 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust density estimation over star-shaped density classes
Jan 17, 2025We establish a novel criterion for comparing the performance of two densities, $g_1$ and $g_2$, within the context of corrupted data. Utilizing this criterion, we propose an algorithm to construct a density estimator within a star-shaped density class, $\mathcal{F}$, under conditions of data corruption. We proceed to derive the minimax upper and lower bounds for density estimation across this star-shaped density class, characterized by densities that are uniformly bounded above and below (in the sup norm), in the presence of adversarially corrupted data. Specifically, we assume that a fraction $\epsilon \leq \frac{1}{3}$ of the $N$ observations are arbitrarily corrupted. We obtain the minimax upper bound $\max\{ \tau_{\overline{J}}^2, \epsilon \} \wedge d^2$. Under certain conditions, we obtain the minimax risk, up to proportionality constants, under the squared $L_2$ loss as $$ \max\left\{ \tau^{*2} \wedge d^2, \epsilon \wedge d^2 \right\}, $$ where $\tau^* := \sup\left\{ \tau : N\tau^2 \leq \log \mathcal{M}_{\mathcal{F}}^{\text{loc}}(\tau, c) \right\}$ for a sufficiently large constant $c$. Here, $\mathcal{M}_{\mathcal{F}}^{\text{loc}}(\tau, c)$ denotes the local entropy of the set $\mathcal{F}$, and $d$ is the $L_2$ diameter of $\mathcal{F}$.
Semi-Supervised U-statistics
Mar 09, 2024Semi-supervised datasets are ubiquitous across diverse domains where obtaining fully labeled data is costly or time-consuming. The prevalence of such datasets has consistently driven the demand for new tools and methods that exploit the potential of unlabeled data. Responding to this demand, we introduce semi-supervised U-statistics enhanced by the abundance of unlabeled data, and investigate their statistical properties. We show that the proposed approach is asymptotically Normal and exhibits notable efficiency gains over classical U-statistics by effectively integrating various powerful prediction tools into the framework. To understand the fundamental difficulty of the problem, we derive minimax lower bounds in semi-supervised settings and showcase that our procedure is semi-parametrically efficient under regularity conditions. Moreover, tailored to bivariate kernels, we propose a refined approach that outperforms the classical U-statistic across all degeneracy regimes, and demonstrate its optimality properties. Simulation studies are conducted to corroborate our findings and to further demonstrate our framework.
Revisiting Le Cam's Equation: Exact Minimax Rates over Convex Density Classes
