 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSVM-UNet : Enhancing VM-UNet with Dual Self-distillation for Medical Image Segmentation
Jan 27, 2026Vision Mamba models have been extensively researched in various fields, which address the limitations of previous models by effectively managing long-range dependencies with a linear-time overhead. Several prospective studies have further designed Vision Mamba based on UNet(VM-UNet) for medical image segmentation. These approaches primarily focus on optimizing architectural designs by creating more complex structures to enhance the model's ability to perceive semantic features. In this paper, we propose a simple yet effective approach to improve the model by Dual Self-distillation for VM-UNet (DSVM-UNet) without any complex architectural designs. To achieve this goal, we develop double self-distillation methods to align the features at both the global and local levels. Extensive experiments conducted on the ISIC2017, ISIC2018, and Synapse benchmarks demonstrate that our approach achieves state-of-the-art performance while maintaining computational efficiency. Code is available at https://github.com/RoryShao/DSVM-UNet.git.
* 5 pages, 1 figures
Statistical Inference for Matching Decisions via Matrix Completion under Dependent Missingness
Oct 30, 2025This paper studies decision-making and statistical inference for two-sided matching markets via matrix completion. In contrast to the independent sampling assumed in classical matrix completion literature, the observed entries, which arise from past matching data, are constrained by matching capacity. This matching-induced dependence poses new challenges for both estimation and inference in the matrix completion framework. We propose a non-convex algorithm based on Grassmannian gradient descent and establish near-optimal entrywise convergence rates for three canonical mechanisms, i.e., one-to-one matching, one-to-many matching with one-sided random arrival, and two-sided random arrival. To facilitate valid uncertainty quantification and hypothesis testing on matching decisions, we further develop a general debiasing and projection framework for arbitrary linear forms of the reward matrix, deriving asymptotic normality with finite-sample guarantees under matching-induced dependent sampling. Our empirical experiments demonstrate that the proposed approach provides accurate estimation, valid confidence intervals, and efficient evaluation of matching policies.
Federated PCA and Estimation for Spiked Covariance Matrices: Optimal Rates and Efficient Algorithm
Nov 23, 2024


Federated Learning (FL) has gained significant recent attention in machine learning for its enhanced privacy and data security, making it indispensable in fields such as healthcare, finance, and personalized services. This paper investigates federated PCA and estimation for spiked covariance matrices under distributed differential privacy constraints. We establish minimax rates of convergence, with a key finding that the central server's optimal rate is the harmonic mean of the local clients' minimax rates. This guarantees consistent estimation at the central server as long as at least one local client provides consistent results. Notably, consistency is maintained even if some local estimators are inconsistent, provided there are enough clients. These findings highlight the robustness and scalability of FL for reliable statistical inference under privacy constraints. To establish minimax lower bounds, we derive a matrix version of van Trees' inequality, which is of independent interest. Furthermore, we propose an efficient algorithm that preserves differential privacy while achieving near-optimal rates at the central server, up to a logarithmic factor. We address significant technical challenges in analyzing this algorithm, which involves a three-layer spectral decomposition. Numerical performance of the proposed algorithm is investigated using both simulated and real data.
Regret Minimization and Statistical Inference in Online Decision Making with High-dimensional Covariates
Nov 10, 2024



This paper investigates regret minimization, statistical inference, and their interplay in high-dimensional online decision-making based on the sparse linear context bandit model. We integrate the $\varepsilon$-greedy bandit algorithm for decision-making with a hard thresholding algorithm for estimating sparse bandit parameters and introduce an inference framework based on a debiasing method using inverse propensity weighting. Under a margin condition, our method achieves either $O(T^{1/2})$ regret or classical $O(T^{1/2})$-consistent inference, indicating an unavoidable trade-off between exploration and exploitation. If a diverse covariate condition holds, we demonstrate that a pure-greedy bandit algorithm, i.e., exploration-free, combined with a debiased estimator based on average weighting can simultaneously achieve optimal $O(\log T)$ regret and $O(T^{1/2})$-consistent inference. We also show that a simple sample mean estimator can provide valid inference for the optimal policy's value. Numerical simulations and experiments on Warfarin dosing data validate the effectiveness of our methods.
Statistical Inference in Tensor Completion: Optimal Uncertainty Quantification and Statistical-Computational Gaps
Oct 15, 2024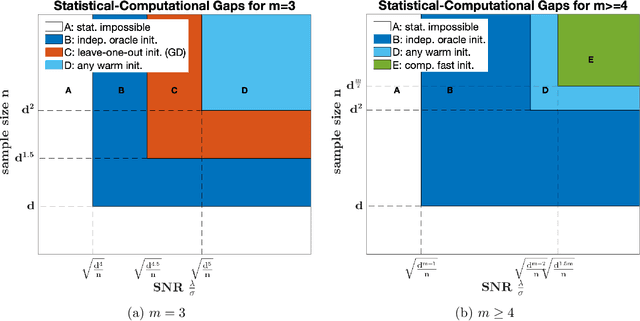


