 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Service Operations via LLM-Powered Multi-Agent Simulation
Apr 06, 2026Service system performance depends on how participants respond to design choices, but modeling these responses is hard due to the complexity of human behavior. We introduce an LLM-powered multi-agent simulation (LLM-MAS) framework for optimizing service operations. We pose the problem as stochastic optimization with decision-dependent uncertainty: design choices are embedded in prompts and shape the distribution of outcomes from interacting LLM-powered agents. By embedding key numerical information in prompts and extracting it from LLM-generated text, we model this uncertainty as a controlled Markov chain. We develop an on-trajectory learning algorithm that, on a single simulation run, simultaneously constructs zeroth-order gradient estimates and updates design parameters to optimize steady-state performance. We also incorporate variance reduction techniques. In a sustainable supply chain application, our method outperforms benchmarks, including blackbox optimization and using LLMs as numerical solvers or as role-playing system designers. A case study on optimal contest design with real behavioral data shows that LLM-MAS is both as a cost-effective evaluator of known designs and an exploratory tool that can uncover strong designs overlooked by traditional approaches.
Uncertainty-Adjusted Sorting for Asset Pricing with Machine Learning
Jan 02, 2026Machine learning is central to empirical asset pricing, but portfolio construction still relies on point predictions and largely ignores asset-specific estimation uncertainty. We propose a simple change: sort assets using uncertainty-adjusted prediction bounds instead of point predictions alone. Across a broad set of ML models and a U.S. equity panel, this approach improves portfolio performance relative to point-prediction sorting. These gains persist even when bounds are built from partial or misspecified uncertainty information. They arise mainly from reduced volatility and are strongest for flexible machine learning models. Identification and robustness exercises show that these improvements are driven by asset-level rather than time or aggregate predictive uncertainty.
A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
Jul 02, 2025The remarkable advancements of vision and language foundation models in multimodal understanding, reasoning, and generation has sparked growing efforts to extend such intelligence to the physical world, fueling the flourishing of vision-language-action (VLA) models. Despite seemingly diverse approaches, we observe that current VLA models can be unified under a single framework: vision and language inputs are processed by a series of VLA modules, producing a chain of \textit{action tokens} that progressively encode more grounded and actionable information, ultimately generating executable actions. We further determine that the primary design choice distinguishing VLA models lies in how action tokens are formulated, which can be categorized into language description, code, affordance, trajectory, goal state, latent representation, raw action, and reasoning. However, there remains a lack of comprehensive understanding regarding action tokens, significantly impeding effective VLA development and obscuring future directions. Therefore, this survey aims to categorize and interpret existing VLA research through the lens of action tokenization, distill the strengths and limitations of each token type, and identify areas for improvement. Through this systematic review and analysis, we offer a synthesized outlook on the broader evolution of VLA models, highlight underexplored yet promising directions, and contribute guidance for future research, hoping to bring the field closer to general-purpose intelligence.
Statistical Inference for Weighted Sample Average Approximation in Contextual Stochastic Optimization
Mar 17, 2025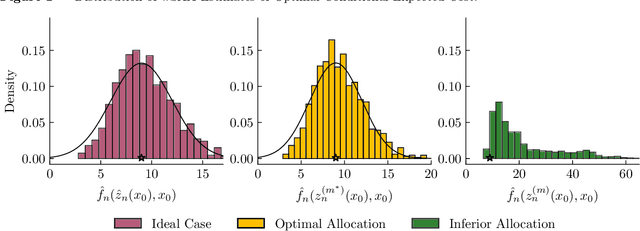

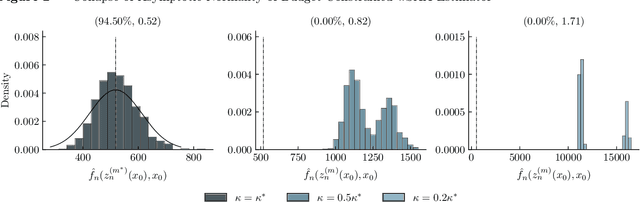
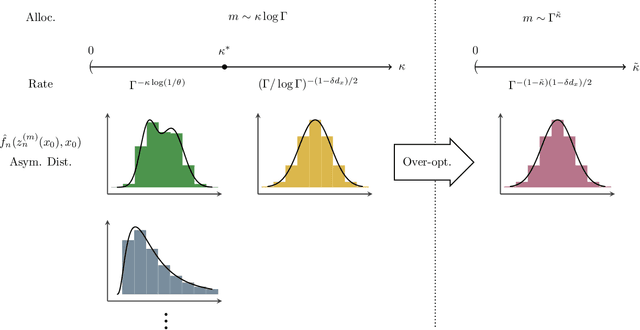
Contextual stochastic optimization provides a framework for decision-making under uncertainty incorporating observable contextual information through covariates. We analyze statistical inference for weighted sample average approximation (wSAA), a widely-used method for solving contextual stochastic optimization problems. We first establish central limit theorems for wSAA estimates of optimal values when problems can be solved exactly, characterizing how estimation uncertainty scales with covariate sample size. We then investigate practical scenarios with computational budget constraints, revealing a fundamental tradeoff between statistical accuracy and computational cost as sample sizes increase. Through central limit theorems for budget-constrained wSAA estimates, we precisely characterize this statistical-computational tradeoff. We also develop "over-optimizing" strategies for solving wSAA problems that ensure valid statistical inference. Extensive numerical experiments on both synthetic and real-world datasets validate our theoretical findings.
