 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus Knowledge Graph Learning via Multi-view Sparse Low Rank Block Model
Sep 28, 2022
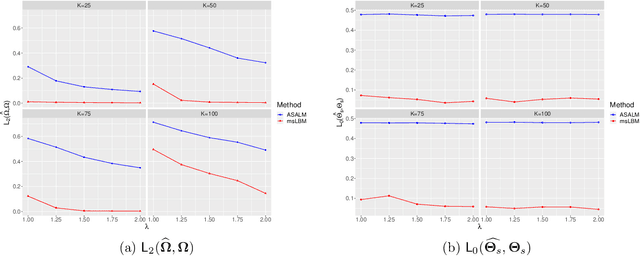

Network analysis has been a powerful tool to unveil relationships and interactions among a large number of objects. Yet its effectiveness in accurately identifying important node-node interactions is challenged by the rapidly growing network size, with data being collected at an unprecedented granularity and scale. Common wisdom to overcome such high dimensionality is collapsing nodes into smaller groups and conducting connectivity analysis on the group level. Dividing efforts into two phases inevitably opens a gap in consistency and drives down efficiency. Consensus learning emerges as a new normal for common knowledge discovery with multiple data sources available. To this end, this paper features developing a unified framework of simultaneous grouping and connectivity analysis by combining multiple data sources. The algorithm also guarantees a statistically optimal estimator.
Dantzig Selector with an Approximately Optimal Denoising Matrix and its Application to Reinforcement Learning
Nov 02, 2018
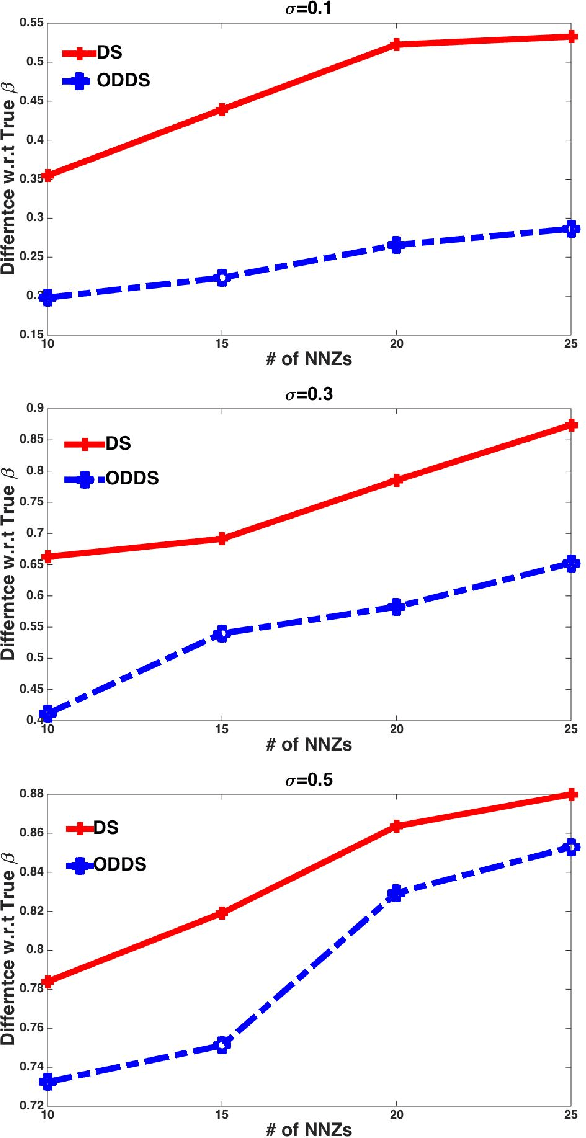


Dantzig Selector (DS) is widely used in compressed sensing and sparse learning for feature selection and sparse signal recovery. Since the DS formulation is essentially a linear programming optimization, many existing linear programming solvers can be simply applied for scaling up. The DS formulation can be explained as a basis pursuit denoising problem, wherein the data matrix (or measurement matrix) is employed as the denoising matrix to eliminate the observation noise. However, we notice that the data matrix may not be the optimal denoising matrix, as shown by a simple counter-example. This motivates us to pursue a better denoising matrix for defining a general DS formulation. We first define the optimal denoising matrix through a minimax optimization, which turns out to be an NPhard problem. To make the problem computationally tractable, we propose a novel algorithm, termed as Optimal Denoising Dantzig Selector (ODDS), to approximately estimate the optimal denoising matrix. Empirical experiments validate the proposed method. Finally, a novel sparse reinforcement learning algorithm is formulated by extending the proposed ODDS algorithm to temporal difference learning, and empirical experimental results demonstrate to outperform the conventional vanilla DS-TD algorithm.
