 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDrive-WM: Unified Understanding, Planning and Generation World Model For Autonomous Driving
Jan 07, 2026World models have become central to autonomous driving, where accurate scene understanding and future prediction are crucial for safe control. Recent work has explored using vision-language models (VLMs) for planning, yet existing approaches typically treat perception, prediction, and planning as separate modules. We propose UniDrive-WM, a unified VLM-based world model that jointly performs driving-scene understanding, trajectory planning, and trajectory-conditioned future image generation within a single architecture. UniDrive-WM's trajectory planner predicts a future trajectory, which conditions a VLM-based image generator to produce plausible future frames. These predictions provide additional supervisory signals that enhance scene understanding and iteratively refine trajectory generation. We further compare discrete and continuous output representations for future image prediction, analyzing their influence on downstream driving performance. Experiments on the challenging Bench2Drive benchmark show that UniDrive-WM produces high-fidelity future images and improves planning performance by 5.9% in L2 trajectory error and 9.2% in collision rate over the previous best method. These results demonstrate the advantages of tightly integrating VLM-driven reasoning, planning, and generative world modeling for autonomous driving. The project page is available at https://unidrive-wm.github.io/UniDrive-WM .
DeclutterNeRF: Generative-Free 3D Scene Recovery for Occlusion Removal
Apr 07, 2025Recent novel view synthesis (NVS) techniques, including Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have greatly advanced 3D scene reconstruction with high-quality rendering and realistic detail recovery. Effectively removing occlusions while preserving scene details can further enhance the robustness and applicability of these techniques. However, existing approaches for object and occlusion removal predominantly rely on generative priors, which, despite filling the resulting holes, introduce new artifacts and blurriness. Moreover, existing benchmark datasets for evaluating occlusion removal methods lack realistic complexity and viewpoint variations. To address these issues, we introduce DeclutterSet, a novel dataset featuring diverse scenes with pronounced occlusions distributed across foreground, midground, and background, exhibiting substantial relative motion across viewpoints. We further introduce DeclutterNeRF, an occlusion removal method free from generative priors. DeclutterNeRF introduces joint multi-view optimization of learnable camera parameters, occlusion annealing regularization, and employs an explainable stochastic structural similarity loss, ensuring high-quality, artifact-free reconstructions from incomplete images. Experiments demonstrate that DeclutterNeRF significantly outperforms state-of-the-art methods on our proposed DeclutterSet, establishing a strong baseline for future research.
PanoDreamer: Consistent Text to 360-Degree Scene Generation
Apr 07, 2025



Automatically generating a complete 3D scene from a text description, a reference image, or both has significant applications in fields like virtual reality and gaming. However, current methods often generate low-quality textures and inconsistent 3D structures. This is especially true when extrapolating significantly beyond the field of view of the reference image. To address these challenges, we propose PanoDreamer, a novel framework for consistent, 3D scene generation with flexible text and image control. Our approach employs a large language model and a warp-refine pipeline, first generating an initial set of images and then compositing them into a 360-degree panorama. This panorama is then lifted into 3D to form an initial point cloud. We then use several approaches to generate additional images, from different viewpoints, that are consistent with the initial point cloud and expand/refine the initial point cloud. Given the resulting set of images, we utilize 3D Gaussian Splatting to create the final 3D scene, which can then be rendered from different viewpoints. Experiments demonstrate the effectiveness of PanoDreamer in generating high-quality, geometrically consistent 3D scenes.
