 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Statistical Understanding of Neural Networks: Beyond the Neural Tangent Kernel Theories
Dec 25, 2024A primary advantage of neural networks lies in their feature learning characteristics, which is challenging to theoretically analyze due to the complexity of their training dynamics. We propose a new paradigm for studying feature learning and the resulting benefits in generalizability. After reviewing the neural tangent kernel (NTK) theory and recent results in kernel regression, which address the generalization issue of sufficiently wide neural networks, we examine limitations and implications of the fixed kernel theory (as the NTK theory) and review recent theoretical advancements in feature learning. Moving beyond the fixed kernel/feature theory, we consider neural networks as adaptive feature models. Finally, we propose an over-parameterized Gaussian sequence model as a prototype model to study the feature learning characteristics of neural networks.
Multi-Response Heteroscedastic Gaussian Process Models and Their Inference
Aug 30, 2023Despite the widespread utilization of Gaussian process models for versatile nonparametric modeling, they exhibit limitations in effectively capturing abrupt changes in function smoothness and accommodating relationships with heteroscedastic errors. Addressing these shortcomings, the heteroscedastic Gaussian process (HeGP) regression seeks to introduce flexibility by acknowledging the variability of residual variances across covariates in the regression model. In this work, we extend the HeGP concept, expanding its scope beyond regression tasks to encompass classification and state-space models. To achieve this, we propose a novel framework where the Gaussian process is coupled with a covariate-induced precision matrix process, adopting a mixture formulation. This approach enables the modeling of heteroscedastic covariance functions across covariates. To mitigate the computational challenges posed by sampling, we employ variational inference to approximate the posterior and facilitate posterior predictive modeling. Additionally, our training process leverages an EM algorithm featuring closed-form M-step updates to efficiently evaluate the heteroscedastic covariance function. A notable feature of our model is its consistent performance on multivariate responses, accommodating various types (continuous or categorical) seamlessly. Through a combination of simulations and real-world applications in climatology, we illustrate the model's prowess and advantages. By overcoming the limitations of traditional Gaussian process models, our proposed framework offers a robust and versatile tool for a wide array of applications.
Neural Gaussian Mirror for Controlled Feature Selection in Neural Networks
Oct 13, 2020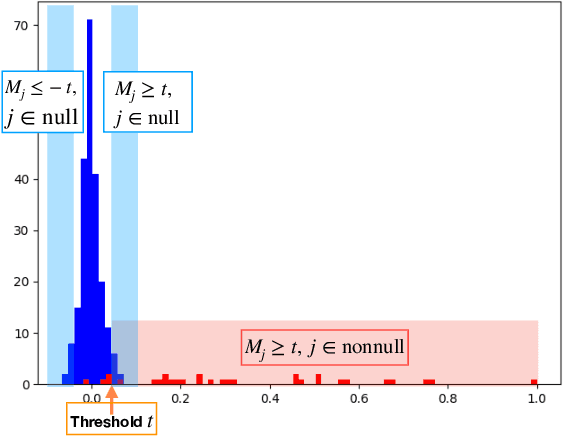
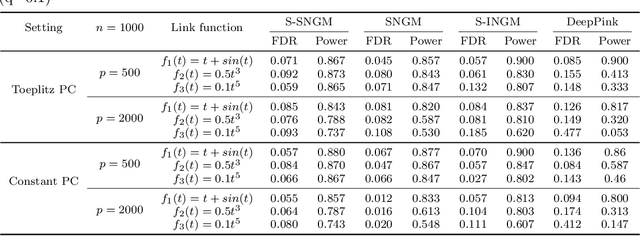
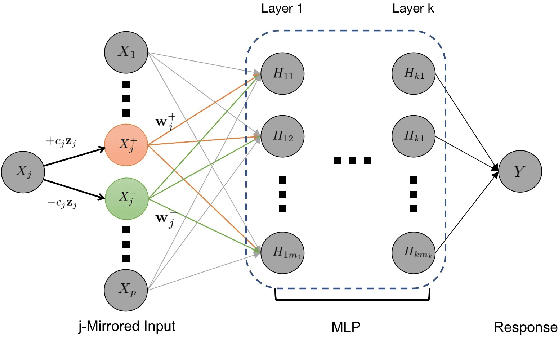
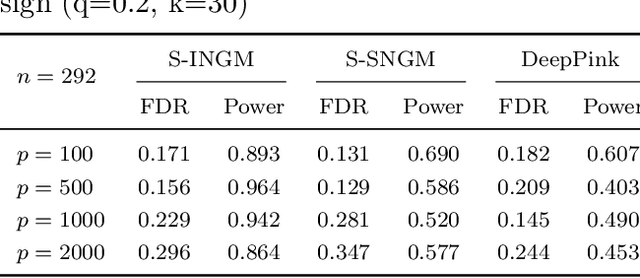
Deep neural networks (DNNs) have become increasingly popular and achieved outstanding performance in predictive tasks. However, the DNN framework itself cannot inform the user which features are more or less relevant for making the prediction, which limits its applicability in many scientific fields. We introduce neural Gaussian mirrors (NGMs), in which mirrored features are created, via a structured perturbation based on a kernel-based conditional dependence measure, to help evaluate feature importance. We design two modifications of the DNN architecture for incorporating mirrored features and providing mirror statistics to measure feature importance. As shown in simulated and real data examples, the proposed method controls the feature selection error rate at a predefined level and maintains a high selection power even with the presence of highly correlated features.
