 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-Oriented Design for EEG-to-Music Reconstruction
Jun 02, 2026Brain-computer interfaces aim to decode naturalistic stimuli from neural signals, yet most progress to date has focused on vision and language. In this article, we study a more challenging but far less explored setting, EEG-to-music reconstruction, where signals are weak, distributed, and highly susceptible to noise and channel variability. Our central finding is that early channel mixing destroys weak but discriminative EEG signals. To address this, we propose a channel-oriented design with three key components. Specifically, channel-wise tokenization treats each electrode as an explicit token to retain spatially localized neural evidence, channel-wise multi-view self-distillation enforces consistency across temporal crops and random channel subsets to learn robust and distributed representations, and channel-wise data augmentation introduces structured channel dropout to improve invariance to noise, artifacts, and missing electrodes. Together, these components preserve weak yet informative signals across channels and enable stable alignment to a semantic music representation space. We integrate this channel-oriented design within an encoding-alignment-decoding pipeline for EEG-to-music reconstruction. Theoretically, we characterize when preserving channel-level structure leads to improved alignment. Empirically, we compare with a range of state-of-the-art baselines and demonstrate consistent and significant performance gains.
Contextual Online Uncertainty-Aware Preference Learning for Human Feedback
Apr 29, 2025Reinforcement Learning from Human Feedback (RLHF) has become a pivotal paradigm in artificial intelligence to align large models with human preferences. In this paper, we propose a novel statistical framework to simultaneously conduct the online decision-making and statistical inference on the optimal model using human preference data based on dynamic contextual information. Our approach introduces an efficient decision strategy that achieves both the optimal regret bound and the asymptotic distribution of the estimators. A key challenge in RLHF is handling the dependent online human preference outcomes with dynamic contexts. To address this, in the methodological aspect, we propose a two-stage algorithm starting with $\epsilon$-greedy followed by exploitations; in the theoretical aspect, we tailor anti-concentration inequalities and matrix martingale concentration techniques to derive the uniform estimation rate and asymptotic normality of the estimators using dependent samples from both stages. Extensive simulation results demonstrate that our method outperforms state-of-the-art strategies. We apply the proposed framework to analyze the human preference data for ranking large language models on the Massive Multitask Language Understanding dataset, yielding insightful results on the performance of different large language models for medical anatomy knowledge.
Ranking of Large Language Model with Nonparametric Prompts
Dec 07, 2024
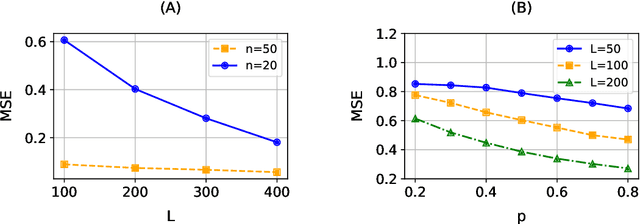
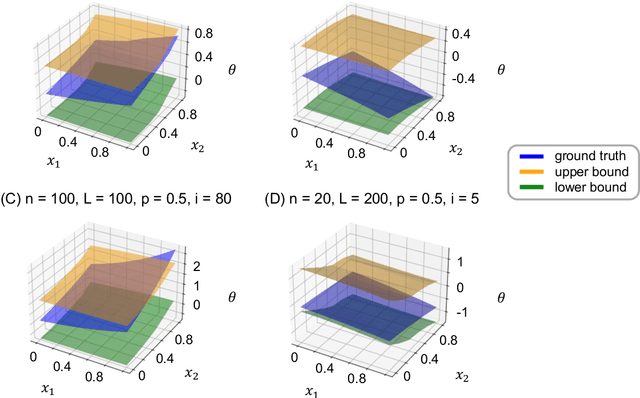
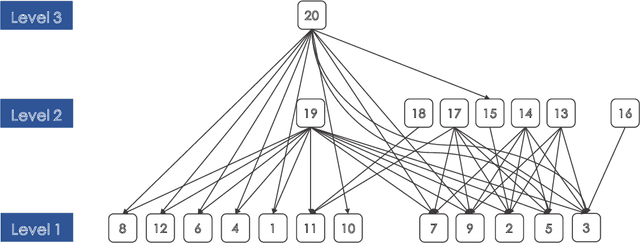
We consider the inference for the ranking of large language models (LLMs). Alignment arises as a big challenge to mitigate hallucinations in the use of LLMs. Ranking LLMs has been shown as a well-performing tool to improve alignment based on the best-of-$N$ policy. In this paper, we propose a new inferential framework for testing hypotheses and constructing confidence intervals of the ranking of language models. We consider the widely adopted Bradley-Terry-Luce (BTL) model, where each item is assigned a positive preference score that determines its pairwise comparisons' outcomes. We further extend it into the contextual setting, where the score of each model varies with the prompt. We show the convergence rate of our estimator. By extending the current Gaussian multiplier bootstrap theory to accommodate the supremum of not identically distributed empirical processes, we construct the confidence interval for ranking and propose a valid testing procedure. We also introduce the confidence diagram as a global ranking property. We conduct numerical experiments to assess the performance of our method.
