 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd to End Autoencoder MLP Framework for Sepsis Prediction
Aug 26, 2025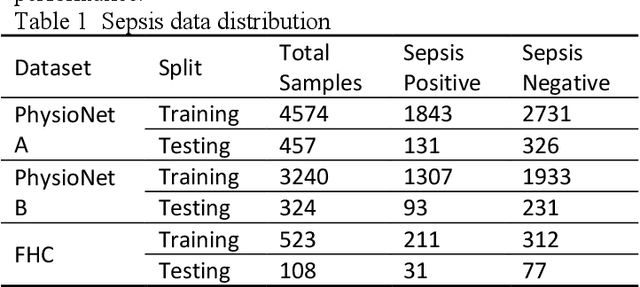
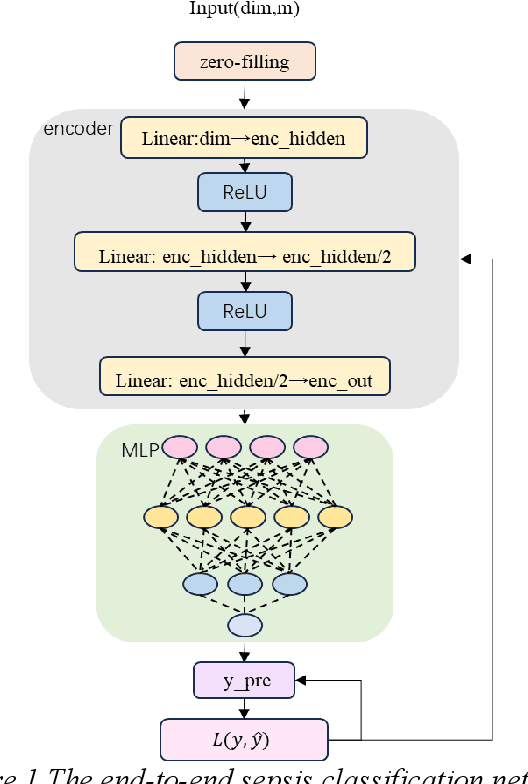
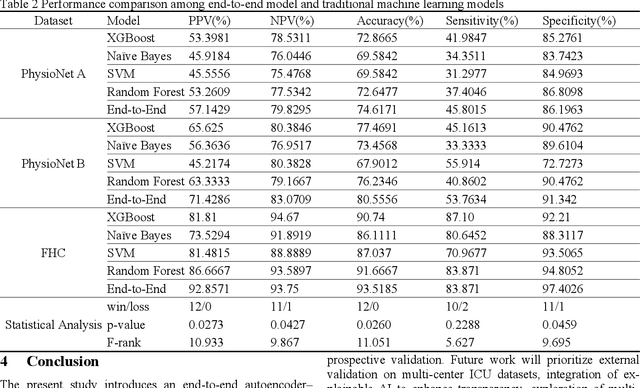
Sepsis is a life threatening condition that requires timely detection in intensive care settings. Traditional machine learning approaches, including Naive Bayes, Support Vector Machine (SVM), Random Forest, and XGBoost, often rely on manual feature engineering and struggle with irregular, incomplete time-series data commonly present in electronic health records. We introduce an end-to-end deep learning framework integrating an unsupervised autoencoder for automatic feature extraction with a multilayer perceptron classifier for binary sepsis risk prediction. To enhance clinical applicability, we implement a customized down sampling strategy that extracts high information density segments during training and a non-overlapping dynamic sliding window mechanism for real-time inference. Preprocessed time series data are represented as fixed dimension vectors with explicit missingness indicators, mitigating bias and noise. We validate our approach on three ICU cohorts. Our end-to-end model achieves accuracies of 74.6 percent, 80.6 percent, and 93.5 percent, respectively, consistently outperforming traditional machine learning baselines. These results demonstrate the framework's superior robustness, generalizability, and clinical utility for early sepsis detection across heterogeneous ICU environments.