Minimax Nonparametric Two-sample Test
Nov 08, 2019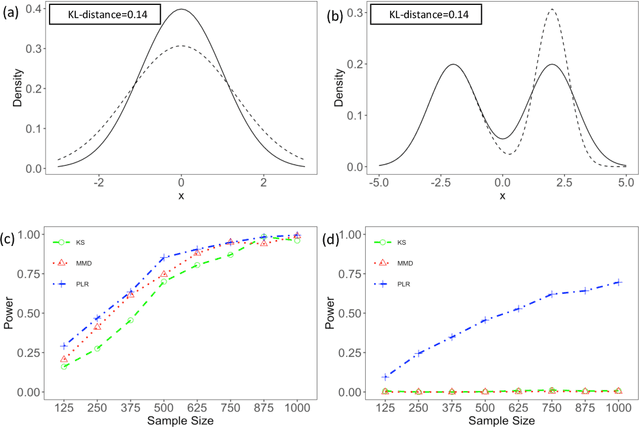
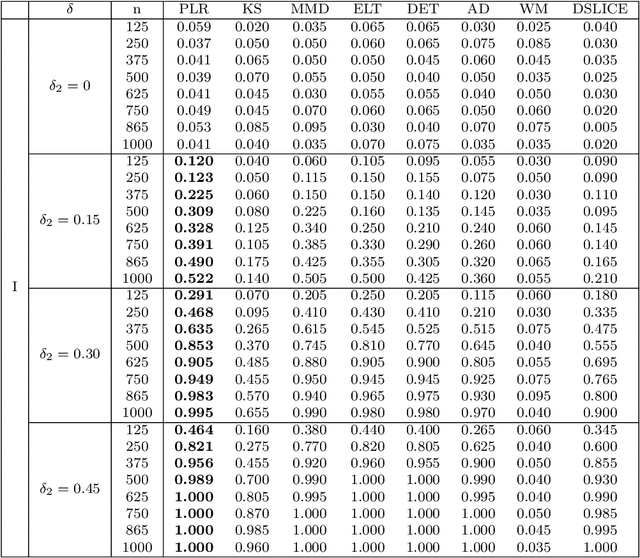
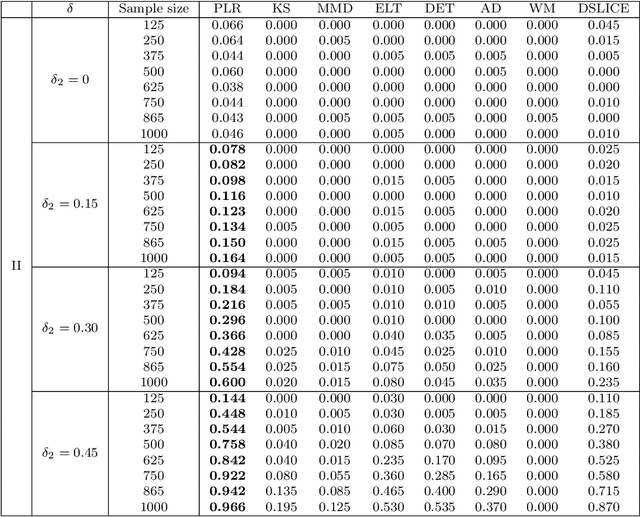
We consider the problem of comparing probability densities between two groups. To model the complex pattern of the underlying densities, we formulate the problem as a nonparametric density hypothesis testing problem. The major difficulty is that conventional tests may fail to distinguish the alternative from the null hypothesis under the controlled type I error. In this paper, we model log-transformed densities in a tensor product reproducing kernel Hilbert space (RKHS) and propose a probabilistic decomposition of this space. Under such a decomposition, we quantify the difference of the densities between two groups by the component norm in the probabilistic decomposition. Based on the Bernstein width, a sharp minimax lower bound of the distinguishable rate is established for the nonparametric two-sample test. We then propose a penalized likelihood ratio (PLR) test possessing the Wilks' phenomenon with an asymptotically Chi-square distributed test statistic and achieving the established minimax testing rate. Simulations and real applications demonstrate that the proposed test outperforms the conventional approaches under various scenarios.
