 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-View Panorama Synthesis using Geospatially Guided Diffusion
Jul 12, 2024We introduce the task of mixed-view panorama synthesis, where the goal is to synthesize a novel panorama given a small set of input panoramas and a satellite image of the area. This contrasts with previous work which only uses input panoramas (same-view synthesis), or an input satellite image (cross-view synthesis). We argue that the mixed-view setting is the most natural to support panorama synthesis for arbitrary locations worldwide. A critical challenge is that the spatial coverage of panoramas is uneven, with few panoramas available in many regions of the world. We introduce an approach that utilizes diffusion-based modeling and an attention-based architecture for extracting information from all available input imagery. Experimental results demonstrate the effectiveness of our proposed method. In particular, our model can handle scenarios when the available panoramas are sparse or far from the location of the panorama we are attempting to synthesize.
LD-SDM: Language-Driven Hierarchical Species Distribution Modeling
Dec 13, 2023



We focus on the problem of species distribution modeling using global-scale presence-only data. Most previous studies have mapped the range of a given species using geographical and environmental features alone. To capture a stronger implicit relationship between species, we encode the taxonomic hierarchy of species using a large language model. This enables range mapping for any taxonomic rank and unseen species without additional supervision. Further, we propose a novel proximity-aware evaluation metric that enables evaluating species distribution models using any pixel-level representation of ground-truth species range map. The proposed metric penalizes the predictions of a model based on its proximity to the ground truth. We describe the effectiveness of our model by systematically evaluating on the task of species range prediction, zero-shot prediction and geo-feature regression against the state-of-the-art. Results show our model outperforms the strong baselines when trained with a variety of multi-label learning losses.
Vision-Language Pseudo-Labels for Single-Positive Multi-Label Learning
Oct 24, 2023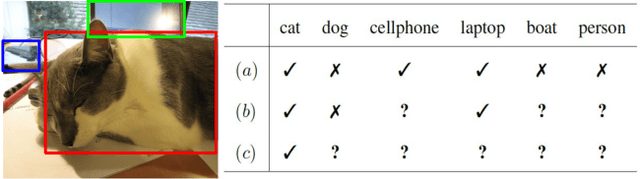
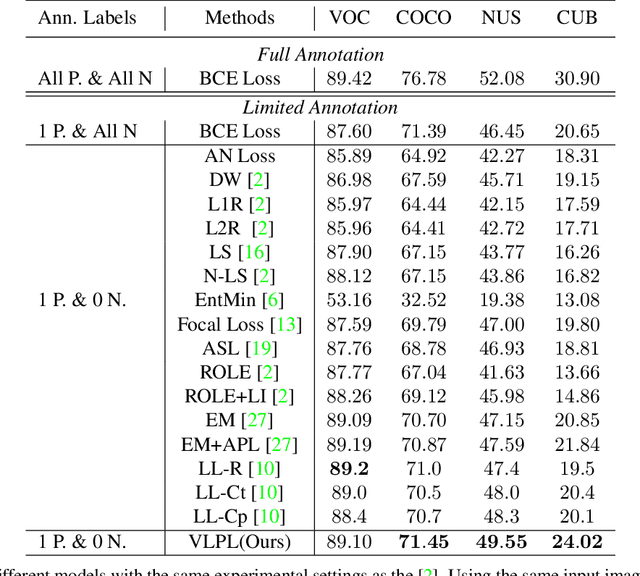
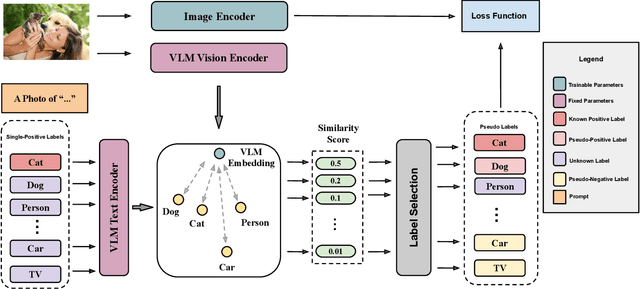
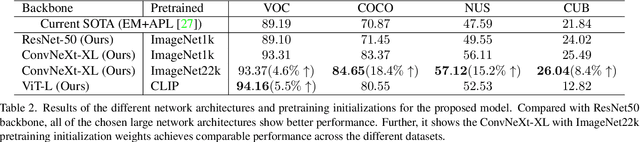
This paper presents a novel approach to Single-Positive Multi-label Learning. In general multi-label learning, a model learns to predict multiple labels or categories for a single input image. This is in contrast with standard multi-class image classification, where the task is predicting a single label from many possible labels for an image. Single-Positive Multi-label Learning (SPML) specifically considers learning to predict multiple labels when there is only a single annotation per image in the training data. Multi-label learning is in many ways a more realistic task than single-label learning as real-world data often involves instances belonging to multiple categories simultaneously; however, most common computer vision datasets predominantly contain single labels due to the inherent complexity and cost of collecting multiple high quality annotations for each instance. We propose a novel approach called Vision-Language Pseudo-Labeling (VLPL), which uses a vision-language model to suggest strong positive and negative pseudo-labels, and outperforms the current SOTA methods by 5.5% on Pascal VOC, 18.4% on MS-COCO, 15.2% on NUS-WIDE, and 8.4% on CUB-Birds. Our code and data are available at https://github.com/mvrl/VLPL.