Advancing Robust Underwater Acoustic Target Recognition through Multi-task Learning and Multi-Gate Mixture-of-Experts
Nov 05, 2024Underwater acoustic target recognition has emerged as a prominent research area within the field of underwater acoustics. However, the current availability of authentic underwater acoustic signal recordings remains limited, which hinders data-driven acoustic recognition models from learning robust patterns of targets from a limited set of intricate underwater signals, thereby compromising their stability in practical applications. To overcome these limitations, this study proposes a recognition framework called M3 (Multi-task, Multi-gate, Multi-expert) to enhance the model's ability to capture robust patterns by making it aware of the inherent properties of targets. In this framework, an auxiliary task that focuses on target properties, such as estimating target size, is designed. The auxiliary task then shares parameters with the recognition task to realize multi-task learning. This paradigm allows the model to concentrate on shared information across tasks and identify robust patterns of targets in a regularized manner, thereby enhancing the model's generalization ability. Moreover, M3 incorporates multi-expert and multi-gate mechanisms, allowing for the allocation of distinct parameter spaces to various underwater signals. This enables the model to process intricate signal patterns in a fine-grained and differentiated manner. To evaluate the effectiveness of M3, extensive experiments were implemented on the ShipsEar underwater ship-radiated noise dataset. The results substantiate that M3 has the ability to outperform the most advanced single-task recognition models, thereby achieving the state-of-the-art performance.
DEMONet: Underwater Acoustic Target Recognition based on Multi-Expert Network and Cross-Temporal Variational Autoencoder
Nov 05, 2024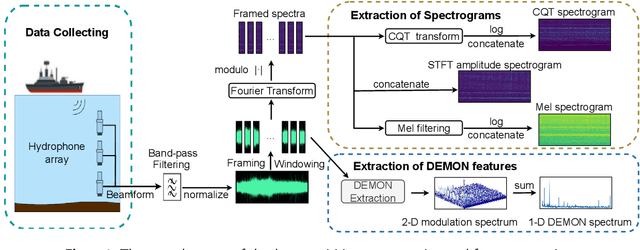
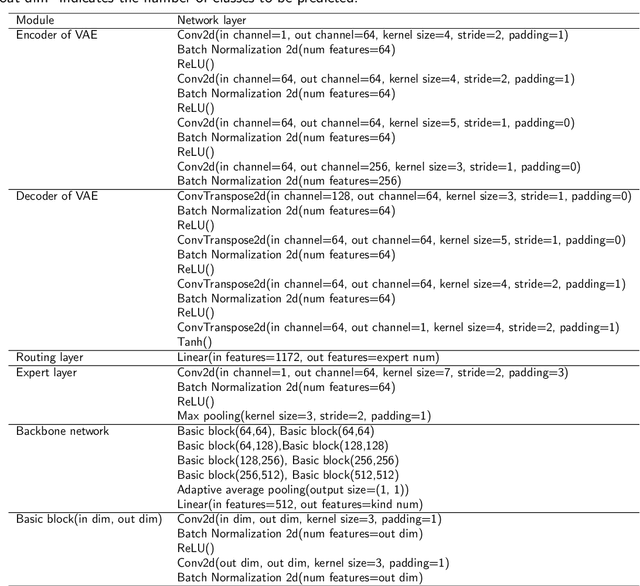
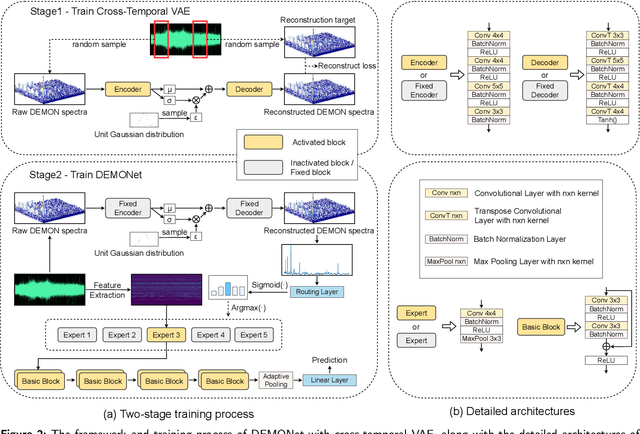

Building a robust underwater acoustic recognition system in real-world scenarios is challenging due to the complex underwater environment and the dynamic motion states of targets. A promising optimization approach is to leverage the intrinsic physical characteristics of targets, which remain invariable regardless of environmental conditions, to provide robust insights. However, our study reveals that while physical characteristics exhibit robust properties, they may lack class-specific discriminative patterns. Consequently, directly incorporating physical characteristics into model training can potentially introduce unintended inductive biases, leading to performance degradation. To utilize the benefits of physical characteristics while mitigating possible detrimental effects, we propose DEMONet in this study, which utilizes the detection of envelope modulation on noise (DEMON) to provide robust insights into the shaft frequency or blade counts of targets. DEMONet is a multi-expert network that allocates various underwater signals to their best-matched expert layer based on DEMON spectra for fine-grained signal processing. Thereinto, DEMON spectra are solely responsible for providing implicit physical characteristics without establishing a mapping relationship with the target