Inference of Dependency Knowledge Graph for Electronic Health Records
Dec 25, 2023The effective analysis of high-dimensional Electronic Health Record (EHR) data, with substantial potential for healthcare research, presents notable methodological challenges. Employing predictive modeling guided by a knowledge graph (KG), which enables efficient feature selection, can enhance both statistical efficiency and interpretability. While various methods have emerged for constructing KGs, existing techniques often lack statistical certainty concerning the presence of links between entities, especially in scenarios where the utilization of patient-level EHR data is limited due to privacy concerns. In this paper, we propose the first inferential framework for deriving a sparse KG with statistical guarantee based on the dynamic log-linear topic model proposed by \cite{arora2016latent}. Within this model, the KG embeddings are estimated by performing singular value decomposition on the empirical pointwise mutual information matrix, offering a scalable solution. We then establish entrywise asymptotic normality for the KG low-rank estimator, enabling the recovery of sparse graph edges with controlled type I error. Our work uniquely addresses the under-explored domain of statistical inference about non-linear statistics under the low-rank temporal dependent models, a critical gap in existing research. We validate our approach through extensive simulation studies and then apply the method to real-world EHR data in constructing clinical KGs and generating clinical feature embeddings.
Nonparametric Additive Value Functions: Interpretable Reinforcement Learning with an Application to Surgical Recovery
Aug 25, 2023We propose a nonparametric additive model for estimating interpretable value functions in reinforcement learning. Learning effective adaptive clinical interventions that rely on digital phenotyping features is a major for concern medical practitioners. With respect to spine surgery, different post-operative recovery recommendations concerning patient mobilization can lead to significant variation in patient recovery. While reinforcement learning has achieved widespread success in domains such as games, recent methods heavily rely on black-box methods, such neural networks. Unfortunately, these methods hinder the ability of examining the contribution each feature makes in producing the final suggested decision. While such interpretations are easily provided in classical algorithms such as Least Squares Policy Iteration, basic linearity assumptions prevent learning higher-order flexible interactions between features. In this paper, we present a novel method that offers a flexible technique for estimating action-value functions without making explicit parametric assumptions regarding their additive functional form. This nonparametric estimation strategy relies on incorporating local kernel regression and basis expansion to obtain a sparse, additive representation of the action-value function. Under this approach, we are able to locally approximate the action-value function and retrieve the nonlinear, independent contribution of select features as well as joint feature pairs. We validate the proposed approach with a simulation study, and, in an application to spine disease, uncover recovery recommendations that are inline with related clinical knowledge.
