 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Limits and Efficient Algorithms for Differentially Private Federated Learning
May 18, 2026Federated Learning is a leading framework for training ML and AI models collaboratively across numerous user devices or databases. We study the trade-offs among estimation accuracy, privacy constraints, and communication cost for differentially private (DP) federated M estimation. The two standard methods in the literature are FedAvg, which may suffer from high federation bias, and FedSGD, which can incur high communication cost. Aimed at improving accuracy at a reduced communication cost, we propose FedHybrid, which uses FedSGD starting with an improved initialization by the FedAvg estimator. We propose FedNewton, which averages local Newton iterations to reduce bias in FedAvg, achieving an estimation accuracy comparable to FedSGD with much fewer communication rounds when the number of clients grows sufficiently slowly. We establish finite sample upper bounds on the mean-squared error rates of the DP versions of these estimators as functions of the number of clients, local sample sizes, privacy budget, and number of iterations. We further derive a minimax lower bound on the MSE of any iterative private federated procedure that provides a benchmark to assess the optimality gap of these methods. We numerically evaluate our methods for training a logistic regression and a neural network on the computer vision datasets MNIST and CIFAR-10.
Newfluence: Boosting Model interpretability and Understanding in High Dimensions
Jul 16, 2025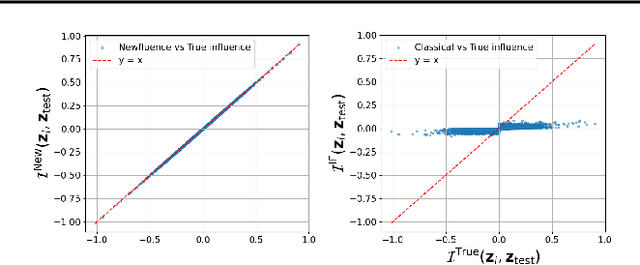


The increasing complexity of machine learning (ML) and artificial intelligence (AI) models has created a pressing need for tools that help scientists, engineers, and policymakers interpret and refine model decisions and predictions. Influence functions, originating from robust statistics, have emerged as a popular approach for this purpose. However, the heuristic foundations of influence functions rely on low-dimensional assumptions where the number of parameters $p$ is much smaller than the number of observations $n$. In contrast, modern AI models often operate in high-dimensional regimes with large $p$, challenging these assumptions. In this paper, we examine the accuracy of influence functions in high-dimensional settings. Our theoretical and empirical analyses reveal that influence functions cannot reliably fulfill their intended purpose. We then introduce an alternative approximation, called Newfluence, that maintains similar computational efficiency while offering significantly improved accuracy. Newfluence is expected to provide more accurate insights than many existing methods for interpreting complex AI models and diagnosing their issues. Moreover, the high-dimensional framework we develop in this paper can also be applied to analyze other popular techniques, such as Shapley values.
Certified Data Removal Under High-dimensional Settings
May 12, 2025



Machine unlearning focuses on the computationally efficient removal of specific training data from trained models, ensuring that the influence of forgotten data is effectively eliminated without the need for full retraining. Despite advances in low-dimensional settings, where the number of parameters \( p \) is much smaller than the sample size \( n \), extending similar theoretical guarantees to high-dimensional regimes remains challenging. We propose an unlearning algorithm that starts from the original model parameters and performs a theory-guided sequence of Newton steps \( T \in \{ 1,2\}\). After this update, carefully scaled isotropic Laplacian noise is added to the estimate to ensure that any (potential) residual influence of forget data is completely removed. We show that when both \( n, p \to \infty \) with a fixed ratio \( n/p \), significant theoretical and computational obstacles arise due to the interplay between the complexity of the model and the finite signal-to-noise ratio. Finally, we show that, unlike in low-dimensional settings, a single Newton step is insufficient for effective unlearning in high-dimensional problems -- however, two steps are enough to achieve the desired certifiebility. We provide numerical experiments to support the certifiability and accuracy claims of this approach.
