 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte Carlo Maximum Likelihood Reconstruction for Digital Holography with Speckle
Feb 10, 2026In coherent imaging, speckle is statistically modeled as multiplicative noise, posing a fundamental challenge for image reconstruction. While maximum likelihood estimation (MLE) provides a principled framework for speckle mitigation, its application to coherent imaging system such as digital holography with finite apertures is hindered by the prohibitive cost of high-dimensional matrix inversion, especially at high resolutions. This computational burden has prevented the use of MLE-based reconstruction with physically accurate aperture modeling. In this work, we propose a randomized linear algebra approach that enables scalable MLE optimization without explicit matrix inversions in gradient computation. By exploiting the structural properties of sensing matrix and using conjugate gradient for likelihood gradient evaluation, the proposed algorithm supports accurate aperture modeling without the simplifying assumptions commonly imposed for tractability. We term the resulting method projected gradient descent with Monte Carlo estimation (PGD-MC). The proposed PGD-MC framework (i) demonstrates robustness to diverse and physically accurate aperture models, (ii) achieves substantial improvements in reconstruction quality and computational efficiency, and (iii) scales effectively to high-resolution digital holography. Extensive experiments incorporating three representative denoisers as regularization show that PGD-MC provides a flexible and effective MLE-based reconstruction framework for digital holography with finite apertures, consistently outperforming prior Plug-and-Play model-based iterative reconstruction methods in both accuracy and speed. Our code is available at: https://github.com/Computational-Imaging-RU/MC_Maximum_Likelihood_Digital_Holography_Speckle.
Imperfect Influence, Preserved Rankings: A Theory of TRAK for Data Attribution
Feb 01, 2026Data attribution, tracing a model's prediction back to specific training data, is an important tool for interpreting sophisticated AI models. The widely used TRAK algorithm addresses this challenge by first approximating the underlying model with a kernel machine and then leveraging techniques developed for approximating the leave-one-out (ALO) risk. Despite its strong empirical performance, the theoretical conditions under which the TRAK approximations are accurate as well as the regimes in which they break down remain largely unexplored. In this paper, we provide a theoretical analysis of the TRAK algorithm, characterizing its performance and quantifying the errors introduced by the approximations on which the method relies. We show that although the approximations incur significant errors, TRAK's estimated influence remains highly correlated with the original influence and therefore largely preserves the relative ranking of data points. We corroborate our theoretical results through extensive simulations and empirical studies.
Newfluence: Boosting Model interpretability and Understanding in High Dimensions
Jul 16, 2025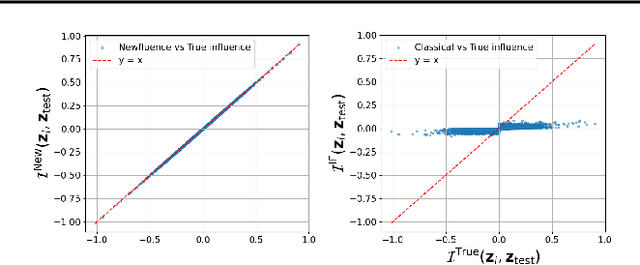