Causality for Inherently Explainable Transformers: CAT-XPLAIN
Jun 29, 2022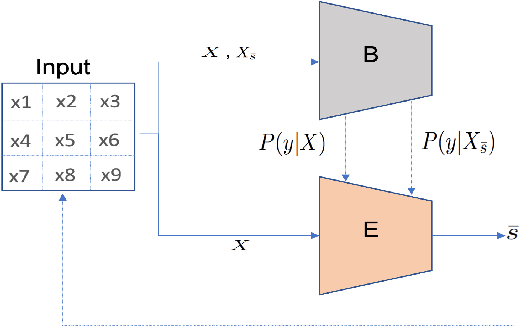
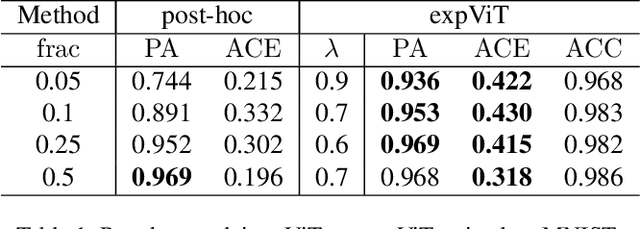
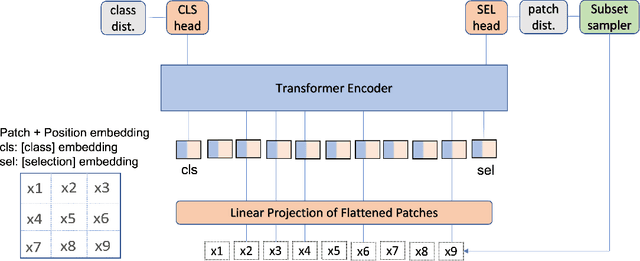
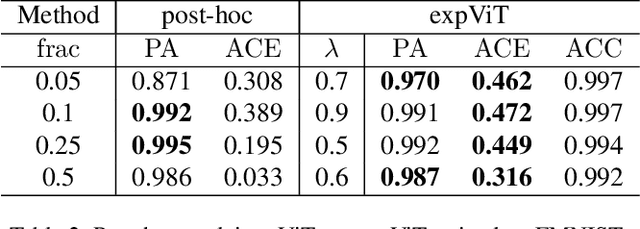
There have been several post-hoc explanation approaches developed to explain pre-trained black-box neural networks. However, there is still a gap in research efforts toward designing neural networks that are inherently explainable. In this paper, we utilize a recently proposed instance-wise post-hoc causal explanation method to make an existing transformer architecture inherently explainable. Once trained, our model provides an explanation in the form of top-$k$ regions in the input space of the given instance contributing to its decision. We evaluate our method on binary classification tasks using three image datasets: MNIST, FMNIST, and CIFAR. Our results demonstrate that compared to the causality-based post-hoc explainer model, our inherently explainable model achieves better explainability results while eliminating the need of training a separate explainer model. Our code is available at https://github.com/mvrl/CAT-XPLAIN.