Adaptive Moment Estimation Optimization Algorithm Using Projection Gradient for Deep Learning
Mar 13, 2025Training deep neural networks is challenging. To accelerate training and enhance performance, we propose PadamP, a novel optimization algorithm. PadamP is derived by applying the adaptive estimation of the p-th power of the second-order moments under scale invariance, enhancing projection adaptability by modifying the projection discrimination condition. It is integrated into Adam-type algorithms, accelerating training, boosting performance, and improving generalization in deep learning. Combining projected gradient benefits with adaptive moment estimation, PadamP tackles unconstrained non-convex problems. Convergence for the non-convex case is analyzed, focusing on the decoupling of first-order moment estimation coefficients and second-order moment estimation coefficients. Unlike prior work relying on , our proof generalizes the convergence theorem, enhancing practicality. Experiments using VGG-16 and ResNet-18 on CIFAR-10 and CIFAR-100 show PadamP's effectiveness, with notable performance on CIFAR-10/100, especially for VGG-16. The results demonstrate that PadamP outperforms existing algorithms in terms of convergence speed and generalization ability, making it a valuable addition to the field of deep learning optimization.
Diffusion-based Hierarchical Negative Sampling for Multimodal Knowledge Graph Completion
Jan 26, 2025Multimodal Knowledge Graph Completion (MMKGC) aims to address the critical issue of missing knowledge in multimodal knowledge graphs (MMKGs) for their better applications. However, both the previous MMGKC and negative sampling (NS) approaches ignore the employment of multimodal information to generate diverse and high-quality negative triples from various semantic levels and hardness levels, thereby limiting the effectiveness of training MMKGC models. Thus, we propose a novel Diffusion-based Hierarchical Negative Sampling (DHNS) scheme tailored for MMKGC tasks, which tackles the challenge of generating high-quality negative triples by leveraging a Diffusion-based Hierarchical Embedding Generation (DiffHEG) that progressively conditions on entities and relations as well as multimodal semantics. Furthermore, we develop a Negative Triple-Adaptive Training (NTAT) strategy that dynamically adjusts training margins associated with the hardness level of the synthesized negative triples, facilitating a more robust and effective learning procedure to distinguish between positive and negative triples. Extensive experiments on three MMKGC benchmark datasets demonstrate that our framework outperforms several state-of-the-art MMKGC models and negative sampling techniques, illustrating the effectiveness of our DHNS for training MMKGC models. The source codes and datasets of this paper are available at https://github.com/ngl567/DHNS.