Transfer learning via Regularized Linear Discriminant Analysis
Jan 08, 2025



Linear discriminant analysis is a widely used method for classification. However, the high dimensionality of predictors combined with small sample sizes often results in large classification errors. To address this challenge, it is crucial to leverage data from related source models to enhance the classification performance of a target model. We propose to address this problem in the framework of transfer learning. In this paper, we present novel transfer learning methods via regularized random-effects linear discriminant analysis, where the discriminant direction is estimated as a weighted combination of ridge estimates obtained from both the target and source models. Multiple strategies for determining these weights are introduced and evaluated, including one that minimizes the estimation risk of the discriminant vector and another that minimizes the classification error. Utilizing results from random matrix theory, we explicitly derive the asymptotic values of these weights and the associated classification error rates in the high-dimensional setting, where $p/n \rightarrow \gamma$, with $p$ representing the predictor dimension and $n$ the sample size. We also provide geometric interpretations of various weights and a guidance on which weights to choose. Extensive numerical studies, including simulations and analysis of proteomics-based 10-year cardiovascular disease risk classification, demonstrate the effectiveness of the proposed approach.
Minimax And Adaptive Transfer Learning for Nonparametric Classification under Distributed Differential Privacy Constraints
Jun 28, 2024



This paper considers minimax and adaptive transfer learning for nonparametric classification under the posterior drift model with distributed differential privacy constraints. Our study is conducted within a heterogeneous framework, encompassing diverse sample sizes, varying privacy parameters, and data heterogeneity across different servers. We first establish the minimax misclassification rate, precisely characterizing the effects of privacy constraints, source samples, and target samples on classification accuracy. The results reveal interesting phase transition phenomena and highlight the intricate trade-offs between preserving privacy and achieving classification accuracy. We then develop a data-driven adaptive classifier that achieves the optimal rate within a logarithmic factor across a large collection of parameter spaces while satisfying the same set of differential privacy constraints. Simulation studies and real-world data applications further elucidate the theoretical analysis with numerical results.
Tensor Methods in High Dimensional Data Analysis: Opportunities and Challenges
May 28, 2024


Large amount of multidimensional data represented by multiway arrays or tensors are prevalent in modern applications across various fields such as chemometrics, genomics, physics, psychology, and signal processing. The structural complexity of such data provides vast new opportunities for modeling and analysis, but efficiently extracting information content from them, both statistically and computationally, presents unique and fundamental challenges. Addressing these challenges requires an interdisciplinary approach that brings together tools and insights from statistics, optimization and numerical linear algebra among other fields. Despite these hurdles, significant progress has been made in the last decade. This review seeks to examine some of the key advancements and identify common threads among them, under eight different statistical settings.
Theoretical Analysis of Leave-one-out Cross Validation for Non-differentiable Penalties under High-dimensional Settings
Feb 14, 2024Despite a large and significant body of recent work focused on estimating the out-of-sample risk of regularized models in the high dimensional regime, a theoretical understanding of this problem for non-differentiable penalties such as generalized LASSO and nuclear norm is missing. In this paper we resolve this challenge. We study this problem in the proportional high dimensional regime where both the sample size n and number of features p are large, and n/p and the signal-to-noise ratio (per observation) remain finite. We provide finite sample upper bounds on the expected squared error of leave-one-out cross-validation (LO) in estimating the out-of-sample risk. The theoretical framework presented here provides a solid foundation for elucidating empirical findings that show the accuracy of LO.