The Wang-Landau Algorithm as Stochastic Optimization and its Acceleration
Jul 27, 2019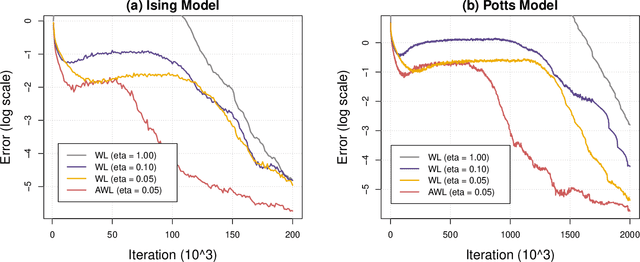
We show that the Wang-Landau algorithm can be formulated as a stochastic gradient descent algorithm minimizing a smooth and convex objective function, of which the gradient is estimated using Markov Chain Monte Carlo iterations. The optimization formulation provides a new perspective for improving the efficiency of the Wang-Landau algorithm using optimization tools. We propose one possible improvement, based on the momentum method and the adaptive learning rate idea, and demonstrate it on a two-dimensional Ising model and a two-dimensional ten-state Potts model.
Generative Parameter Sampler For Scalable Uncertainty Quantification
Jun 02, 2019
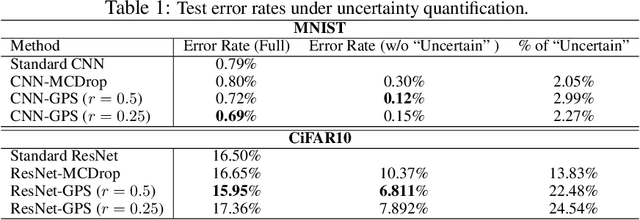
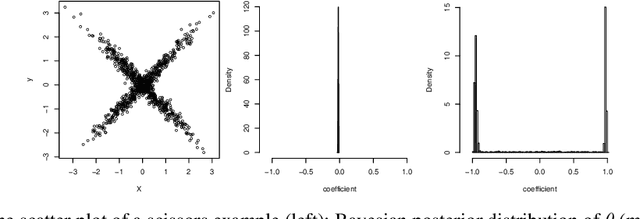
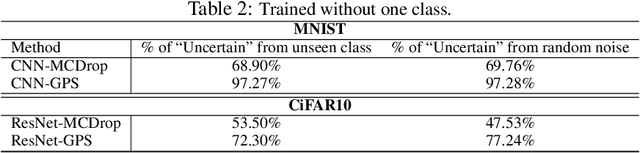
Uncertainty quantification has been a core of the statistical machine learning, but its computational bottleneck has been a serious challenge for both Bayesians and frequentists. We propose a model-based framework in quantifying uncertainty, called predictive-matching Generative Parameter Sampler (GPS). This procedure considers an Uncertainty Quantification (UQ) distribution on the targeted parameter, which matches the corresponding predictive distribution to the observed data. This framework adopts a hierarchical modeling perspective such that each observation is modeled by an individual parameter. This individual parameterization permits the resulting inference to be computationally scalable and robust to outliers. Our approach is illustrated for linear models, Poisson processes, and deep neural networks for classification. The results show that the GPS is successful in providing uncertainty quantification as well as additional flexibility beyond what is allowed by classical statistical procedures under the postulated statistical models.