Knowledge Graph Embedding with Electronic Health Records Data via Latent Graphical Block Model
May 31, 2023Due to the increasing adoption of electronic health records (EHR), large scale EHRs have become another rich data source for translational clinical research. Despite its potential, deriving generalizable knowledge from EHR data remains challenging. First, EHR data are generated as part of clinical care with data elements too detailed and fragmented for research. Despite recent progress in mapping EHR data to common ontology with hierarchical structures, much development is still needed to enable automatic grouping of local EHR codes to meaningful clinical concepts at a large scale. Second, the total number of unique EHR features is large, imposing methodological challenges to derive reproducible knowledge graph, especially when interest lies in conditional dependency structure. Third, the detailed EHR data on a very large patient cohort imposes additional computational challenge to deriving a knowledge network. To overcome these challenges, we propose to infer the conditional dependency structure among EHR features via a latent graphical block model (LGBM). The LGBM has a two layer structure with the first providing semantic embedding vector (SEV) representation for the EHR features and the second overlaying a graphical block model on the latent SEVs. The block structures on the graphical model also allows us to cluster synonymous features in EHR. We propose to learn the LGBM efficiently, in both statistical and computational sense, based on the empirical point mutual information matrix. We establish the statistical rates of the proposed estimators and show the perfect recovery of the block structure. Numerical results from simulation studies and real EHR data analyses suggest that the proposed LGBM estimator performs well in finite sample.
LATTE: Label-efficient Incident Phenotyping from Longitudinal Electronic Health Records
May 19, 2023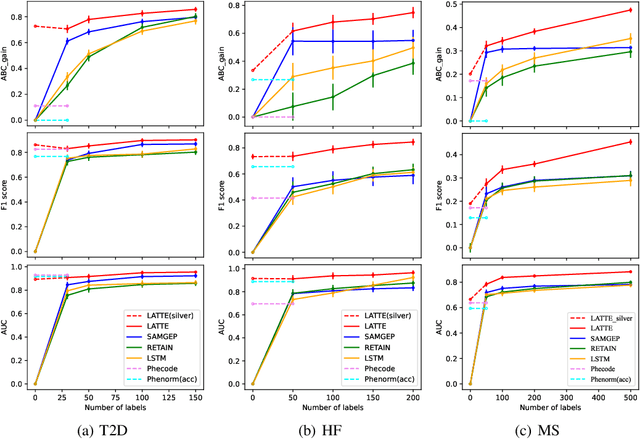
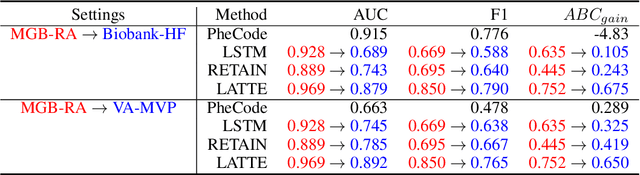
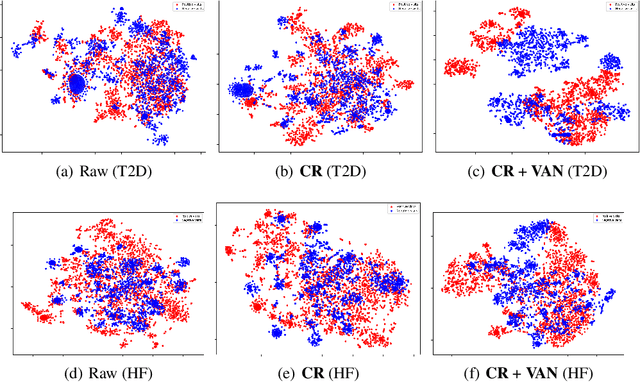

Electronic health record (EHR) data are increasingly used to support real-world evidence (RWE) studies. Yet its ability to generate reliable RWE is limited by the lack of readily available precise information on the timing of clinical events such as the onset time of heart failure. We propose a LAbel-efficienT incidenT phEnotyping (LATTE) algorithm to accurately annotate the timing of clinical events from longitudinal EHR data. By leveraging the pre-trained semantic embedding vectors from large-scale EHR data as prior knowledge, LATTE selects predictive EHR features in a concept re-weighting module by mining their relationship to the target event and compresses their information into longitudinal visit embeddings through a visit attention learning network. LATTE employs a recurrent neural network to capture the sequential dependency between the target event and visit embeddings before/after it. To improve label efficiency, LATTE constructs highly informative longitudinal silver-standard labels from large-scale unlabeled patients to perform unsupervised pre-training and semi-supervised joint training. Finally, LATTE enhances cross-site portability via contrastive representation learning. LATTE is evaluated on three analyses: the onset of type-2 diabetes, heart failure, and the onset and relapses of multiple sclerosis. We use various evaluation metrics present in the literature including the $ABC_{gain}$, the proportion of reduction in the area between the observed event indicator and the predicted cumulative incidences in reference to the prediction per incident prevalence. LATTE consistently achieves substantial improvement over benchmark methods such as SAMGEP and RETAIN in all settings.