Approximate Leave-one-out Cross Validation for Regression with $\ell_1$ Regularizers (extended version)
Oct 26, 2023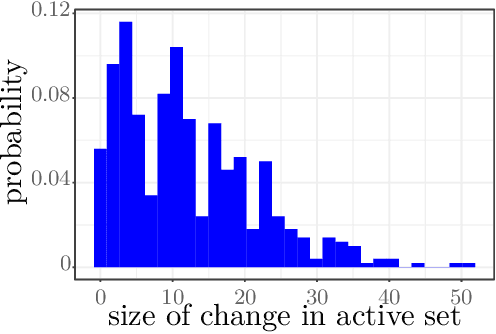

The out-of-sample error (OO) is the main quantity of interest in risk estimation and model selection. Leave-one-out cross validation (LO) offers a (nearly) distribution-free yet computationally demanding approach to estimate OO. Recent theoretical work showed that approximate leave-one-out cross validation (ALO) is a computationally efficient and statistically reliable estimate of LO (and OO) for generalized linear models with differentiable regularizers. For problems involving non-differentiable regularizers, despite significant empirical evidence, the theoretical understanding of ALO's error remains unknown. In this paper, we present a novel theory for a wide class of problems in the generalized linear model family with non-differentiable regularizers. We bound the error |ALO - LO| in terms of intuitive metrics such as the size of leave-i-out perturbations in active sets, sample size n, number of features p and regularization parameters. As a consequence, for the $\ell_1$-regularized problems, we show that |ALO - LO| goes to zero as p goes to infinity while n/p and SNR are fixed and bounded.
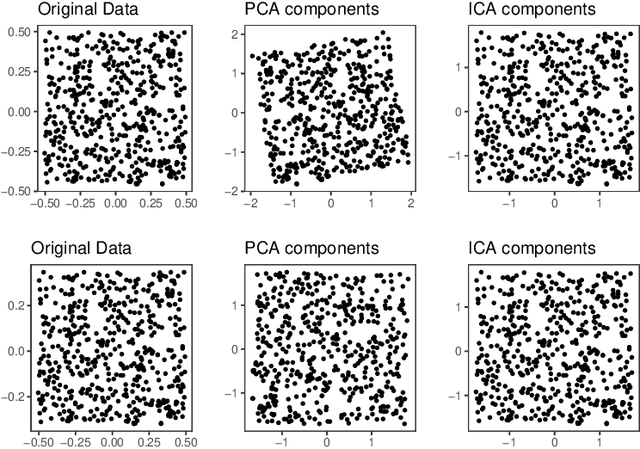
Large Dimensional Independent Component Analysis: Statistical Optimality and Computational Tractability
Mar 31, 2023
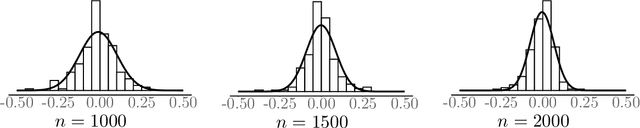
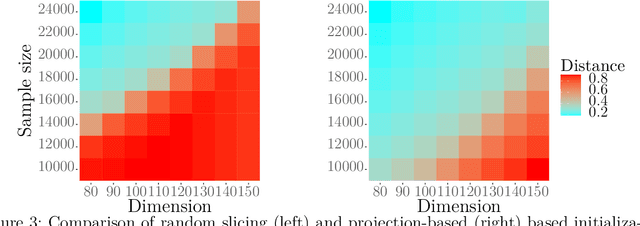
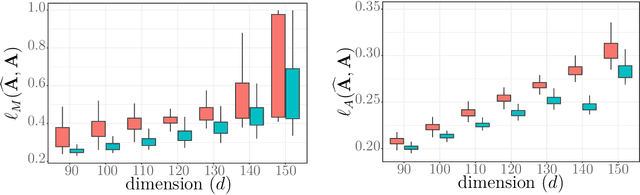
In this paper, we investigate the optimal statistical performance and the impact of computational constraints for independent component analysis (ICA). Our goal is twofold. On the one hand, we characterize the precise role of dimensionality on sample complexity and statistical accuracy, and how computational consideration may affect them. In particular, we show that the optimal sample complexity is linear in dimensionality, and interestingly, the commonly used sample kurtosis-based approaches are necessarily suboptimal. However, the optimal sample complexity becomes quadratic, up to a logarithmic factor, in the dimension if we restrict ourselves to estimates that can be computed with low-degree polynomial algorithms. On the other hand, we develop computationally tractable estimates that attain both the optimal sample complexity and minimax optimal rates of convergence. We study the asymptotic properties of the proposed estimates and establish their asymptotic normality that can be readily used for statistical inferences. Our method is fairly easy to implement and numerical experiments are presented to further demonstrate its practical merits.