Signed Support Recovery for Single Index Models in High-Dimensions
Jun 23, 2016

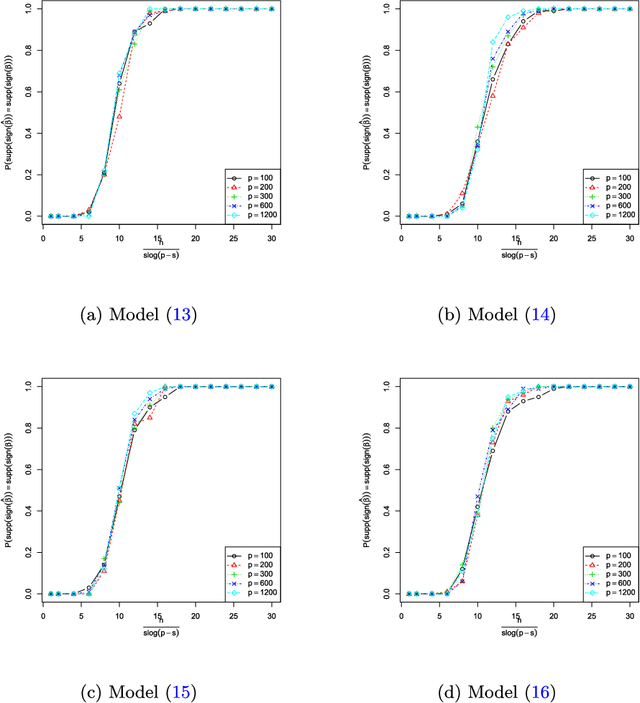

In this paper we study the support recovery problem for single index models $Y=f(\boldsymbol{X}^{\intercal} \boldsymbol{\beta},\varepsilon)$, where $f$ is an unknown link function, $\boldsymbol{X}\sim N_p(0,\mathbb{I}_{p})$ and $\boldsymbol{\beta}$ is an $s$-sparse unit vector such that $\boldsymbol{\beta}_{i}\in \{\pm\frac{1}{\sqrt{s}},0\}$. In particular, we look into the performance of two computationally inexpensive algorithms: (a) the diagonal thresholding sliced inverse regression (DT-SIR) introduced by Lin et al. (2015); and (b) a semi-definite programming (SDP) approach inspired by Amini & Wainwright (2008). When $s=O(p^{1-\delta})$ for some $\delta>0$, we demonstrate that both procedures can succeed in recovering the support of $\boldsymbol{\beta}$ as long as the rescaled sample size $\kappa=\frac{n}{s\log(p-s)}$ is larger than a certain critical threshold. On the other hand, when $\kappa$ is smaller than a critical value, any algorithm fails to recover the support with probability at least $\frac{1}{2}$ asymptotically. In other words, we demonstrate that both DT-SIR and the SDP approach are optimal (up to a scalar) for recovering the support of $\boldsymbol{\beta}$ in terms of sample size. We provide extensive simulations, as well as a real dataset application to help verify our theoretical observations.
L1-Regularized Least Squares for Support Recovery of High Dimensional Single Index Models with Gaussian Designs
Jun 23, 2016



It is known that for a certain class of single index models (SIMs) $Y = f(\boldsymbol{X}_{p \times 1}^\intercal\boldsymbol{\beta}_0, \varepsilon)$, support recovery is impossible when $\boldsymbol{X} \sim \mathcal{N}(0, \mathbb{I}_{p \times p})$ and a model complexity adjusted sample size is below a critical threshold. Recently, optimal algorithms based on Sliced Inverse Regression (SIR) were suggested. These algorithms work provably under the assumption that the design $\boldsymbol{X}$ comes from an i.i.d. Gaussian distribution. In the present paper we analyze algorithms based on covariance screening and least squares with $L_1$ penalization (i.e. LASSO) and demonstrate that they can also enjoy optimal (up to a scalar) rescaled sample size in terms of support recovery, albeit under slightly different assumptions on $f$ and $\varepsilon$ compared to the SIR based algorithms. Furthermore, we show more generally, that LASSO succeeds in recovering the signed support of $\boldsymbol{\beta}_0$ if $\boldsymbol{X} \sim \mathcal{N}(0, \boldsymbol{\Sigma})$, and the covariance $\boldsymbol{\Sigma}$ satisfies the irrepresentable condition. Our work extends existing results on the support recovery of LASSO for the linear model, to a more general class of SIMs.