GenStereo: Towards Open-World Generation of Stereo Images and Unsupervised Matching
Mar 17, 2025Stereo images are fundamental to numerous applications, including extended reality (XR) devices, autonomous driving, and robotics. Unfortunately, acquiring high-quality stereo images remains challenging due to the precise calibration requirements of dual-camera setups and the complexity of obtaining accurate, dense disparity maps. Existing stereo image generation methods typically focus on either visual quality for viewing or geometric accuracy for matching, but not both. We introduce GenStereo, a diffusion-based approach, to bridge this gap. The method includes two primary innovations (1) conditioning the diffusion process on a disparity-aware coordinate embedding and a warped input image, allowing for more precise stereo alignment than previous methods, and (2) an adaptive fusion mechanism that intelligently combines the diffusion-generated image with a warped image, improving both realism and disparity consistency. Through extensive training on 11 diverse stereo datasets, GenStereo demonstrates strong generalization ability. GenStereo achieves state-of-the-art performance in both stereo image generation and unsupervised stereo matching tasks. Our framework eliminates the need for complex hardware setups while enabling high-quality stereo image generation, making it valuable for both real-world applications and unsupervised learning scenarios. Project page is available at https://qjizhi.github.io/genstereo
GroundingBooth: Grounding Text-to-Image Customization
Sep 13, 2024Recent studies in text-to-image customization show great success in generating personalized object variants given several images of a subject. While existing methods focus more on preserving the identity of the subject, they often fall short of controlling the spatial relationship between objects. In this work, we introduce GroundingBooth, a framework that achieves zero-shot instance-level spatial grounding on both foreground subjects and background objects in the text-to-image customization task. Our proposed text-image grounding module and masked cross-attention layer allow us to generate personalized images with both accurate layout alignment and identity preservation while maintaining text-image coherence. With such layout control, our model inherently enables the customization of multiple subjects at once. Our model is evaluated on both layout-guided image synthesis and reference-based customization tasks, showing strong results compared to existing methods. Our work is the first work to achieve a joint grounding of both subject-driven foreground generation and text-driven background generation.
PSM: Learning Probabilistic Embeddings for Multi-scale Zero-Shot Soundscape Mapping
Aug 13, 2024A soundscape is defined by the acoustic environment a person perceives at a location. In this work, we propose a framework for mapping soundscapes across the Earth. Since soundscapes involve sound distributions that span varying spatial scales, we represent locations with multi-scale satellite imagery and learn a joint representation among this imagery, audio, and text. To capture the inherent uncertainty in the soundscape of a location, we design the representation space to be probabilistic. We also fuse ubiquitous metadata (including geolocation, time, and data source) to enable learning of spatially and temporally dynamic representations of soundscapes. We demonstrate the utility of our framework by creating large-scale soundscape maps integrating both audio and text with temporal control. To facilitate future research on this task, we also introduce a large-scale dataset, GeoSound, containing over $300k$ geotagged audio samples paired with both low- and high-resolution satellite imagery. We demonstrate that our method outperforms the existing state-of-the-art on both GeoSound and the existing SoundingEarth dataset. Our dataset and code is available at https://github.com/mvrl/PSM.