Oct 20, 2022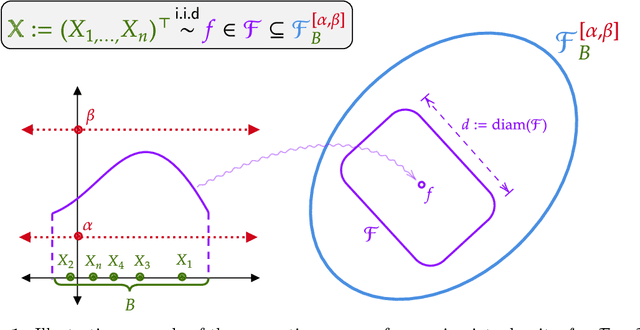
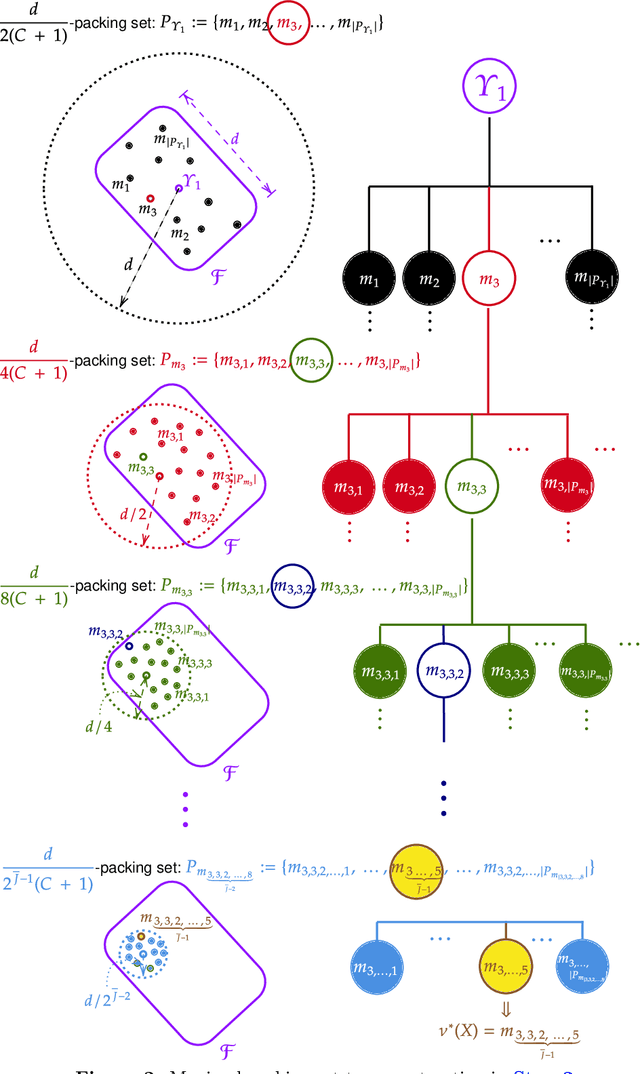
We study the classical problem of deriving minimax rates for density estimation over convex density classes. Building on the pioneering work of Le Cam (1973), Birge (1983, 1986), Wong and Shen (1995), Yang and Barron (1999), we determine the exact (up to constants) minimax rate over any convex density class. This work thus extends these known results by demonstrating that the local metric entropy of the density class always captures the minimax optimal rates under such settings. Our bounds provide a unifying perspective across both parametric and nonparametric convex density classes, under weaker assumptions on the richness of the density class than previously considered. Our proposed `multistage sieve' MLE applies to any such convex density class. We apply our risk bounds to rederive known minimax rates including bounded total variation, and Holder density classes. We further illustrate the utility of the result by deriving upper bounds for less studied classes, e.g., convex mixture of densities.
Adversarial Sign-Corrupted Isotonic Regression
Jul 14, 2022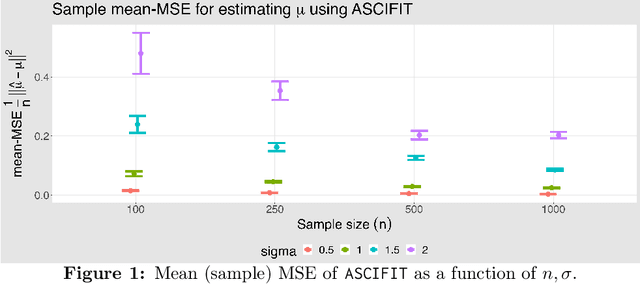
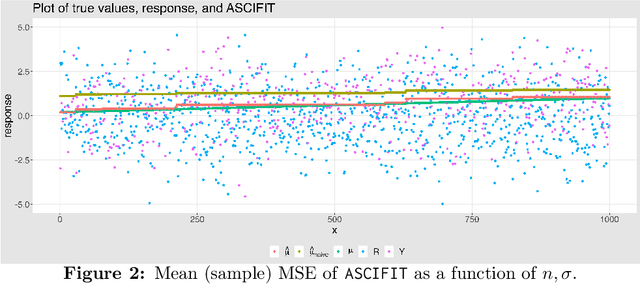
Classical univariate isotonic regression involves nonparametric estimation under a monotonicity constraint of the true signal. We consider a variation of this generating process, which we term adversarial sign-corrupted isotonic (\texttt{ASCI}) regression. Under this \texttt{ASCI} setting, the adversary has full access to the true isotonic responses, and is free to sign-corrupt them. Estimating the true monotonic signal given these sign-corrupted responses is a highly challenging task. Notably, the sign-corruptions are designed to violate monotonicity, and possibly induce heavy dependence between the corrupted response terms. In this sense, \texttt{ASCI} regression may be viewed as an adversarial stress test for isotonic regression. Our motivation is driven by understanding whether efficient robust estimation of the monotone signal is feasible under this adversarial setting. We develop \texttt{ASCIFIT}, a three-step estimation procedure under the \texttt{ASCI} setting. The \texttt{ASCIFIT} procedure is conceptually simple, easy to implement with existing software, and consists of applying the \texttt{PAVA} with crucial pre- and post-processing corrections. We formalize this procedure, and demonstrate its theoretical guarantees in the form of sharp high probability upper bounds and minimax lower bounds. We illustrate our findings with detailed simulations.