Combinatorial Inference on the Optimal Assortment in Multinomial Logit Models
Feb 02, 2023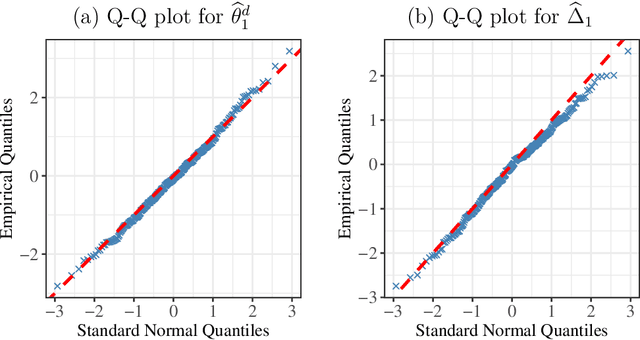
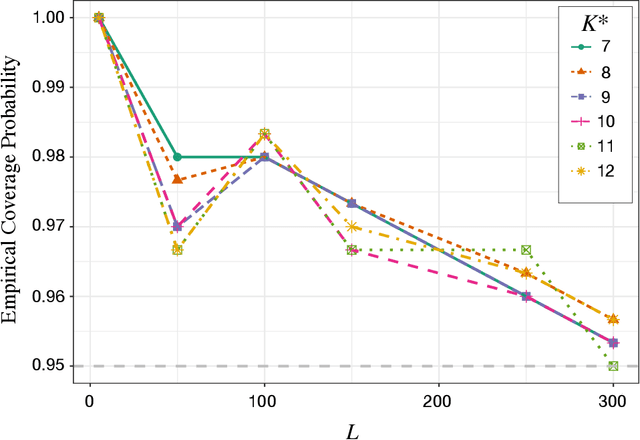
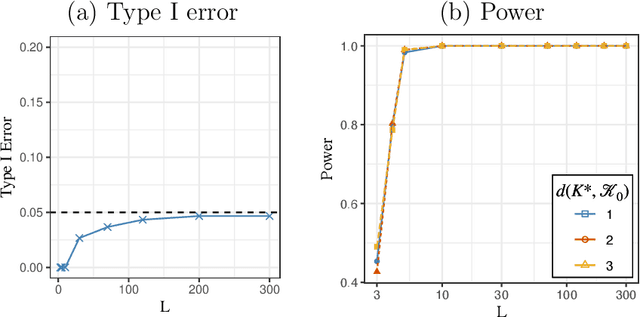
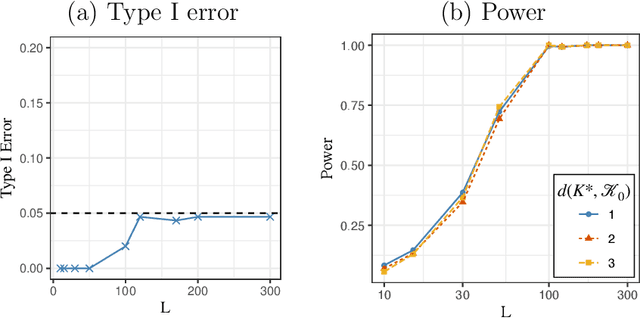
Assortment optimization has received active explorations in the past few decades due to its practical importance. Despite the extensive literature dealing with optimization algorithms and latent score estimation, uncertainty quantification for the optimal assortment still needs to be explored and is of great practical significance. Instead of estimating and recovering the complete optimal offer set, decision-makers may only be interested in testing whether a given property holds true for the optimal assortment, such as whether they should include several products of interest in the optimal set, or how many categories of products the optimal set should include. This paper proposes a novel inferential framework for testing such properties. We consider the widely adopted multinomial logit (MNL) model, where we assume that each customer will purchase an item within the offered products with a probability proportional to the underlying preference score associated with the product. We reduce inferring a general optimal assortment property to quantifying the uncertainty associated with the sign change point detection of the marginal revenue gaps. We show the asymptotic normality of the marginal revenue gap estimator, and construct a maximum statistic via the gap estimators to detect the sign change point. By approximating the distribution of the maximum statistic with multiplier bootstrap techniques, we propose a valid testing procedure. We also conduct numerical experiments to assess the performance of our method.