MCPDepth: Omnidirectional Depth Estimation via Stereo Matching from Multi-Cylindrical Panoramas
Aug 03, 2024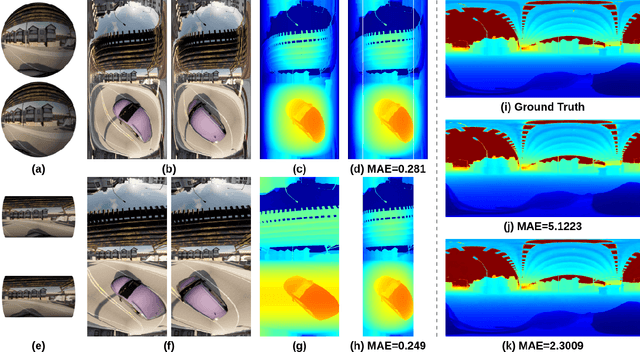
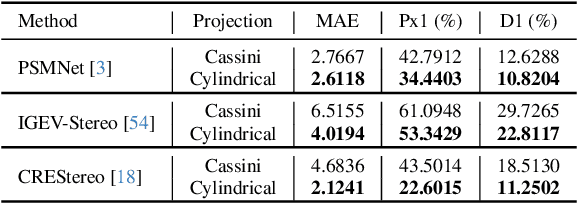
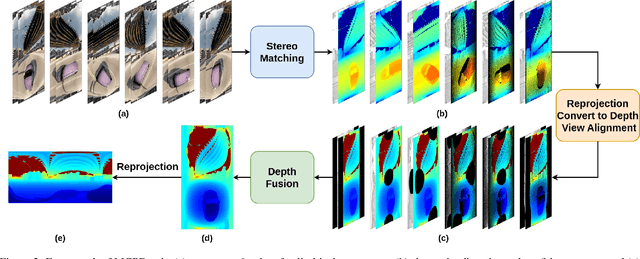
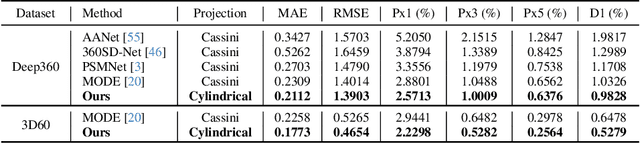
We introduce Multi-Cylindrical Panoramic Depth Estimation (MCPDepth), a two-stage framework for omnidirectional depth estimation via stereo matching between multiple cylindrical panoramas. MCPDepth uses cylindrical panoramas for initial stereo matching and then fuses the resulting depth maps across views. A circular attention module is employed to overcome the distortion along the vertical axis. MCPDepth exclusively utilizes standard network components, simplifying deployment to embedded devices and outperforming previous methods that require custom kernels. We theoretically and experimentally compare spherical and cylindrical projections for stereo matching, highlighting the advantages of the cylindrical projection. MCPDepth achieves state-of-the-art performance with an 18.8% reduction in mean absolute error (MAE) for depth on the outdoor synthetic dataset Deep360 and a 19.9% reduction on the indoor real-scene dataset 3D60.
Mixed-View Panorama Synthesis using Geospatially Guided Diffusion
Jul 12, 2024We introduce the task of mixed-view panorama synthesis, where the goal is to synthesize a novel panorama given a small set of input panoramas and a satellite image of the area. This contrasts with previous work which only uses input panoramas (same-view synthesis), or an input satellite image (cross-view synthesis). We argue that the mixed-view setting is the most natural to support panorama synthesis for arbitrary locations worldwide. A critical challenge is that the spatial coverage of panoramas is uneven, with few panoramas available in many regions of the world. We introduce an approach that utilizes diffusion-based modeling and an attention-based architecture for extracting information from all available input imagery. Experimental results demonstrate the effectiveness of our proposed method. In particular, our model can handle scenarios when the available panoramas are sparse or far from the location of the panorama we are attempting to synthesize.
Eroding Trust In Aerial Imagery: Comprehensive Analysis and Evaluation Of Adversarial Attacks In Geospatial Systems
Dec 12, 2023
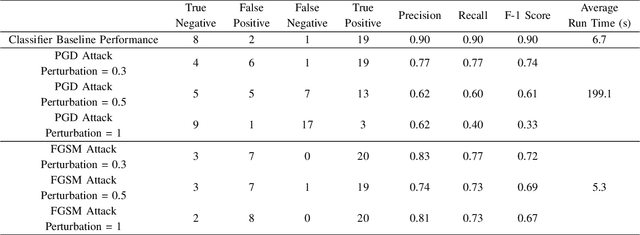
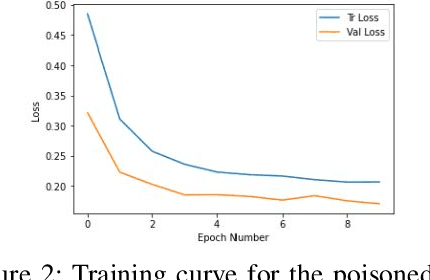
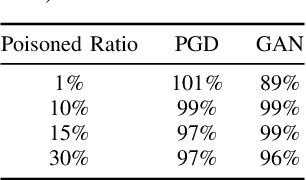
In critical operations where aerial imagery plays an essential role, the integrity and trustworthiness of data are paramount. The emergence of adversarial attacks, particularly those that exploit control over labels or employ physically feasible trojans, threatens to erode that trust, making the analysis and mitigation of these attacks a matter of urgency. We demonstrate how adversarial attacks can degrade confidence in geospatial systems, specifically focusing on scenarios where the attacker's control over labels is restricted and the use of realistic threat vectors. Proposing and evaluating several innovative attack methodologies, including those tailored to overhead images, we empirically show their threat to remote sensing systems using high-quality SpaceNet datasets. Our experimentation reflects the unique challenges posed by aerial imagery, and these preliminary results not only reveal the potential risks but also highlight the non-trivial nature of the problem compared to recent works.