DEMONet: Underwater Acoustic Target Recognition based on Multi-Expert Network and Cross-Temporal Variational Autoencoder
Nov 05, 2024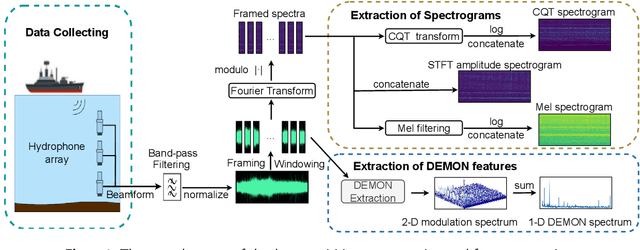
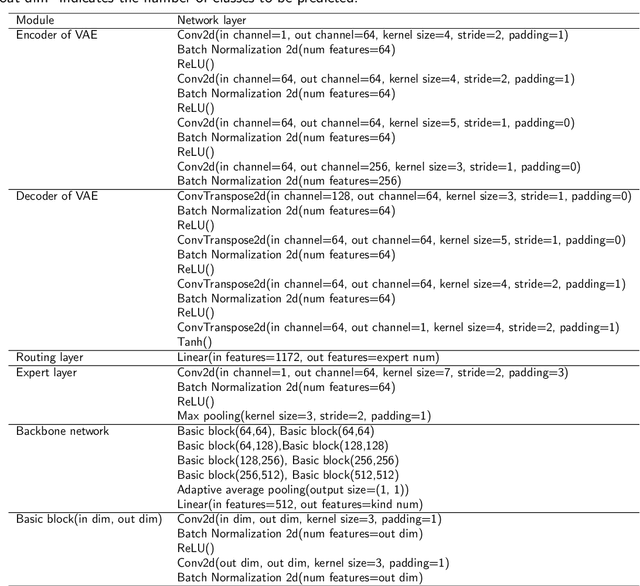
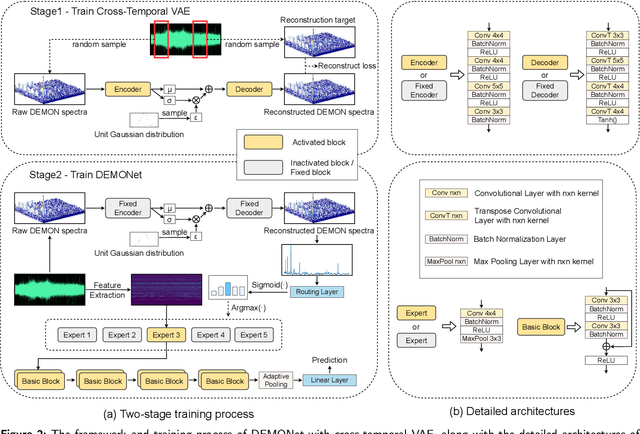

Building a robust underwater acoustic recognition system in real-world scenarios is challenging due to the complex underwater environment and the dynamic motion states of targets. A promising optimization approach is to leverage the intrinsic physical characteristics of targets, which remain invariable regardless of environmental conditions, to provide robust insights. However, our study reveals that while physical characteristics exhibit robust properties, they may lack class-specific discriminative patterns. Consequently, directly incorporating physical characteristics into model training can potentially introduce unintended inductive biases, leading to performance degradation. To utilize the benefits of physical characteristics while mitigating possible detrimental effects, we propose DEMONet in this study, which utilizes the detection of envelope modulation on noise (DEMON) to provide robust insights into the shaft frequency or blade counts of targets. DEMONet is a multi-expert network that allocates various underwater signals to their best-matched expert layer based on DEMON spectra for fine-grained signal processing. Thereinto, DEMON spectra are solely responsible for providing implicit physical characteristics without establishing a mapping relationship with the target category. Furthermore, to mitigate noise and spurious modulation spectra in DEMON features, we introduce a cross-temporal alignment strategy and employ a variational autoencoder (VAE) to reconstruct noise-resistant DEMON spectra to replace the raw DEMON features. The effectiveness of the proposed DEMONet with cross-temporal VAE was primarily evaluated on the DeepShip dataset and our proprietary datasets. Experimental results demonstrated that our approach could achieve state-of-the-art performance on both datasets.
Conjugate-Gradient-like Based Adaptive Moment Estimation Optimization Algorithm for Deep Learning
Apr 02, 2024Training deep neural networks is a challenging task. In order to speed up training and enhance the performance of deep neural networks, we rectify the vanilla conjugate gradient as conjugate-gradient-like and incorporate it into the generic Adam, and thus propose a new optimization algorithm named CG-like-Adam for deep learning. Specifically, both the first-order and the second-order moment estimation of generic Adam are replaced by the conjugate-gradient-like. Convergence analysis handles the cases where the exponential moving average coefficient of the first-order moment estimation is constant and the first-order moment estimation is unbiased. Numerical experiments show the superiority of the proposed algorithm based on the CIFAR10/100 dataset.
