 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-optimal Sequential Testing via Doubly Robust Q-learning
Apr 13, 2026Clinical decision-making often involves selecting tests that are costly, invasive, or time-consuming, motivating individualized, sequential strategies for what to measure and when to stop ascertaining. We study the problem of learning cost-optimal sequential decision policies from retrospective data, where test availability depends on prior results, inducing informative missingness. Under a sequential missing-at-random mechanism, we develop a doubly robust Q-learning framework for estimating optimal policies. The method introduces path-specific inverse probability weights that account for heterogeneous test trajectories and satisfy a normalization property conditional on the observed history. By combining these weights with auxiliary contrast models, we construct orthogonal pseudo-outcomes that enable unbiased policy learning when either the acquisition model or the contrast model is correctly specified. We establish oracle inequalities for the stage-wise contrast estimators, along with convergence rates, regret bounds, and misclassification rates for the learned policy. Simulations demonstrate improved cost-adjusted performance over weighted and complete-case baselines, and an application to a prostate cancer cohort study illustrates how the method reduces testing cost without compromising predictive accuracy.
Hierarchical Contrastive Learning for Multimodal Data
Apr 07, 2026Multimodal representation learning is commonly built on a shared-private decomposition, treating latent information as either common to all modalities or specific to one. This binary view is often inadequate: many factors are shared by only subsets of modalities, and ignoring such partial sharing can over-align unrelated signals and obscure complementary information. We propose Hierarchical Contrastive Learning (HCL), a framework that learns globally shared, partially shared, and modality-specific representations within a unified model. HCL combines a hierarchical latent-variable formulation with structural sparsity and a structure-aware contrastive objective that aligns only modalities that genuinely share a latent factor. Under uncorrelated latent variables, we prove identifiability of the hierarchical decomposition, establish recovery guarantees for the loading matrices, and derive parameter estimation and excess-risk bounds for downstream prediction. Simulations show accurate recovery of hierarchical structure and effective selection of task-relevant components. On multimodal electronic health records, HCL yields more informative representations and consistently improves predictive performance.
Learning Sequential Decisions from Multiple Sources via Group-Robust Markov Decision Processes
Feb 02, 2026We often collect data from multiple sites (e.g., hospitals) that share common structure but also exhibit heterogeneity. This paper aims to learn robust sequential decision-making policies from such offline, multi-site datasets. To model cross-site uncertainty, we study distributionally robust MDPs with a group-linear structure: all sites share a common feature map, and both the transition kernels and expected reward functions are linear in these shared features. We introduce feature-wise (d-rectangular) uncertainty sets, which preserve tractable robust Bellman recursions while maintaining key cross-site structure. Building on this, we then develop an offline algorithm based on pessimistic value iteration that includes: (i) per-site ridge regression for Bellman targets, (ii) feature-wise worst-case (row-wise minimization) aggregation, and (iii) a data-dependent pessimism penalty computed from the diagonals of the inverse design matrices. We further propose a cluster-level extension that pools similar sites to improve sample efficiency, guided by prior knowledge of site similarity. Under a robust partial coverage assumption, we prove a suboptimality bound for the resulting policy. Overall, our framework addresses multi-site learning with heterogeneous data sources and provides a principled approach to robust planning without relying on strong state-action rectangularity assumptions.
A Judge-Aware Ranking Framework for Evaluating Large Language Models without Ground Truth
Jan 29, 2026Evaluating large language models (LLMs) on open-ended tasks without ground-truth labels is increasingly done via the LLM-as-a-judge paradigm. A critical but under-modeled issue is that judge LLMs differ substantially in reliability; treating all judges equally can yield biased leaderboards and misleading uncertainty estimates. More data can make evaluation more confidently wrong under misspecified aggregation. We propose a judge-aware ranking framework that extends the Bradley-Terry-Luce model by introducing judge-specific discrimination parameters, jointly estimating latent model quality and judge reliability from pairwise comparisons without reference labels. We establish identifiability up to natural normalizations and prove consistency and asymptotic normality of the maximum likelihood estimator, enabling confidence intervals for score differences and rank comparisons. Across multiple public benchmarks and a newly collected dataset, our method improves agreement with human preferences, achieves higher data efficiency than unweighted baselines, and produces calibrated uncertainty quantification for LLM rankings.