Unsupervised Ensemble Learning via Ising Model Approximation with Application to Phenotyping Prediction
Oct 15, 2018
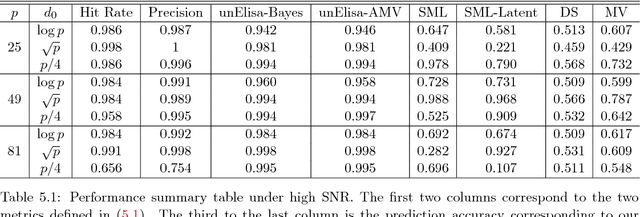
Unsupervised ensemble learning has long been an interesting yet challenging problem that comes to prominence in recent years with the increasing demand of crowdsourcing in various applications. In this paper, we propose a novel method-- unsupervised ensemble learning via Ising model approximation (unElisa) that combines a pruning step with a predicting step. We focus on the binary case and use an Ising model to characterize interactions between the ensemble and the underlying true classifier. The presence of an edge between an observed classifier and the true classifier indicates a direct dependence whereas the absence indicates the corresponding one provides no additional information and shall be eliminated. This observation leads to the pruning step where the key is to recover the neighborhood of the true classifier. We show that it can be recovered successfully with exponentially decaying error in the high-dimensional setting by performing nodewise $\ell_1$-regularized logistic regression. The pruned ensemble allows us to get a consistent estimate of the Bayes classifier for predicting. We also propose an augmented version of majority voting by reversing all labels given by a subgroup of the pruned ensemble. We demonstrate the efficacy of our method through extensive numerical experiments and through the application to EHR-based phenotyping prediction on Rheumatoid Arthritis (RA) using data from Partners Healthcare System.
Multi-view Banded Spectral Clustering with Application to ICD9 Clustering
Jun 20, 2018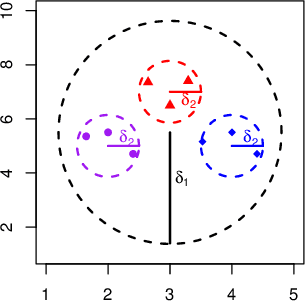
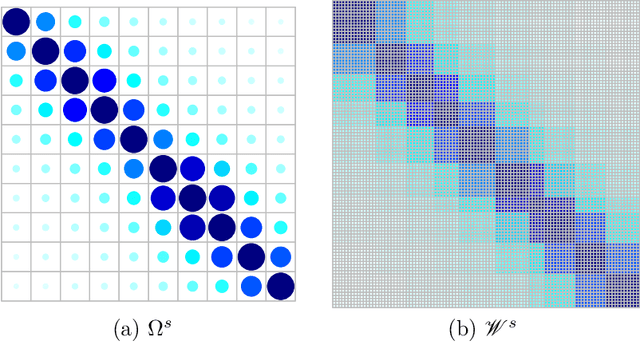
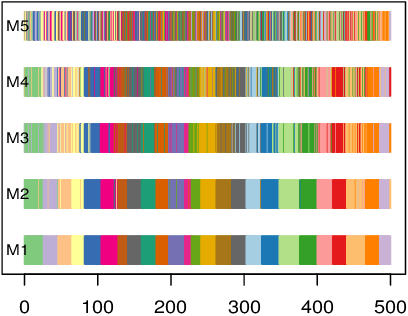
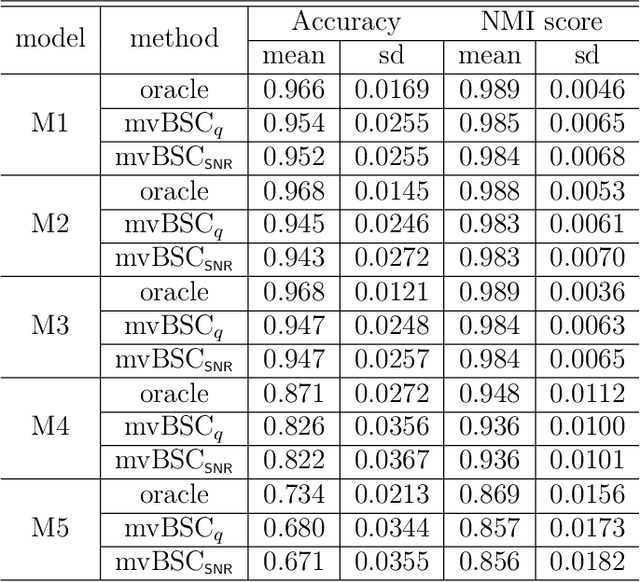
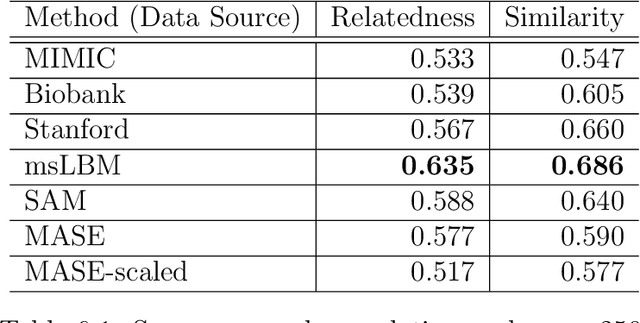