Robust Flow-based Conformal Inference (FCI) with Statistical Guarantee
May 22, 2022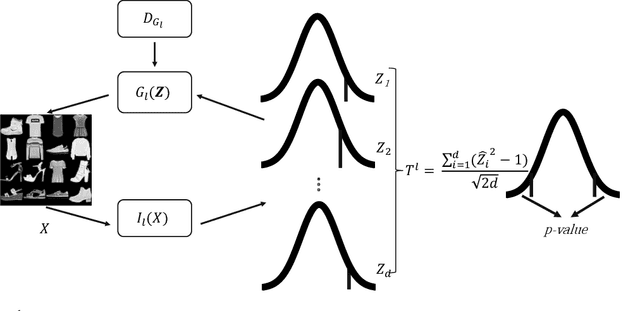
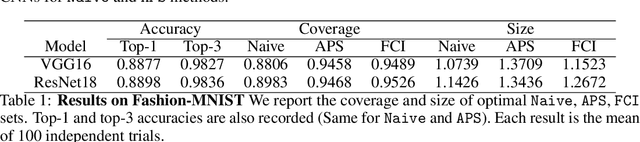
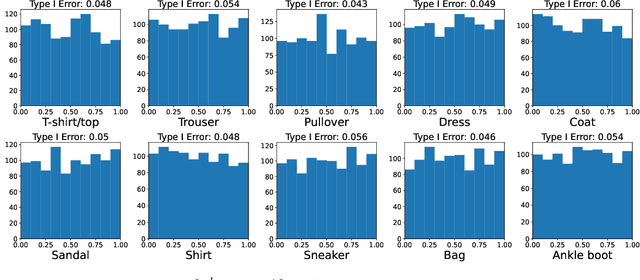

Conformal prediction aims to determine precise levels of confidence in predictions for new objects using past experience. However, the commonly used exchangeable assumptions between the training data and testing data limit its usage in dealing with contaminated testing sets. In this paper, we develop a series of conformal inference methods, including building predictive sets and inferring outliers for complex and high-dimensional data. We leverage ideas from adversarial flow to transfer the input data to a random vector with known distributions, which enable us to construct a non-conformity score for uncertainty quantification. We can further learn the distribution of input data in each class directly through the learned transformation. Therefore, our approach is applicable and more robust when the test data is contaminated. We evaluate our method, robust flow-based conformal inference, on benchmark datasets. We find that it produces effective prediction sets and accurate outlier detection and is more powerful relative to competing approaches.
Dynamic Image for 3D MRI Image Alzheimer's Disease Classification
Nov 30, 2020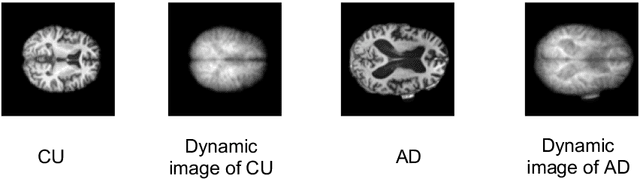
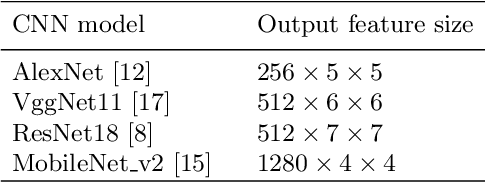
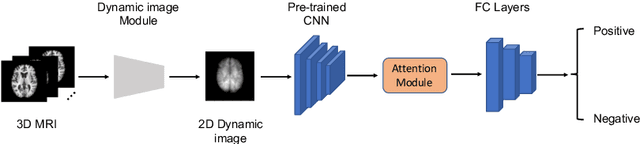
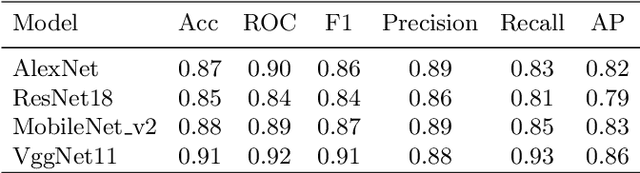
We propose to apply a 2D CNN architecture to 3D MRI image Alzheimer's disease classification. Training a 3D convolutional neural network (CNN) is time-consuming and computationally expensive. We make use of approximate rank pooling to transform the 3D MRI image volume into a 2D image to use as input to a 2D CNN. We show our proposed CNN model achieves $9.5\%$ better Alzheimer's disease classification accuracy than the baseline 3D models. We also show that our method allows for efficient training, requiring only 20% of the training time compared to 3D CNN models. The code is available online: https://github.com/UkyVision/alzheimer-project.