Helmsman of the Masses? Evaluate the Opinion Leadership of Large Language Models in the Werewolf Game
Apr 02, 2024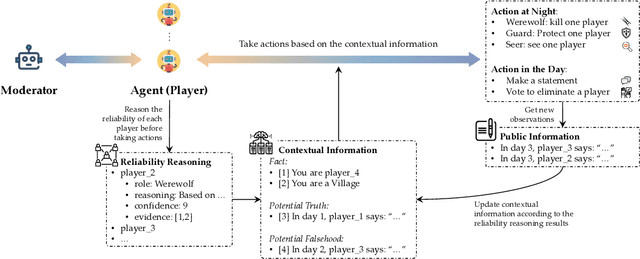
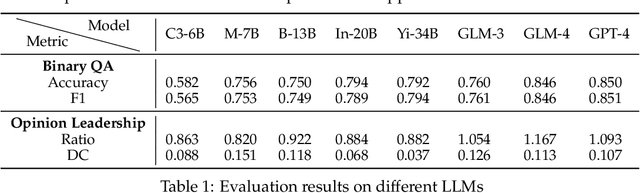

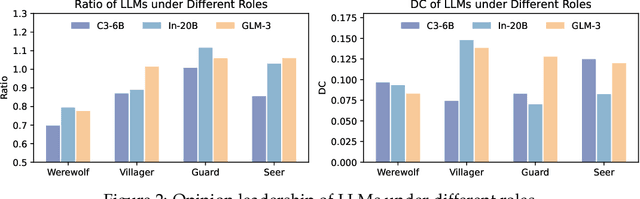
Large language models (LLMs) have exhibited memorable strategic behaviors in social deductive games. However, the significance of opinion leadership exhibited by LLM-based agents has been overlooked, which is crucial for practical applications in multi-agent and human-AI interaction settings. Opinion leaders are individuals who have a noticeable impact on the beliefs and behaviors of others within a social group. In this work, we employ the Werewolf game as a simulation platform to assess the opinion leadership of LLMs. The game features the role of the Sheriff, tasked with summarizing arguments and recommending decision options, and therefore serves as a credible proxy for an opinion leader. We develop a framework integrating the Sheriff role and devise two novel metrics for evaluation based on the critical characteristics of opinion leaders. The first metric measures the reliability of the opinion leader, and the second assesses the influence of the opinion leader on other players' decisions. We conduct extensive experiments to evaluate LLMs of different scales. In addition, we collect a Werewolf question-answering dataset (WWQA) to assess and enhance LLM's grasp of the game rules, and we also incorporate human participants for further analysis. The results suggest that the Werewolf game is a suitable test bed to evaluate the opinion leadership of LLMs and few LLMs possess the capacity for opinion leadership.
CPCL: Cross-Modal Prototypical Contrastive Learning for Weakly Supervised Text-based Person Re-Identification
Jan 18, 2024Weakly supervised text-based person re-identification (TPRe-ID) seeks to retrieve images of a target person using textual descriptions, without relying on identity annotations and is more challenging and practical. The primary challenge is the intra-class differences, encompassing intra-modal feature variations and cross-modal semantic gaps. Prior works have focused on instance-level samples and ignored prototypical features of each person which are intrinsic and invariant. Toward this, we propose a Cross-Modal Prototypical Contrastive Learning (CPCL) method. In practice, the CPCL introduces the CLIP model to weakly supervised TPRe-ID for the first time, mapping visual and textual instances into a shared latent space. Subsequently, the proposed Prototypical Multi-modal Memory (PMM) module captures associations between heterogeneous modalities of image-text pairs belonging to the same person through the Hybrid Cross-modal Matching (HCM) module in a many-to-many mapping fashion. Moreover, the Outlier Pseudo Label Mining (OPLM) module further distinguishes valuable outlier samples from each modality, enhancing the creation of more reliable clusters by mining implicit relationships between image-text pairs. Experimental results demonstrate that our proposed CPCL attains state-of-the-art performance on all three public datasets, with a significant improvement of 11.58%, 8.77% and 5.25% in Rank@1 accuracy on CUHK-PEDES, ICFG-PEDES and RSTPReid datasets, respectively. The code is available at https://github.com/codeGallery24/CPCL.