category. Furthermore, to mitigate noise and spurious modulation spectra in DEMON features, we introduce a cross-temporal alignment strategy and employ a variational autoencoder (VAE) to reconstruct noise-resistant DEMON spectra to replace the raw DEMON features. The effectiveness of the proposed DEMONet with cross-temporal VAE was primarily evaluated on the DeepShip dataset and our proprietary datasets. Experimental results demonstrated that our approach could achieve state-of-the-art performance on both datasets.
Adversarial multi-task underwater acoustic target recognition: towards robustness against various influential factors
Nov 05, 2024



Underwater acoustic target recognition based on passive sonar faces numerous challenges in practical maritime applications. One of the main challenges lies in the susceptibility of signal characteristics to diverse environmental conditions and data acquisition configurations, which can lead to instability in recognition systems. While significant efforts have been dedicated to addressing these influential factors in other domains of underwater acoustics, they are often neglected in the field of underwater acoustic target recognition. To overcome this limitation, this study designs auxiliary tasks that model influential factors (e.g., source range, water column depth, or wind speed) based on available annotations and adopts a multi-task framework to connect these factors to the recognition task. Furthermore, we integrate an adversarial learning mechanism into the multi-task framework to prompt the model to extract representations that are robust against influential factors. Through extensive experiments and analyses on the ShipsEar dataset, our proposed adversarial multi-task model demonstrates its capacity to effectively model the influential factors and achieve state-of-the-art performance on the 12-class recognition task.
Faithful Density-Peaks Clustering via Matrix Computations on MPI Parallelization System
Jun 18, 2024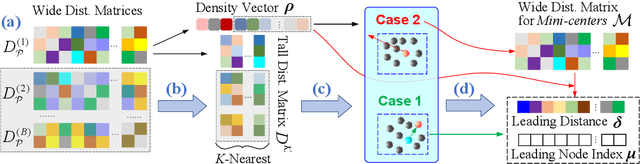



Density peaks clustering (DP) has the ability of detecting clusters of arbitrary shape and clustering non-Euclidean space data, but its quadratic complexity in both computing and storage makes it difficult to scale for big data. Various approaches have been proposed in this regard, including MapReduce based distribution computing, multi-core parallelism, presentation transformation (e.g., kd-tree, Z-value), granular computing, and so forth. However, most of these existing methods face two limitations. One is their target datasets are mostly constrained to be in Euclidian space, the other is they emphasize only on local neighbors while ignoring global data distribution due to restriction to cut-off kernel when computing density. To address the two issues, we present a faithful and parallel DP method that makes use of two types of vector-like distance matrices and an inverse leading-node-finding policy. The method is implemented on a message passing interface (MPI) system. Extensive experiments showed that our method is capable of clustering non-Euclidean data such as in community detection, while outperforming the state-of-the-art counterpart methods in accuracy when clustering large Euclidean data. Our code is publicly available at https://github.com/alanxuji/FaithPDP.