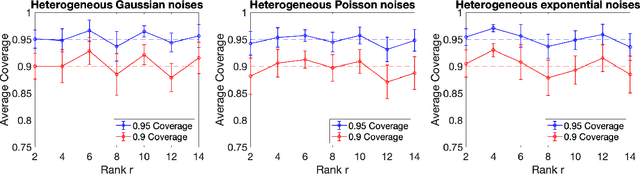
This paper presents a simple yet efficient method for statistical inference of tensor linear forms with incomplete and noisy observations. Under the Tucker low-rank tensor model, we utilize an appropriate initial estimate, along with a debiasing technique followed by a one-step power iteration, to construct an asymptotic normal test statistic. This method is suitable for various statistical inference tasks, including confidence interval prediction, inference under heteroskedastic and sub-exponential noises, and simultaneous testing. Furthermore, the approach reaches the Cram\'er-Rao lower bound for statistical estimation on Riemannian manifolds, indicating its optimality for uncertainty quantification. We comprehensively discusses the statistical-computational gaps and investigates the relationship between initialization and bias-correlation approaches. The findings demonstrate that with independent initialization, statistically optimal sample sizes and signal-to-noise ratios are sufficient for accurate inferences. Conversely, when initialization depends on the observations, computationally optimal sample sizes and signal-to-noise ratios also guarantee asymptotic normality without the need for data-splitting. The phase transition of computational and statistical limits is presented. Numerical simulations results conform to the theoretical discoveries.
Local Prediction-Powered Inference
Sep 26, 2024
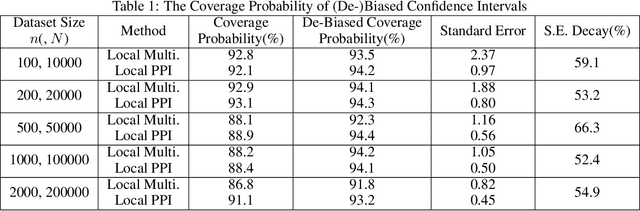


To infer a function value on a specific point $x$, it is essential to assign higher weights to the points closer to $x$, which is called local polynomial / multivariable regression. In many practical cases, a limited sample size may ruin this method, but such conditions can be improved by the Prediction-Powered Inference (PPI) technique. This paper introduced a specific algorithm for local multivariable regression using PPI, which can significantly reduce the variance of estimations without enlarge the error. The confidence intervals, bias correction, and coverage probabilities are analyzed and proved the correctness and superiority of our algorithm. Numerical simulation and real-data experiments are applied and show these conclusions. Another contribution compared to PPI is the theoretical computation efficiency and explainability by taking into account the dependency of the dependent variable.
Tensor Methods in High Dimensional Data Analysis: Opportunities and Challenges
May 28, 2024