Federated Offline Reinforcement Learning
Jun 11, 2022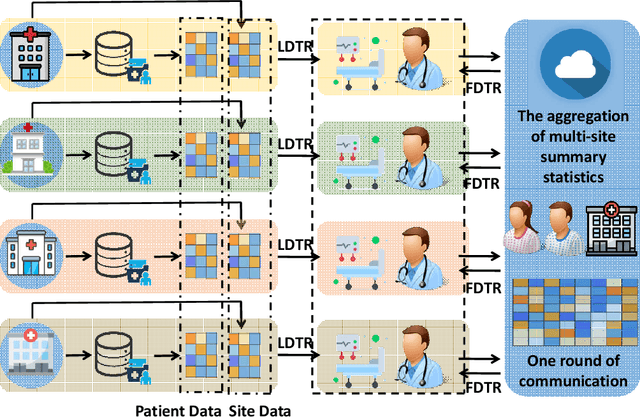
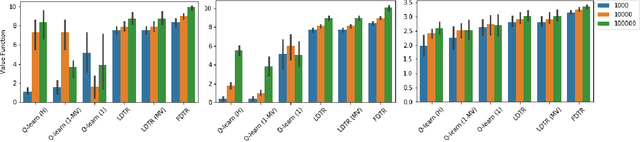
Evidence-based or data-driven dynamic treatment regimes are essential for personalized medicine, which can benefit from offline reinforcement learning (RL). Although massive healthcare data are available across medical institutions, they are prohibited from sharing due to privacy constraints. Besides, heterogeneity exists in different sites. As a result, federated offline RL algorithms are necessary and promising to deal with the problems. In this paper, we propose a multi-site Markov decision process model which allows both homogeneous and heterogeneous effects across sites. The proposed model makes the analysis of the site-level features possible. We design the first federated policy optimization algorithm for offline RL with sample complexity. The proposed algorithm is communication-efficient and privacy-preserving, which requires only a single round of communication interaction by exchanging summary statistics. We give a theoretical guarantee for the proposed algorithm without the assumption of sufficient action coverage, where the suboptimality for the learned policies is comparable to the rate as if data is not distributed. Extensive simulations demonstrate the effectiveness of the proposed algorithm. The method is applied to a sepsis data set in multiple sites to illustrate its use in clinical settings.