Guiding the underwater acoustic target recognition with interpretable contrastive learning
Feb 20, 2024
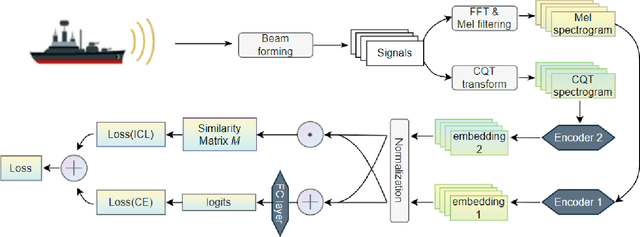


Recognizing underwater targets from acoustic signals is a challenging task owing to the intricate ocean environments and variable underwater channels. While deep learning-based systems have become the mainstream approach for underwater acoustic target recognition, they have faced criticism for their lack of interpretability and weak generalization performance in practical applications. In this work, we apply the class activation mapping (CAM) to generate visual explanations for the predictions of a spectrogram-based recognition system. CAM can help to understand the behavior of recognition models by highlighting the regions of the input features that contribute the most to the prediction. Our explorations reveal that recognition models tend to focus on the low-frequency line spectrum and high-frequency periodic modulation information of underwater signals. Based on the observation, we propose an interpretable contrastive learning (ICL) strategy that employs two encoders to learn from acoustic features with different emphases (line spectrum and modulation information). By imposing constraints between encoders, the proposed strategy can enhance the generalization performance of the recognition system. Our experiments demonstrate that the proposed contrastive learning approach can improve the recognition accuracy and bring significant improvements across various underwater databases.
Unraveling Complex Data Diversity in Underwater Acoustic Target Recognition through Convolution-based Mixture of Experts
Feb 19, 2024



Underwater acoustic target recognition is a difficult task owing to the intricate nature of underwater acoustic signals. The complex underwater environments, unpredictable transmission channels, and dynamic motion states greatly impact the real-world underwater acoustic signals, and may even obscure the intrinsic characteristics related to targets. Consequently, the data distribution of underwater acoustic signals exhibits high intra-class diversity, thereby compromising the accuracy and robustness of recognition systems.To address these issues, this work proposes a convolution-based mixture of experts (CMoE) that recognizes underwater targets in a fine-grained manner. The proposed technique introduces multiple expert layers as independent learners, along with a routing layer that determines the assignment of experts according to the characteristics of inputs. This design allows the model to utilize independent parameter spaces, facilitating the learning of complex underwater signals with high intra-class diversity. Furthermore, this work optimizes the CMoE structure by balancing regularization and an optional residual module. To validate the efficacy of our proposed techniques, we conducted detailed experiments and visualization analyses on three underwater acoustic databases across several acoustic features. The experimental results demonstrate that our CMoE consistently achieves significant performance improvements, delivering superior recognition accuracy when compared to existing advanced methods.
Long-Tailed Classification Based on Coarse-Grained Leading Forest and Multi-Center Loss
Oct 12, 2023Long-tailed(LT) classification is an unavoidable and challenging problem in the real world. Most of the existing long-tailed classification methods focus only on solving the inter-class imbalance in which there are more samples in the head class than in the tail class, while ignoring the intra-lass imbalance in which the number of samples of the head attribute within the same class is much larger than the number of samples of the tail attribute. The deviation in the model is caused by both of these factors, and due to the fact that attributes are implicit in most datasets and the combination of attributes is very complex, the intra-class imbalance is more difficult to handle. For this purpose, we