From Hawkes Processes to Attention: Time-Modulated Mechanisms for Event Sequences
Jan 14, 2026Marked Temporal Point Processes (MTPPs) arise naturally in medical, social, commercial, and financial domains. However, existing Transformer-based methods mostly inject temporal information only via positional encodings, relying on shared or parametric decay structures, which limits their ability to capture heterogeneous and type-specific temporal effects. Inspired by this observation, we derive a novel attention operator called Hawkes Attention from the multivariate Hawkes process theory for MTPP, using learnable per-type neural kernels to modulate query, key and value projections, thereby replacing the corresponding parts in the traditional attention. Benefited from the design, Hawkes Attention unifies event timing and content interaction, learning both the time-relevant behavior and type-specific excitation patterns from the data. The experimental results show that our method achieves better performance compared to the baselines. In addition to the general MTPP, our attention mechanism can also be easily applied to specific temporal structures, such as time series forecasting.
RELEAP: Reinforcement-Enhanced Label-Efficient Active Phenotyping for Electronic Health Records
Nov 08, 2025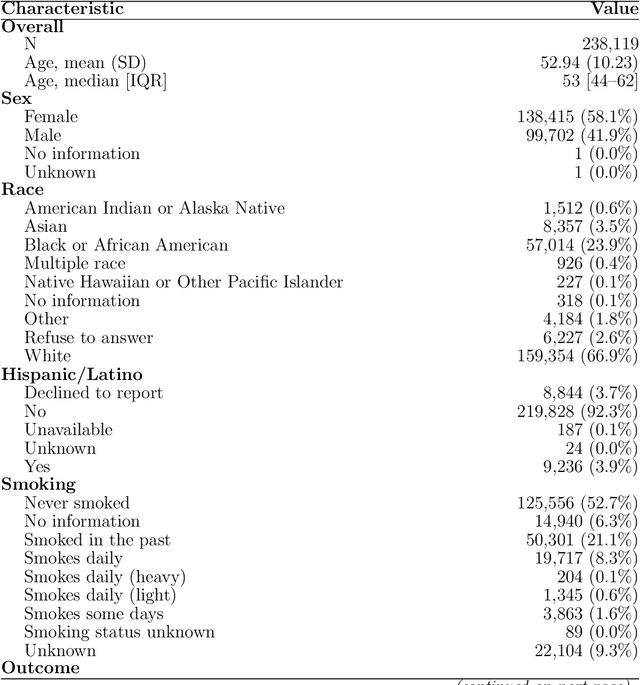
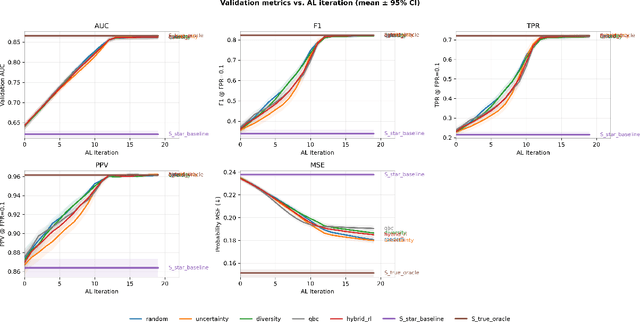

Objective: Electronic health record (EHR) phenotyping often relies on noisy proxy labels, which undermine the reliability of downstream risk prediction. Active learning can reduce annotation costs, but most rely on fixed heuristics and do not ensure that phenotype refinement improves prediction performance. Our goal was to develop a framework that directly uses downstream prediction performance as feedback to guide phenotype correction and sample selection under constrained labeling budgets. Materials and Methods: We propose Reinforcement-Enhanced Label-Efficient Active Phenotyping (RELEAP), a reinforcement learning-based active learning framework. RELEAP adaptively integrates multiple querying strategies and, unlike prior methods, updates its policy based on feedback from downstream models. We evaluated RELEAP on a de-identified Duke University Health System (DUHS) cohort (2014-2024) for incident lung cancer risk prediction, using logistic regression and penalized Cox survival models. Performance was benchmarked against noisy-label baselines and single-strategy active learning. Results: RELEAP consistently outperformed all baselines. Logistic AUC increased from 0.774 to 0.805 and survival C-index from 0.718 to 0.752. Using downstream performance as feedback, RELEAP produced smoother and more stable gains than heuristic methods under the same labeling budget. Discussion: By linking phenotype refinement to prediction outcomes, RELEAP learns which samples most improve downstream discrimination and calibration, offering a more principled alternative to fixed active learning rules. Conclusion: RELEAP optimizes phenotype correction through downstream feedback, offering a scalable, label-efficient paradigm that reduces manual chart review and enhances the reliability of EHR-based risk prediction.