On Estimating Rank-One Spiked Tensors in the Presence of Heavy Tailed Errors
Jul 20, 2021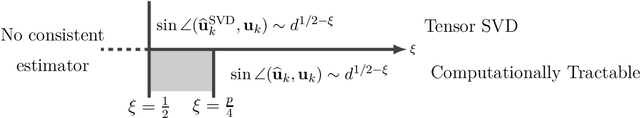
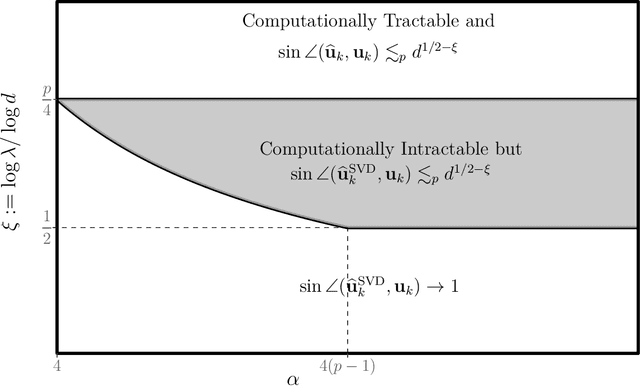
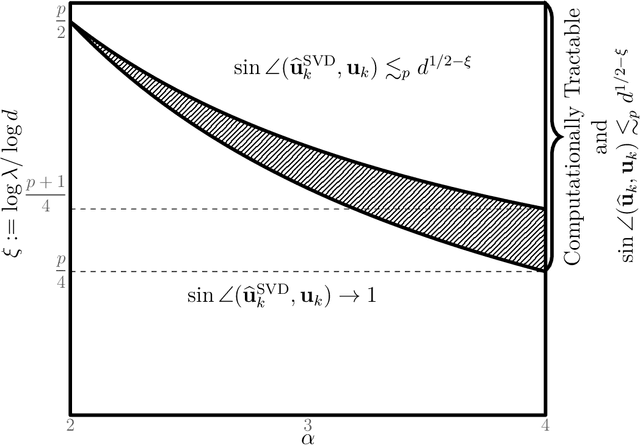
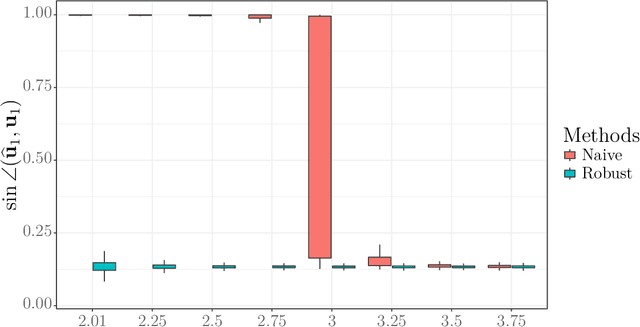
In this paper, we study the estimation of a rank-one spiked tensor in the presence of heavy tailed noise. Our results highlight some of the fundamental similarities and differences in the tradeoff between statistical and computational efficiencies under heavy tailed and Gaussian noise. In particular, we show that, for $p$ th order tensors, the tradeoff manifests in an identical fashion as the Gaussian case when the noise has finite $4(p-1)$ th moment. The difference in signal strength requirements, with or without computational constraints, for us to estimate the singular vectors at the optimal rate, interestingly, narrows for noise with heavier tails and vanishes when the noise only has finite fourth moment. Moreover, if the noise has less than fourth moment, tensor SVD, perhaps the most natural approach, is suboptimal even though it is computationally intractable. Our analysis exploits a close connection between estimating the rank-one spikes and the spectral norm of a random tensor with iid entries. In particular, we show that the order of the spectral norm of a random tensor can be precisely characterized by the moment of its entries, generalizing classical results for random matrices. In addition to the theoretical guarantees, we propose estimation procedures for the heavy tailed regime, which are easy to implement and efficient to run. Numerical experiments are presented to demonstrate their practical merits.