Despite recent development in methodology, community detection remains a challenging problem. Existing literature largely focuses on the standard setting where a network is learned using an observed adjacency matrix from a single data source. Constructing a shared network from multiple data sources is more challenging due to the heterogeneity across populations. Additionally, no existing method leverages the prior distance knowledge available in many domains to help the discovery of the network structure. To bridge this gap, in this paper we propose a novel spectral clustering method that optimally combines multiple data sources while leveraging the prior distance knowledge. The proposed method combines a banding step guided by the distance knowledge with a subsequent weighting step to maximize consensus across multiple sources. Its statistical performance is thoroughly studied under a multi-view stochastic block model. We also provide a simple yet optimal rule of choosing weights in practice. The efficacy and robustness of the method is fully demonstrated through extensive simulations. Finally, we apply the method to cluster the International classification of diseases, ninth revision (ICD9), codes and yield a very insightful clustering structure by integrating information from a large claim database and two healthcare systems.
Distance Shrinkage and Euclidean Embedding via Regularized Kernel Estimation
Sep 17, 2014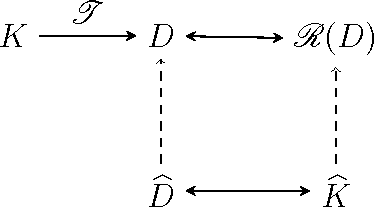

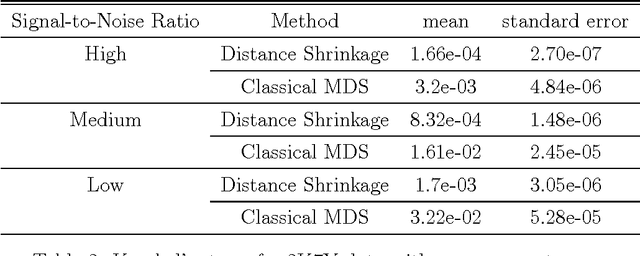

Although recovering an Euclidean distance matrix from noisy observations is a common problem in practice, how well this could be done remains largely unknown. To fill in this void, we study a simple distance matrix estimate based upon the so-called regularized kernel estimate. We show that such an estimate can be characterized as simply applying a constant amount of shrinkage to all observed pairwise distances. This fact allows us to establish risk bounds for the estimate implying that the true distances can be estimated consistently in an average sense as the number of objects increases. In addition, such a characterization suggests an efficient algorithm to compute the distance matrix estimator, as an alternative to the usual second order cone programming known not to scale well for large problems. Numerical experiments and an application in visualizing the diversity of Vpu protein sequences from a recent HIV-1 study further demonstrate the practical merits of the proposed method.