The increasing complexity of machine learning (ML) and artificial intelligence (AI) models has created a pressing need for tools that help scientists, engineers, and policymakers interpret and refine model decisions and predictions. Influence functions, originating from robust statistics, have emerged as a popular approach for this purpose. However, the heuristic foundations of influence functions rely on low-dimensional assumptions where the number of parameters $p$ is much smaller than the number of observations $n$. In contrast, modern AI models often operate in high-dimensional regimes with large $p$, challenging these assumptions. In this paper, we examine the accuracy of influence functions in high-dimensional settings. Our theoretical and empirical analyses reveal that influence functions cannot reliably fulfill their intended purpose. We then introduce an alternative approximation, called Newfluence, that maintains similar computational efficiency while offering significantly improved accuracy. Newfluence is expected to provide more accurate insights than many existing methods for interpreting complex AI models and diagnosing their issues. Moreover, the high-dimensional framework we develop in this paper can also be applied to analyze other popular techniques, such as Shapley values.
Multilook Coherent Imaging: Theoretical Guarantees and Algorithms
May 29, 2025Multilook coherent imaging is a widely used technique in applications such as digital holography, ultrasound imaging, and synthetic aperture radar. A central challenge in these systems is the presence of multiplicative noise, commonly known as speckle, which degrades image quality. Despite the widespread use of coherent imaging systems, their theoretical foundations remain relatively underexplored. In this paper, we study both the theoretical and algorithmic aspects of likelihood-based approaches for multilook coherent imaging, providing a rigorous framework for analysis and method development. Our theoretical contributions include establishing the first theoretical upper bound on the Mean Squared Error (MSE) of the maximum likelihood estimator under the deep image prior hypothesis. Our results capture the dependence of MSE on the number of parameters in the deep image prior, the number of looks, the signal dimension, and the number of measurements per look. On the algorithmic side, we employ projected gradient descent (PGD) as an efficient method for computing the maximum likelihood solution. Furthermore, we introduce two key ideas to enhance the practical performance of PGD. First, we incorporate the Newton-Schulz algorithm to compute matrix inverses within the PGD iterations, significantly reducing computational complexity. Second, we develop a bagging strategy to mitigate projection errors introduced during PGD updates. We demonstrate that combining these techniques with PGD yields state-of-the-art performance. Our code is available at https://github.com/Computational-Imaging-RU/Bagged-DIP-Speckle.
Certified Data Removal Under High-dimensional Settings
May 12, 2025



Machine unlearning focuses on the computationally efficient removal of specific training data from trained models, ensuring that the influence of forgotten data is effectively eliminated without the need for full retraining. Despite advances in low-dimensional settings, where the number of parameters \( p \) is much smaller than the sample size \( n \), extending similar theoretical guarantees to high-dimensional regimes remains challenging. We propose an unlearning algorithm that starts from the original model parameters and performs a theory-guided sequence of Newton steps \( T \in \{ 1,2\}\). After this update, carefully scaled isotropic Laplacian noise is added to the estimate to ensure that any (potential) residual influence of forget data is completely removed. We show that when both \( n, p \to \infty \) with a fixed ratio \( n/p \), significant theoretical and computational obstacles arise due to the interplay between the complexity of the model and the finite signal-to-noise ratio. Finally, we show that, unlike in low-dimensional settings, a single Newton step is insufficient for effective unlearning in high-dimensional problems -- however, two steps are enough to achieve the desired certifiebility. We provide numerical experiments to support the certifiability and accuracy claims of this approach.
Phase Transitions in Phase-Only Compressed Sensing
Jan 21, 2025The goal of phase-only compressed sensing is to recover a structured signal $\mathbf{x}$ from the phases $\mathbf{z} = {\rm sign}(\mathbf{\Phi}\mathbf{x})$ under some complex-valued sensing matrix $\mathbf{\Phi}$. Exact reconstruction of the signal's direction is possible: we can reformulate it as a linear compressed sensing problem and use basis pursuit (i.e., constrained norm minimization). For $\mathbf{\Phi}$ with i.i.d. complex-valued Gaussian entries, this paper shows that the phase transition is approximately located at the statistical dimension of the descent cone of a signal-dependent norm. Leveraging this insight, we derive asymptotically precise formulas for the phase transition locations in phase-only sensing of both sparse signals and low-rank matrices. Our results prove that the minimum number of measurements required for exact recovery is smaller for phase-only measurements than for traditional linear compressed sensing. For instance, in recovering a 1-sparse signal with sufficiently large dimension, phase-only compressed sensing requires approximately 68% of the measurements needed for linear compressed sensing. This result disproves earlier conjecture suggesting that the two phase transitions coincide. Our proof hinges on the Gaussian min-max theorem and the key observation that, up to a signal-dependent orthogonal transformation, the sensing matrix in the reformulated problem behaves as a nearly Gaussian matrix.
Comprehensive Examination of Unrolled Networks for Linear Inverse Problems
Jan 08, 2025