Vision-Language Pseudo-Labels for Single-Positive Multi-Label Learning
Oct 24, 2023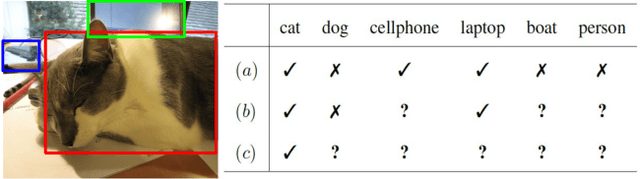
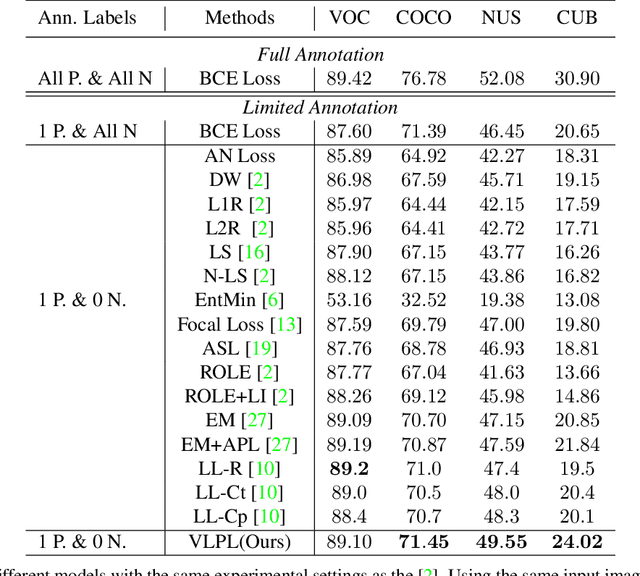
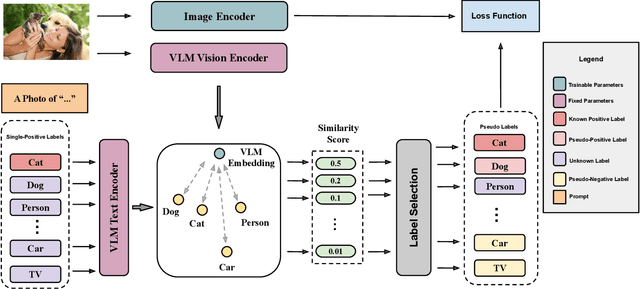
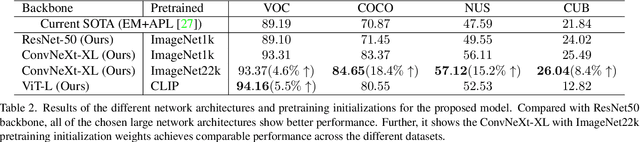
This paper presents a novel approach to Single-Positive Multi-label Learning. In general multi-label learning, a model learns to predict multiple labels or categories for a single input image. This is in contrast with standard multi-class image classification, where the task is predicting a single label from many possible labels for an image. Single-Positive Multi-label Learning (SPML) specifically considers learning to predict multiple labels when there is only a single annotation per image in the training data. Multi-label learning is in many ways a more realistic task than single-label learning as real-world data often involves instances belonging to multiple categories simultaneously; however, most common computer vision datasets predominantly contain single labels due to the inherent complexity and cost of collecting multiple high quality annotations for each instance. We propose a novel approach called Vision-Language Pseudo-Labeling (VLPL), which uses a vision-language model to suggest strong positive and negative pseudo-labels, and outperforms the current SOTA methods by 5.5% on Pascal VOC, 18.4% on MS-COCO, 15.2% on NUS-WIDE, and 8.4% on CUB-Birds. Our code and data are available at https://github.com/mvrl/VLPL.