Lagrangian Inference for Ranking Problems
Oct 01, 2021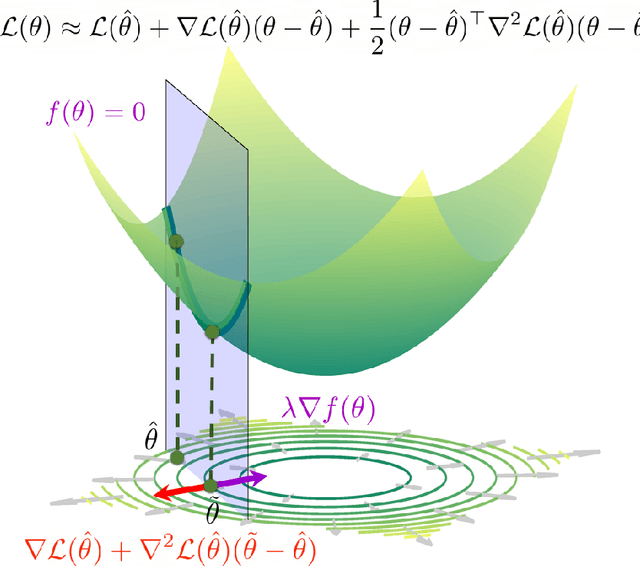
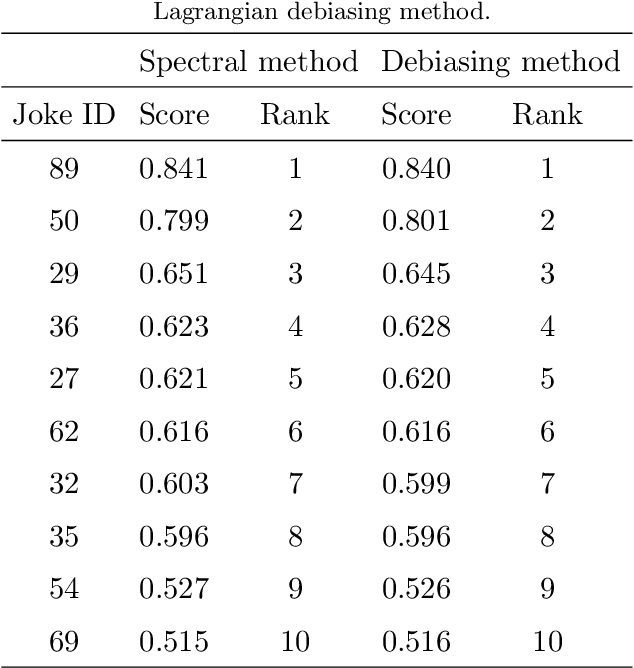

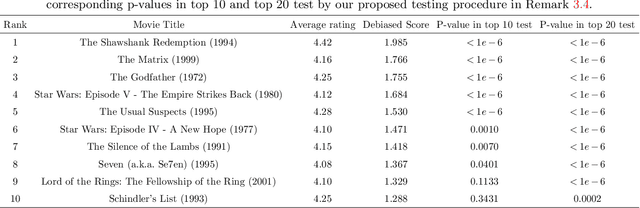
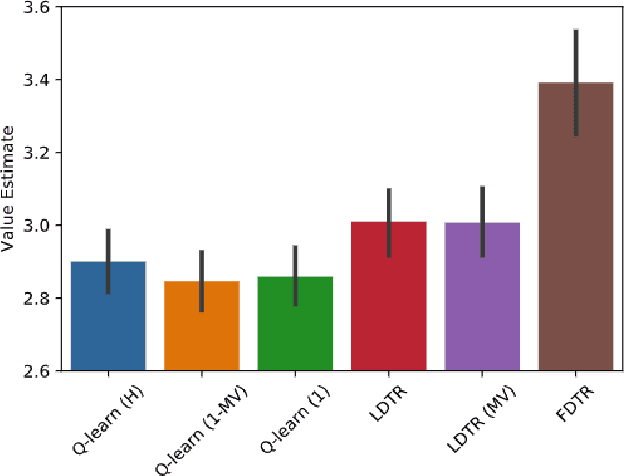
We propose a novel combinatorial inference framework to conduct general uncertainty quantification in ranking problems. We consider the widely adopted Bradley-Terry-Luce (BTL) model, where each item is assigned a positive preference score that determines the Bernoulli distributions of pairwise comparisons' outcomes. Our proposed method aims to infer general ranking properties of the BTL model. The general ranking properties include the "local" properties such as if an item is preferred over another and the "global" properties such as if an item is among the top $K$-ranked items. We further generalize our inferential framework to multiple testing problems where we control the false discovery rate (FDR), and apply the method to infer the top-$K$ ranked items. We also derive the information-theoretic lower bound to justify the minimax optimality of the proposed method. We conduct extensive numerical studies using both synthetic and real datasets to back up our theory.