proposed a long-tailed classification framework, known as \textbf{\textsc{Cognisance}}, which is founded on Coarse-Grained Leading Forest (CLF) and Multi-Center Loss (MCL), aiming to build a multi-granularity joint solution model by means of invariant feature learning. In this method, we designed an unsupervised learning method, i.e., CLF, to better characterize the distribution of attributes within a class. Depending on the distribution of attributes, we can flexibly construct sampling strategies suitable for different environments. In addition, we introduce a new metric learning loss (MCL), which aims to gradually eliminate confusing attributes during the feature learning process. More importantly, this approach does not depend on a specific model structure and can be integrated with existing LT methods as an independent component. We have conducted extensive experiments and our approach has state-of-the-art performance in both existing benchmarks ImageNet-GLT and MSCOCO-GLT, and can improve the performance of existing LT methods. Our codes are available on GitHub: \url{https://github.com/jinyery/cognisance}
Underwater Acoustic Target Recognition based on Smoothness-inducing Regularization and Spectrogram-based Data Augmentation
Jun 12, 2023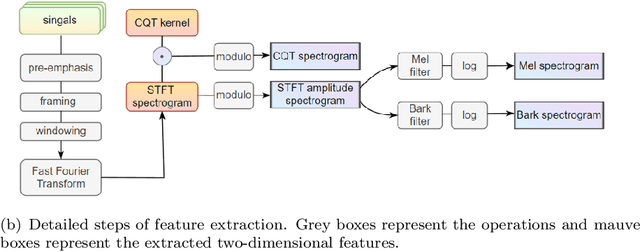
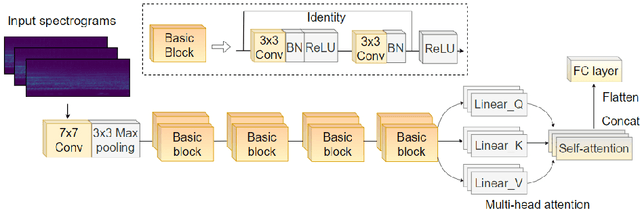

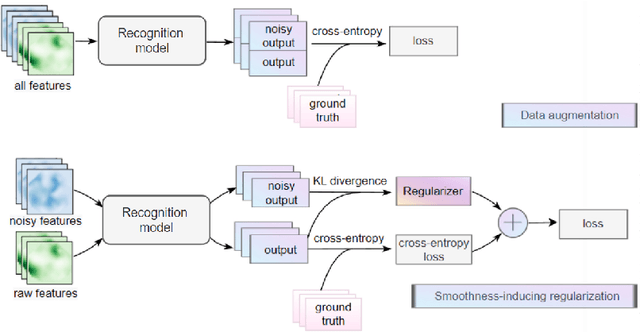
Underwater acoustic target recognition is a challenging task owing to the intricate underwater environments and limited data availability. Insufficient data can hinder the ability of recognition systems to support complex modeling, thus impeding their advancement. To improve the generalization capacity of recognition models, techniques such as data augmentation have been employed to simulate underwater signals and diversify data distribution. However, the complexity of underwater environments can cause the simulated signals to deviate from real scenarios, resulting in biased models that are misguided by non-true data. In this study, we propose two strategies to enhance the generalization ability of models in the case of limited data while avoiding the risk of performance degradation. First, as an alternative to traditional data augmentation, we utilize smoothness-inducing regularization, which only incorporates simulated signals in the regularization term. Additionally, we propose a specialized spectrogram-based data augmentation strategy, namely local masking and replicating (LMR), to capture inter-class relationships. Our experiments and visualization analysis demonstrate the superiority of our proposed strategies.
Underwater-Art: Expanding Information Perspectives With Text Templates For Underwater Acoustic Target Recognition
May 31, 2023



Underwater acoustic target recognition is an intractable task due to the complex acoustic source characteristics and sound propagation patterns. Limited by insufficient data and narrow information perspective, recognition models based on deep learning seem far from satisfactory in practical underwater scenarios. Although underwater acoustic signals are severely influenced by distance, channel depth, or other factors, annotations of relevant information are often non-uniform, incomplete, and hard to use. In our work, we propose to implement Underwater Acoustic Recognition based on Templates made up of rich relevant information (hereinafter called "UART"). We design templates to integrate relevant information from different perspectives into descriptive natural language. UART adopts an audio-spectrogram-text tri-modal contrastive learning framework, which endows UART with the ability to guide the learning of acoustic representations by descriptive natural language. Our experiments reveal that UART has better recognition capability and generalization performance than traditional paradigms. Furthermore, the pre-trained UART model could provide superior prior knowledge for the recognition model in the scenario without any auxiliary annotation.