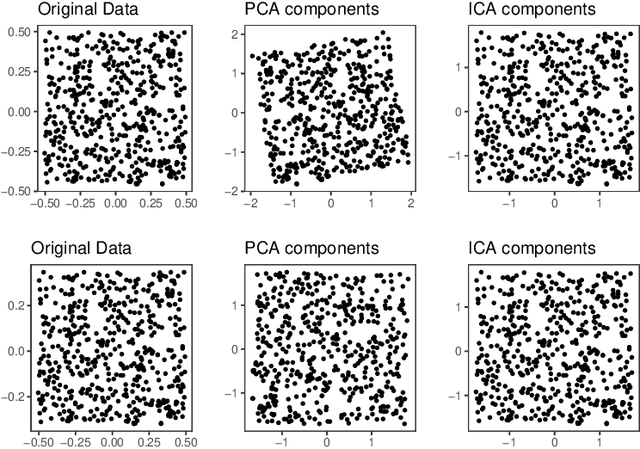

Large amount of multidimensional data represented by multiway arrays or tensors are prevalent in modern applications across various fields such as chemometrics, genomics, physics, psychology, and signal processing. The structural complexity of such data provides vast new opportunities for modeling and analysis, but efficiently extracting information content from them, both statistically and computationally, presents unique and fundamental challenges. Addressing these challenges requires an interdisciplinary approach that brings together tools and insights from statistics, optimization and numerical linear algebra among other fields. Despite these hurdles, significant progress has been made in the last decade. This review seeks to examine some of the key advancements and identify common threads among them, under eight different statistical settings.
Online Policy Learning and Inference by Matrix Completion
Apr 26, 2024Making online decisions can be challenging when features are sparse and orthogonal to historical ones, especially when the optimal policy is learned through collaborative filtering. We formulate the problem as a matrix completion bandit (MCB), where the expected reward under each arm is characterized by an unknown low-rank matrix. The $\epsilon$-greedy bandit and the online gradient descent algorithm are explored. Policy learning and regret performance are studied under a specific schedule for exploration probabilities and step sizes. A faster decaying exploration probability yields smaller regret but learns the optimal policy less accurately. We investigate an online debiasing method based on inverse propensity weighting (IPW) and a general framework for online policy inference. The IPW-based estimators are asymptotically normal under mild arm-optimality conditions. Numerical simulations corroborate our theoretical findings. Our methods are applied to the San Francisco parking pricing project data, revealing intriguing discoveries and outperforming the benchmark policy.
Optimal Differentially Private PCA and Estimation for Spiked Covariance Matrices
Jan 08, 2024


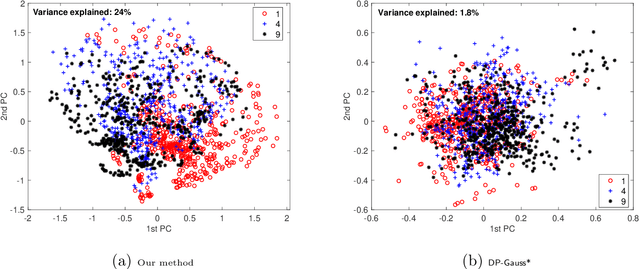
Estimating a covariance matrix and its associated principal components is a fundamental problem in contemporary statistics. While optimal estimation procedures have been developed with well-understood properties, the increasing demand for privacy preservation introduces new complexities to this classical problem. In this paper, we study optimal differentially private Principal Component Analysis (PCA) and covariance estimation within the spiked covariance model. We precisely characterize the sensitivity of eigenvalues and eigenvectors under this model and establish the minimax rates of convergence for estimating both the principal components and covariance matrix. These rates hold up to logarithmic factors and encompass general Schatten norms, including spectral norm, Frobenius norm, and nuclear norm as special cases. We introduce computationally efficient differentially private estimators and prove their minimax optimality, up to logarithmic factors. Additionally, matching minimax lower bounds are established. Notably, in comparison with existing literature, our results accommodate a diverging rank, necessitate no eigengap condition between distinct principal components, and remain valid even if the sample size is much smaller than the dimension.
Multiple Testing of Linear Forms for Noisy Matrix Completion
Dec 01, 2023



Many important tasks of large-scale recommender systems can be naturally cast as testing multiple linear forms for noisy matrix completion. These problems, however, present unique challenges because of the subtle bias-and-variance tradeoff of and an intricate dependence among the estimated entries induced by the low-rank structure. In this paper, we develop a general approach to overcome these difficulties by introducing new statistics for individual tests with sharp asymptotics both marginally and jointly, and utilizing them to control the false discovery rate (FDR) via a data splitting and symmetric aggregation scheme. We show that valid FDR control can be achieved with guaranteed power under nearly optimal sample size requirements using the proposed methodology. Extensive numerical simulations and real data examples are also presented to further illustrate its practical merits.