Non-Sparse PCA in High Dimensions via Cone Projected Power Iteration
May 15, 2020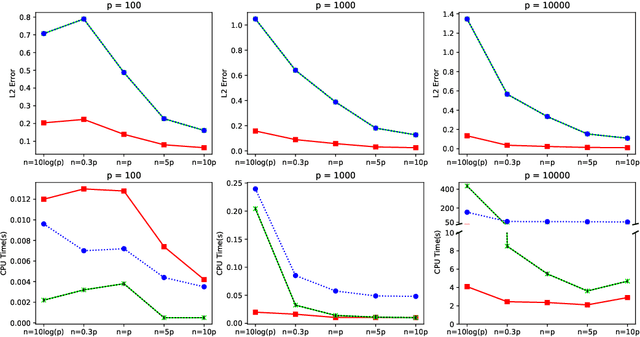

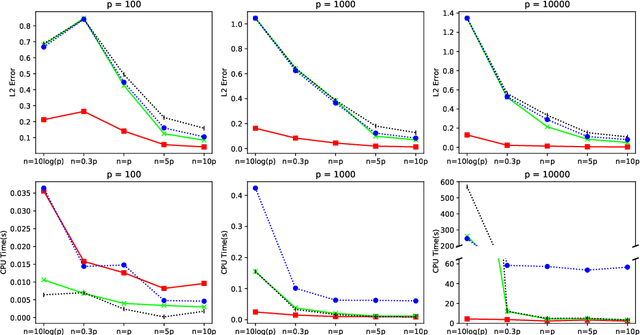
In this paper, we propose a cone projected power iteration algorithm to recover the principal eigenvector from a noisy positive semidefinite matrix. When the true principal eigenvector is assumed to belong to a convex cone, the proposed algorithm is fast and has a tractable error. Specifically, the method achieves polynomial time complexity for certain convex cones equipped with fast projection such as the monotone cone. It attains a small error when the noisy matrix has a small cone-restricted operator norm. We supplement the above results with a minimax lower bound of the error under the spiked covariance model. Our numerical experiments on simulated and real data, show that our method achieves shorter run time and smaller error in comparison to the ordinary power iteration and some sparse principal component analysis algorithms if the principal eigenvector is in a convex cone.
High Temperature Structure Detection in Ferromagnets
Sep 21, 2018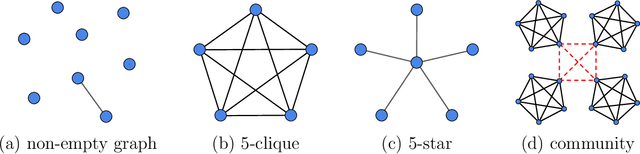
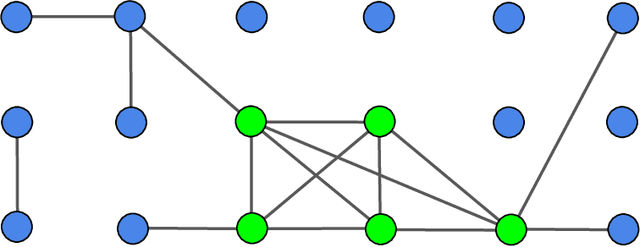
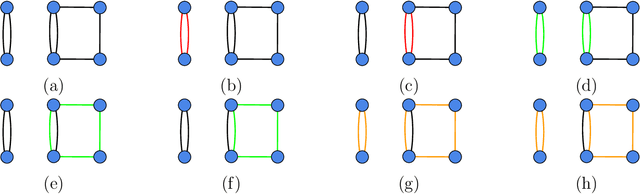

This paper studies structure detection problems in high temperature ferromagnetic (positive interaction only) Ising models. The goal is to distinguish whether the underlying graph is empty, i.e., the model consists of independent Rademacher variables, versus the alternative that the underlying graph contains a subgraph of a certain structure. We give matching upper and lower minimax bounds under which testing this problem is possible/impossible respectively. Our results reveal that a key quantity called graph arboricity drives the testability of the problem. On the computational front, under a conjecture of the computational hardness of sparse principal component analysis, we prove that, unless the signal is strong enough, there are no polynomial time linear tests on the sample covariance matrix which are capable of testing this problem.