Neural Gaussian Mirror for Controlled Feature Selection in Neural Networks
Oct 13, 2020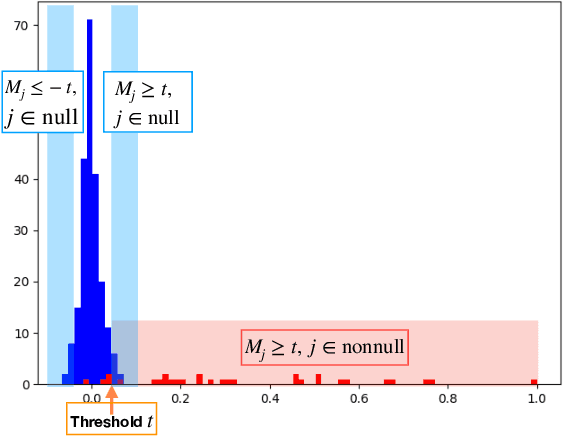
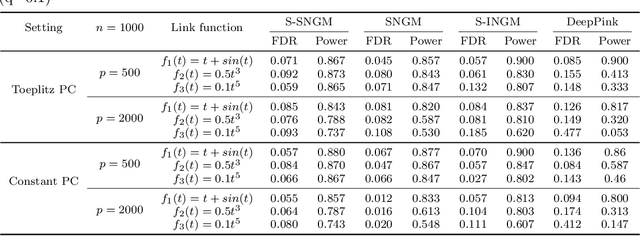
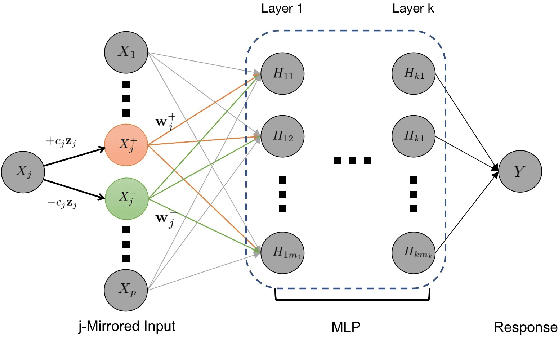
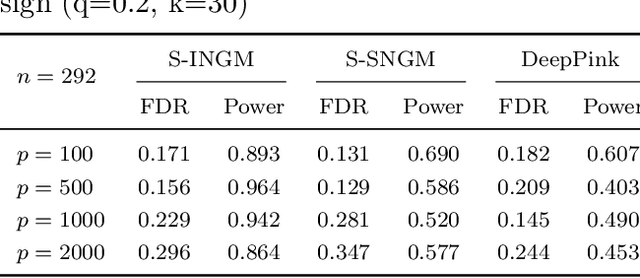
Deep neural networks (DNNs) have become increasingly popular and achieved outstanding performance in predictive tasks. However, the DNN framework itself cannot inform the user which features are more or less relevant for making the prediction, which limits its applicability in many scientific fields. We introduce neural Gaussian mirrors (NGMs), in which mirrored features are created, via a structured perturbation based on a kernel-based conditional dependence measure, to help evaluate feature importance. We design two modifications of the DNN architecture for incorporating mirrored features and providing mirror statistics to measure feature importance. As shown in simulated and real data examples, the proposed method controls the feature selection error rate at a predefined level and maintains a high selection power even with the presence of highly correlated features.