A Unified Theory of Confidence Regions and Testing for High Dimensional Estimating Equations
Jun 23, 2016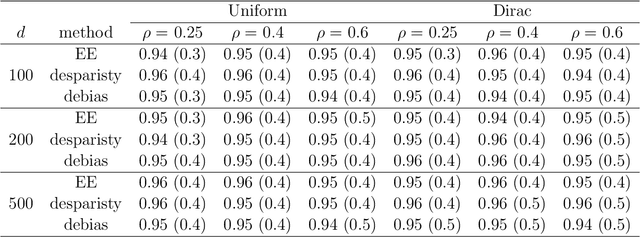
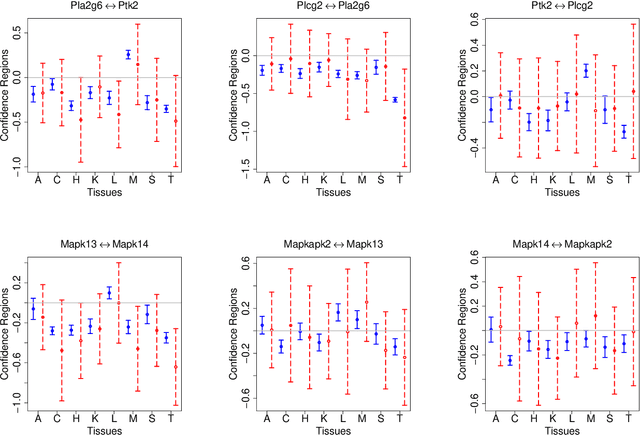
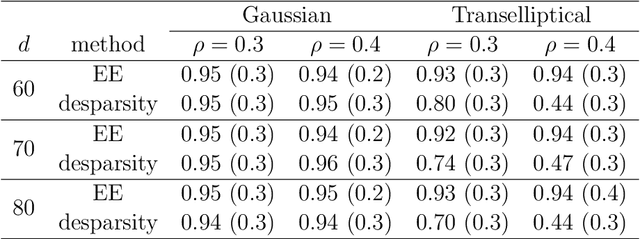
We propose a new inferential framework for constructing confidence regions and testing hypotheses in statistical models specified by a system of high dimensional estimating equations. We construct an influence function by projecting the fitted estimating equations to a sparse direction obtained by solving a large-scale linear program. Our main theoretical contribution is to establish a unified Z-estimation theory of confidence regions for high dimensional problems. Different from existing methods, all of which require the specification of the likelihood or pseudo-likelihood, our framework is likelihood-free. As a result, our approach provides valid inference for a broad class of high dimensional constrained estimating equation problems, which are not covered by existing methods. Such examples include, noisy compressed sensing, instrumental variable regression, undirected graphical models, discriminant analysis and vector autoregressive models. We present detailed theoretical results for all these examples. Finally, we conduct thorough numerical simulations, and a real dataset analysis to back up the developed theoretical results.
Interpretable Selection and Visualization of Features and Interactions Using Bayesian Forests
Feb 07, 2016



It is becoming increasingly important for machine learning methods to make predictions that are interpretable as well as accurate. In many practical applications, it is of interest which features and feature interactions are relevant to the prediction task. We present a novel method, Selective Bayesian Forest Classifier, that strikes a balance between predictive power and interpretability by simultaneously performing classification, feature selection, feature interaction detection and visualization. It builds parsimonious yet flexible models using tree-structured Bayesian networks, and samples an ensemble of such models using Markov chain Monte Carlo. We build in feature selection by dividing the trees into two groups according to their relevance to the outcome of interest. Our method performs competitively on classification and feature selection benchmarks in low and high dimensions, and includes a visualization tool that provides insight into relevant features and interactions.