conduct graph anomaly detection. However, we empirically found that three important factors can substantially impact detection performance across datasets: 1) the specific SSL strategy employed; 2) the tuning of the strategy's hyperparameters; and 3) the allocation of combination weights when using multiple strategies. Most SSL-based graph anomaly detection methods circumvent these issues by arbitrarily or selectively (i.e., guided by label information) choosing SSL strategies, hyperparameter settings, and combination weights. While an arbitrary choice may lead to subpar performance, using label information in an unsupervised setting is label information leakage and leads to severe overestimation of a method's performance. Leakage has been criticized as "one of the top ten data mining mistakes", yet many recent studies on SSL-based graph anomaly detection have been using label information to select hyperparameters. To mitigate this issue, we propose to use an internal evaluation strategy (with theoretical analysis) to select hyperparameters in SSL for unsupervised anomaly detection. We perform extensive experiments using 10 recent SSL-based graph anomaly detection algorithms on various benchmark datasets, demonstrating both the prior issues with hyperparameter selection and the effectiveness of our proposed strategy.
SolidGS: Consolidating Gaussian Surfel Splatting for Sparse-View Surface Reconstruction
Dec 19, 2024



Gaussian splatting has achieved impressive improvements for both novel-view synthesis and surface reconstruction from multi-view images. However, current methods still struggle to reconstruct high-quality surfaces from only sparse view input images using Gaussian splatting. In this paper, we propose a novel method called SolidGS to address this problem. We observed that the reconstructed geometry can be severely inconsistent across multi-views, due to the property of Gaussian function in geometry rendering. This motivates us to consolidate all Gaussians by adopting a more solid kernel function, which effectively improves the surface reconstruction quality. With the additional help of geometrical regularization and monocular normal estimation, our method achieves superior performance on the sparse view surface reconstruction than all the Gaussian splatting methods and neural field methods on the widely used DTU, Tanks-and-Temples, and LLFF datasets.