PEHRT: A Common Pipeline for Harmonizing Electronic Health Record data for Translational Research
Sep 10, 2025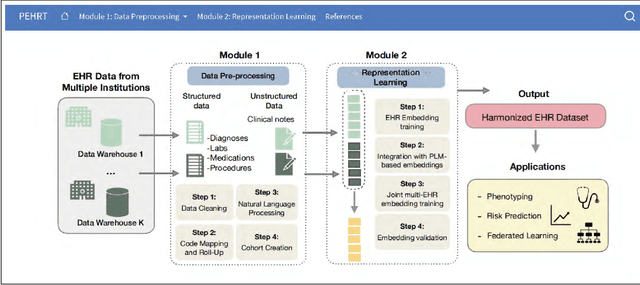
Integrative analysis of multi-institutional Electronic Health Record (EHR) data enhances the reliability and generalizability of translational research by leveraging larger, more diverse patient cohorts and incorporating multiple data modalities. However, harmonizing EHR data across institutions poses major challenges due to data heterogeneity, semantic differences, and privacy concerns. To address these challenges, we introduce $\textit{PEHRT}$, a standardized pipeline for efficient EHR data harmonization consisting of two core modules: (1) data pre-processing and (2) representation learning. PEHRT maps EHR data to standard coding systems and uses advanced machine learning to generate research-ready datasets without requiring individual-level data sharing. Our pipeline is also data model agnostic and designed for streamlined execution across institutions based on our extensive real-world experience. We provide a complete suite of open source software, accompanied by a user-friendly tutorial, and demonstrate the utility of PEHRT in a variety of tasks using data from diverse healthcare systems.
Single Index Bandits: Generalized Linear Contextual Bandits with Unknown Reward Functions
Jun 15, 2025Generalized linear bandits have been extensively studied due to their broad applicability in real-world online decision-making problems. However, these methods typically assume that the expected reward function is known to the users, an assumption that is often unrealistic in practice. Misspecification of this link function can lead to the failure of all existing algorithms. In this work, we address this critical limitation by introducing a new problem of generalized linear bandits with unknown reward functions, also known as single index bandits. We first consider the case where the unknown reward function is monotonically increasing, and propose two novel and efficient algorithms, STOR and ESTOR, that achieve decent regrets under standard assumptions. Notably, our ESTOR can obtain the nearly optimal regret bound $\tilde{O}_T(\sqrt{T})$ in terms of the time horizon $T$. We then extend our methods to the high-dimensional sparse setting and show that the same regret rate can be attained with the sparsity index. Next, we introduce GSTOR, an algorithm that is agnostic to general reward functions, and establish regret bounds under a Gaussian design assumption. Finally, we validate the efficiency and effectiveness of our algorithms through experiments on both synthetic and real-world datasets.
Wasserstein Transfer Learning
May 23, 2025Transfer learning is a powerful paradigm for leveraging knowledge from source domains to enhance learning in a target domain. However, traditional transfer learning approaches often focus on scalar or multivariate data within Euclidean spaces, limiting their applicability to complex data structures such as probability distributions. To address this, we introduce a novel framework for transfer learning in regression models, where outputs are probability distributions residing in the Wasserstein space. When the informative subset of transferable source domains is known, we propose an estimator with provable asymptotic convergence rates, quantifying the impact of domain similarity on transfer efficiency. For cases where the informative subset is unknown, we develop a data-driven transfer learning procedure designed to mitigate negative transfer. The proposed methods are supported by rigorous theoretical analysis and are validated through extensive simulations and real-world applications.
Toward Fair Federated Learning under Demographic Disparities and Data Imbalance
May 14, 2025Ensuring fairness is critical when applying artificial intelligence to high-stakes domains such as healthcare, where predictive models trained on imbalanced and demographically skewed data risk exacerbating existing disparities. Federated learning (FL) enables privacy-preserving collaboration across institutions, but remains vulnerable to both algorithmic bias and subgroup imbalance - particularly when multiple sensitive attributes intersect. We propose FedIDA (Fed erated Learning for Imbalance and D isparity A wareness), a framework-agnostic method that combines fairness-aware regularization with group-conditional oversampling. FedIDA supports multiple sensitive attributes and heterogeneous data distributions without altering the convergence behavior of the underlying FL algorithm. We provide theoretical analysis establishing fairness improvement bounds using Lipschitz continuity and concentration inequalities, and show that FedIDA reduces the variance of fairness metrics across test sets. Empirical results on both benchmark and real-world clinical datasets confirm that FedIDA consistently improves fairness while maintaining competitive predictive performance, demonstrating its effectiveness for equitable and privacy-preserving modeling in healthcare. The source code is available on GitHub.