Joint 2D-3D Breast Cancer Classification
Feb 27, 2020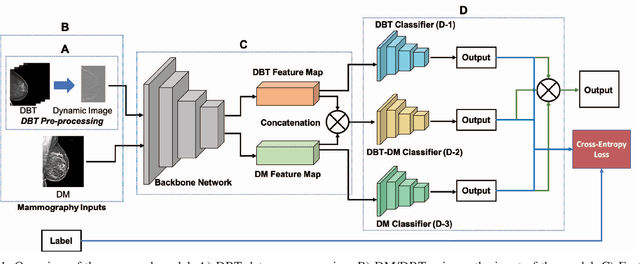
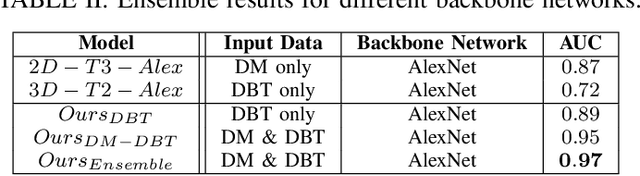

Breast cancer is the malignant tumor that causes the highest number of cancer deaths in females. Digital mammograms (DM or 2D mammogram) and digital breast tomosynthesis (DBT or 3D mammogram) are the two types of mammography imagery that are used in clinical practice for breast cancer detection and diagnosis. Radiologists usually read both imaging modalities in combination; however, existing computer-aided diagnosis tools are designed using only one imaging modality. Inspired by clinical practice, we propose an innovative convolutional neural network (CNN) architecture for breast cancer classification, which uses both 2D and 3D mammograms, simultaneously. Our experiment shows that the proposed method significantly improves the performance of breast cancer classification. By assembling three CNN classifiers, the proposed model achieves 0.97 AUC, which is 34.72% higher than the methods using only one imaging modality.
2D Convolutional Neural Networks for 3D Digital Breast Tomosynthesis Classification
Feb 27, 2020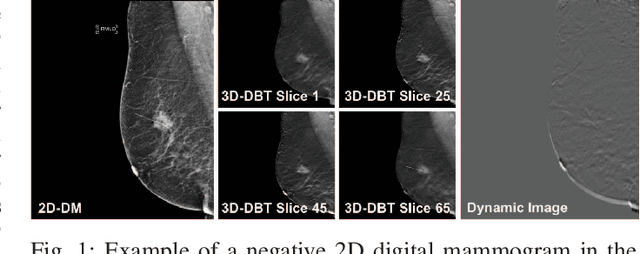
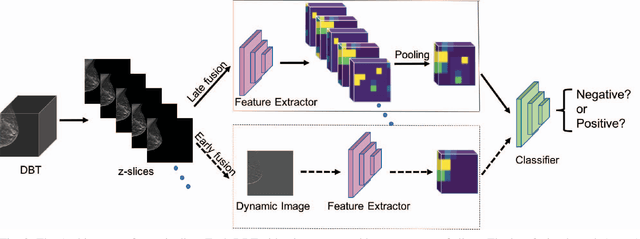
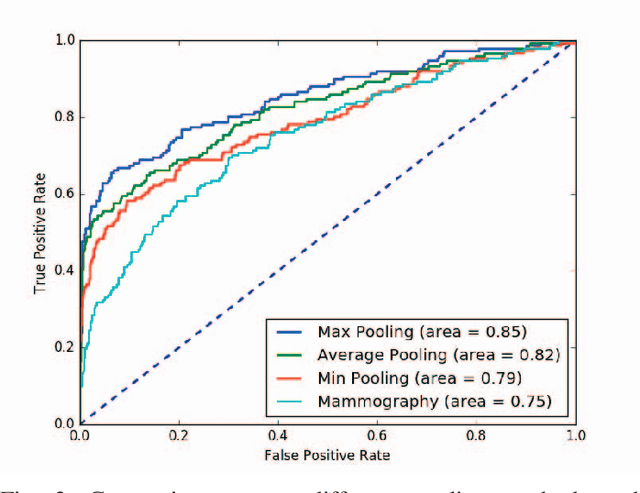
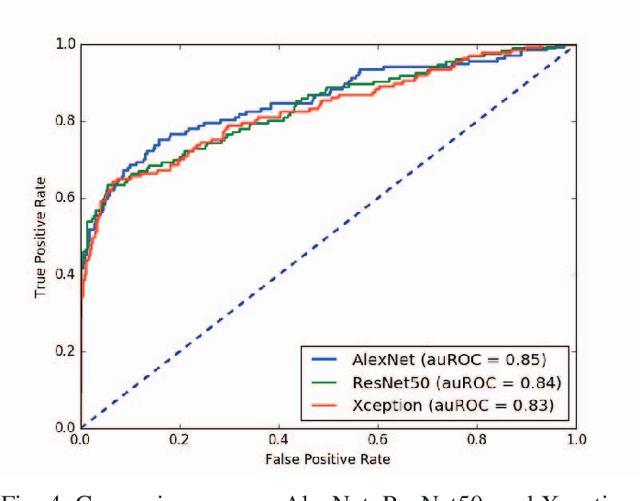
Automated methods for breast cancer detection have focused on 2D mammography and have largely ignored 3D digital breast tomosynthesis (DBT), which is frequently used in clinical practice. The two key challenges in developing automated methods for DBT classification are handling the variable number of slices and retaining slice-to-slice changes. We propose a novel deep 2D convolutional neural network (CNN) architecture for DBT classification that simultaneously overcomes both challenges. Our approach operates on the full volume, regardless of the number of slices, and allows the use of pre-trained 2D CNNs for feature extraction, which is important given the limited amount of annotated training data. In an extensive evaluation on a real-world clinical dataset, our approach achieves 0.854 auROC, which is 28.80% higher than approaches based on 3D CNNs. We also find that these improvements are stable across a range of model configurations.