Unrolled networks have become prevalent in various computer vision and imaging tasks. Although they have demonstrated remarkable efficacy in solving specific computer vision and computational imaging tasks, their adaptation to other applications presents considerable challenges. This is primarily due to the multitude of design decisions that practitioners working on new applications must navigate, each potentially affecting the network's overall performance. These decisions include selecting the optimization algorithm, defining the loss function, and determining the number of convolutional layers, among others. Compounding the issue, evaluating each design choice requires time-consuming simulations to train, fine-tune the neural network, and optimize for its performance. As a result, the process of exploring multiple options and identifying the optimal configuration becomes time-consuming and computationally demanding. The main objectives of this paper are (1) to unify some ideas and methodologies used in unrolled networks to reduce the number of design choices a user has to make, and (2) to report a comprehensive ablation study to discuss the impact of each of the choices involved in designing unrolled networks and present practical recommendations based on our findings. We anticipate that this study will help scientists and engineers design unrolled networks for their applications and diagnose problems within their networks efficiently.
Is speckle noise more challenging to mitigate than additive noise?
Sep 25, 2024



We study the problem of estimating a function in the presence of both speckle and additive noises. Although additive noise has been thoroughly explored in nonparametric estimation, speckle noise, prevalent in applications such as synthetic aperture radar, ultrasound imaging, and digital holography, has not received as much attention. Consequently, there is a lack of theoretical investigations into the fundamental limits of mitigating the speckle noise. This paper is the first step in filling this gap. Our focus is on investigating the minimax estimation error for estimating a $\beta$-H\"older continuous function and determining the rate of the minimax risk. Specifically, if $n$ represents the number of data points, $f$ denotes the underlying function to be estimated, and $\hat{\nu}_n$ is an estimate of $f$, then $\inf_{\hat{\nu}_n} \sup_f \mathbb{E}_f\| \hat{\nu}_n - f \|^2_2$ decays at the rate $n^{-\frac{2\beta}{2\beta+1}}$. Interestingly, this rate is identical to the one achieved for mitigating additive noise when the noise's variance is $\Theta(1)$. To validate the accuracy of our minimax upper bounds, we implement the minimax optimal algorithms on simulated data and employ Monte Carlo simulations to characterize their exact risk. Our simulations closely mirror the expected behaviors in decay rate as per our theory.
Bagged Deep Image Prior for Recovering Images in the Presence of Speckle Noise
Feb 23, 2024



We investigate both the theoretical and algorithmic aspects of likelihood-based methods for recovering a complex-valued signal from multiple sets of measurements, referred to as looks, affected by speckle (multiplicative) noise. Our theoretical contributions include establishing the first existing theoretical upper bound on the Mean Squared Error (MSE) of the maximum likelihood estimator under the deep image prior hypothesis. Our theoretical results capture the dependence of MSE upon the number of parameters in the deep image prior, the number of looks, the signal dimension, and the number of measurements per look. On the algorithmic side, we introduce the concept of bagged Deep Image Priors (Bagged-DIP) and integrate them with projected gradient descent. Furthermore, we show how employing Newton-Schulz algorithm for calculating matrix inverses within the iterations of PGD reduces the computational complexity of the algorithm. We will show that this method achieves the state-of-the-art performance.
Theoretical Analysis of Leave-one-out Cross Validation for Non-differentiable Penalties under High-dimensional Settings
Feb 14, 2024Despite a large and significant body of recent work focused on estimating the out-of-sample risk of regularized models in the high dimensional regime, a theoretical understanding of this problem for non-differentiable penalties such as generalized LASSO and nuclear norm is missing. In this paper we resolve this challenge. We study this problem in the proportional high dimensional regime where both the sample size n and number of features p are large, and n/p and the signal-to-noise ratio (per observation) remain finite. We provide finite sample upper bounds on the expected squared error of leave-one-out cross-validation (LO) in estimating the out-of-sample risk. The theoretical framework presented here provides a solid foundation for elucidating empirical findings that show the accuracy of LO.