Property Testing in High Dimensional Ising models
Jul 30, 2018

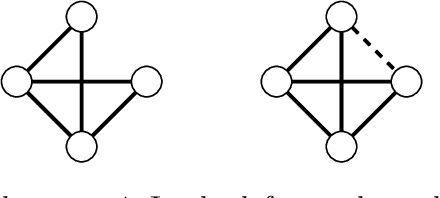

This paper explores the information-theoretic limitations of graph property testing in zero-field Ising models. Instead of learning the entire graph structure, sometimes testing a basic graph property such as connectivity, cycle presence or maximum clique size is a more relevant and attainable objective. Since property testing is more fundamental than graph recovery, any necessary conditions for property testing imply corresponding conditions for graph recovery, while custom property tests can be statistically and/or computationally more efficient than graph recovery based algorithms. Understanding the statistical complexity of property testing requires the distinction of ferromagnetic (i.e., positive interactions only) and general Ising models. Using combinatorial constructs such as graph packing and strong monotonicity, we characterize how target properties affect the corresponding minimax upper and lower bounds within the realm of ferromagnets. On the other hand, by studying the detection of an antiferromagnetic (i.e., negative interactions only) Curie-Weiss model buried in Rademacher noise, we show that property testing is strictly more challenging over general Ising models. In terms of methodological development, we propose two types of correlation based tests: computationally efficient screening for ferromagnets, and score type tests for general models, including a fast cycle presence test. Our correlation screening tests match the information-theoretic bounds for property testing in ferromagnets.
Surrogate Aided Unsupervised Recovery of Sparse Signals in Single Index Models for Binary Outcomes
Jul 01, 2018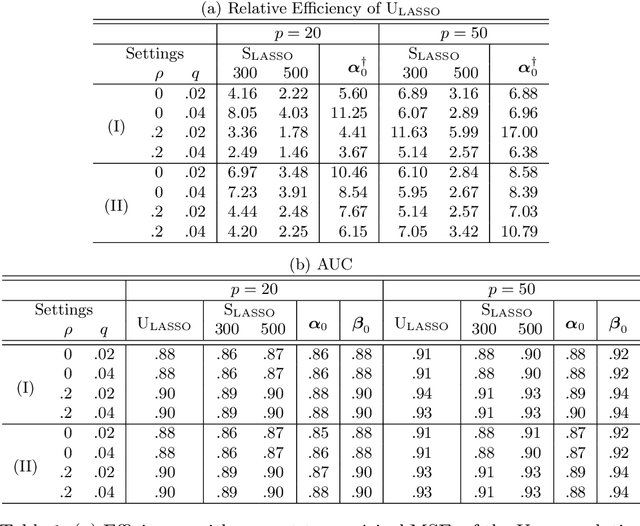
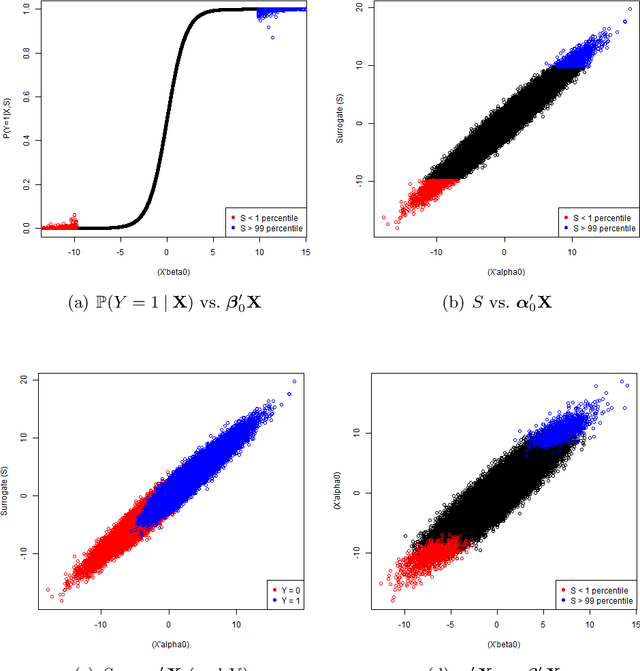
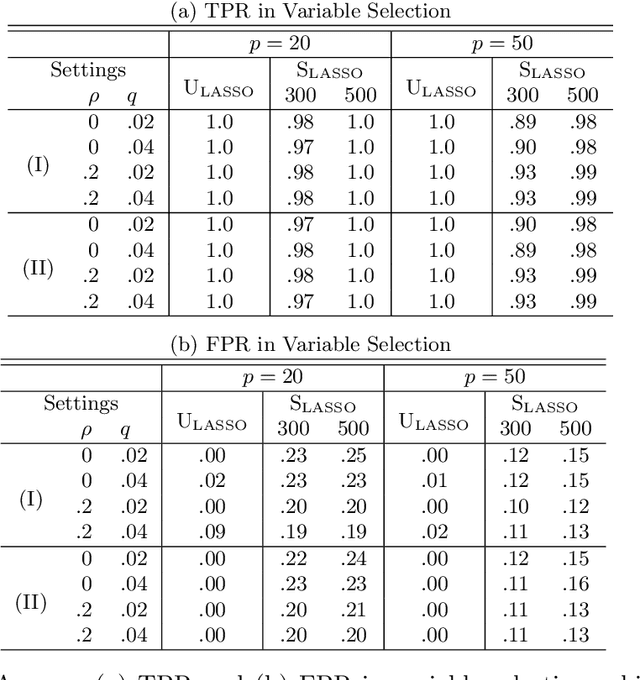

We consider the recovery of regression coefficients, denoted by $\boldsymbol{\beta}_0$, for a single index model (SIM) relating a binary outcome $Y$ to a set of possibly high dimensional covariates $\boldsymbol{X}$, based on a large but 'unlabeled' dataset $\mathcal{U}$, with $Y$ never observed. On $\mathcal{U}$, we fully observe $\boldsymbol{X}$ and additionally, a surrogate $S$ which, while not being strongly predictive of $Y$ throughout the entirety of its support, can forecast it with high accuracy when it assumes extreme values. Such datasets arise naturally in modern studies involving large databases such as electronic medical records (EMR) where $Y$, unlike $(\boldsymbol{X}, S)$, is difficult and/or expensive to