Asymptotic Analysis of Sampling Estimators for Randomized Numerical Linear Algebra Algorithms
Feb 24, 2020
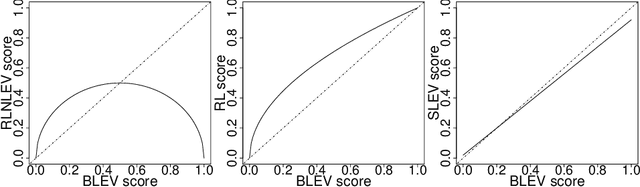
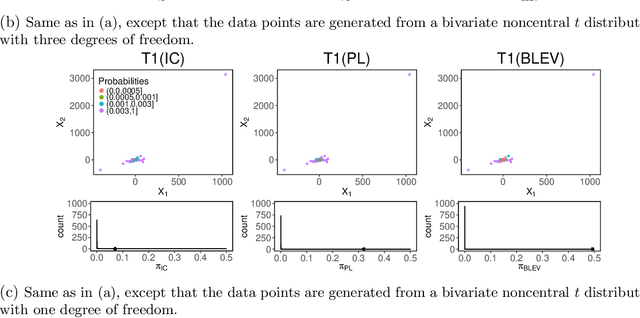
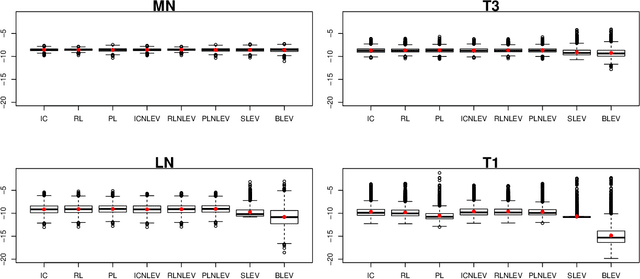
The statistical analysis of Randomized Numerical Linear Algebra (RandNLA) algorithms within the past few years has mostly focused on their performance as point estimators. However, this is insufficient for conducting statistical inference, e.g., constructing confidence intervals and hypothesis testing, since the distribution of the estimator is lacking. In this article, we develop an asymptotic analysis to derive the distribution of RandNLA sampling estimators for the least-squares problem. In particular, we derive the asymptotic distribution of a general sampling estimator with arbitrary sampling probabilities. The analysis is conducted in two complementary settings, i.e., when the objective of interest is to approximate the full sample estimator or is to infer the underlying ground truth model parameters. For each setting, we show that the sampling estimator is asymptotically normally distributed under mild regularity conditions. Moreover, the sampling estimator is asymptotically unbiased in both settings. Based on our asymptotic analysis, we use two criteria, the Asymptotic Mean Squared Error (AMSE) and the Expected Asymptotic Mean Squared Error (EAMSE), to identify optimal sampling probabilities. Several of these optimal sampling probability distributions are new to the literature, e.g., the root leverage sampling estimator and the predictor length sampling estimator. Our theoretical results clarify the role of leverage in the sampling process, and our empirical results demonstrate improvements over existing methods.