obtain. In EMR studies, an example of $Y$ and $S$ would be the true disease phenotype and the count of the associated diagnostic codes respectively. Assuming another SIM for $S$ given $\boldsymbol{X}$, we show that under sparsity assumptions, we can recover $\boldsymbol{\beta}_0$ proportionally by simply fitting a least squares LASSO estimator to the subset of the observed data on $(\boldsymbol{X}, S)$ restricted to the extreme sets of $S$, with $Y$ imputed using the surrogacy of $S$. We obtain sharp finite sample performance bounds for our estimator, including deterministic deviation bounds and probabilistic guarantees. We demonstrate the effectiveness of our approach through multiple simulation studies, as well as by application to real data from an EMR study conducted at the Partners HealthCare Systems.
Combinatorial Inference for Graphical Models
Feb 13, 2018



We propose a new family of combinatorial inference problems for graphical models. Unlike classical statistical inference where the main interest is point estimation or parameter testing, combinatorial inference aims at testing the global structure of the underlying graph. Examples include testing the graph connectivity, the presence of a cycle of certain size, or the maximum degree of the graph. To begin with, we develop a unified theory for the fundamental limits of a large family of combinatorial inference problems. We propose new concepts including structural packing and buffer entropies to characterize how the complexity of combinatorial graph structures impacts the corresponding minimax lower bounds. On the other hand, we propose a family of novel and practical structural testing algorithms to match the lower bounds. We provide thorough numerical results on both synthetic graphical models and brain networks to illustrate the usefulness of these proposed methods.
Misspecified Nonconvex Statistical Optimization for Phase Retrieval
Dec 18, 2017


Existing nonconvex statistical optimization theory and methods crucially rely on the correct specification of the underlying "true" statistical models. To address this issue, we take a first step towards taming model misspecification by studying the high-dimensional sparse phase retrieval problem with misspecified link functions. In particular, we propose a simple variant of the thresholded Wirtinger flow algorithm that, given a proper initialization, linearly converges to an estimator with optimal statistical accuracy for a broad family of unknown link functions. We further provide extensive numerical experiments to support our theoretical findings.