 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartSnap: Proactive Evidence Seeking for Self-Verifying Agents
Dec 26, 2025Agentic reinforcement learning (RL) holds great promise for the development of autonomous agents under complex GUI tasks, but its scalability remains severely hampered by the verification of task completion. Existing task verification is treated as a passive, post-hoc process: a verifier (i.e., rule-based scoring script, reward or critic model, and LLM-as-a-Judge) analyzes the agent's entire interaction trajectory to determine if the agent succeeds. Such processing of verbose context that contains irrelevant, noisy history poses challenges to the verification protocols and therefore leads to prohibitive cost and low reliability. To overcome this bottleneck, we propose SmartSnap, a paradigm shift from this passive, post-hoc verification to proactive, in-situ self-verification by the agent itself. We introduce the Self-Verifying Agent, a new type of agent designed with dual missions: to not only complete a task but also to prove its accomplishment with curated snapshot evidences. Guided by our proposed 3C Principles (Completeness, Conciseness, and Creativity), the agent leverages its accessibility to the online environment to perform self-verification on a minimal, decisive set of snapshots. Such evidences are provided as the sole materials for a general LLM-as-a-Judge verifier to determine their validity and relevance. Experiments on mobile tasks across model families and scales demonstrate that our SmartSnap paradigm allows training LLM-driven agents in a scalable manner, bringing performance gains up to 26.08% and 16.66% respectively to 8B and 30B models. The synergizing between solution finding and evidence seeking facilitates the cultivation of efficient, self-verifying agents with competitive performance against DeepSeek V3.1 and Qwen3-235B-A22B.
Learn the Ropes, Then Trust the Wins: Self-imitation with Progressive Exploration for Agentic Reinforcement Learning
Sep 26, 2025
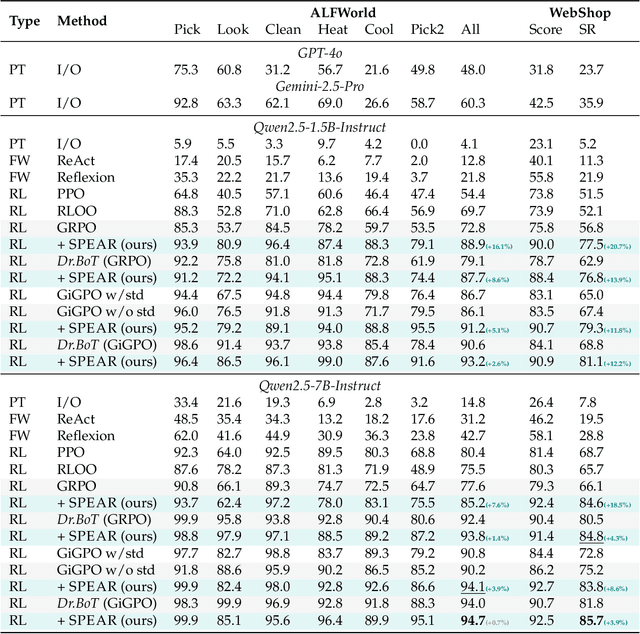
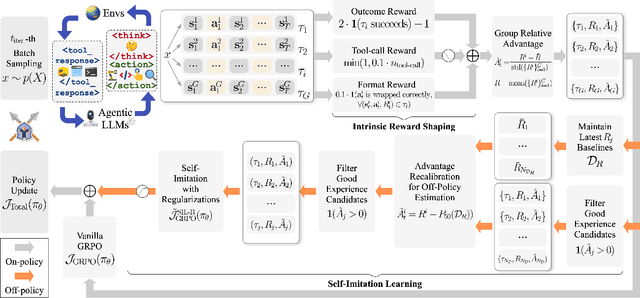
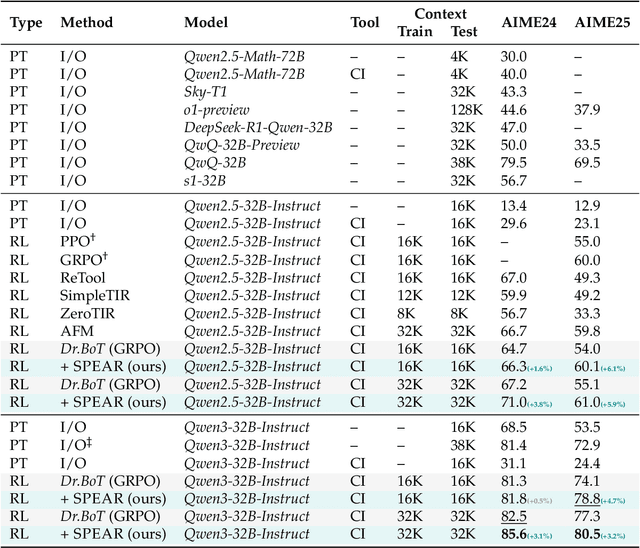
Reinforcement learning (RL) is the dominant paradigm for sharpening strategic tool use capabilities of LLMs on long-horizon, sparsely-rewarded agent tasks, yet it faces a fundamental challenge of exploration-exploitation trade-off. Existing studies stimulate exploration through the lens of policy entropy, but such mechanical entropy maximization is prone to RL training instability due to the multi-turn distribution shifting. In this paper, we target the progressive exploration-exploitation balance under the guidance of the agent own experiences without succumbing to either entropy collapsing or runaway divergence. We propose SPEAR, a curriculum-based self-imitation learning (SIL) recipe for training agentic LLMs. It extends the vanilla SIL framework, where a replay buffer stores self-generated promising trajectories for off-policy update, by gradually steering the policy evolution within a well-balanced range of entropy across stages. Specifically, our approach incorporates a curriculum to manage the exploration process, utilizing intrinsic rewards to foster skill-level exploration and facilitating action-level exploration through SIL. At first, the auxiliary tool call reward plays a critical role in the accumulation of tool-use skills, enabling broad exposure to the unfamiliar distributions of the environment feedback with an upward entropy trend. As training progresses, self-imitation gets strengthened to exploit existing successful patterns from replayed experiences for comparative action-level exploration, accelerating solution iteration without unbounded entropy growth. To further stabilize training, we recalibrate the advantages of experiences in the replay buffer to address the potential policy drift. Reugularizations such as the clipping of tokens with high covariance between probability and advantage are introduced to the trajectory-level entropy control to curb over-confidence.
Scalable Multi-Task Reinforcement Learning for Generalizable Spatial Intelligence in Visuomotor Agents
Jul 31, 2025While Reinforcement Learning (RL) has achieved remarkable success in language modeling, its triumph hasn't yet fully translated to visuomotor agents. A primary challenge in RL models is their tendency to overfit specific tasks or environments, thereby hindering the acquisition of generalizable behaviors across diverse settings. This paper provides a preliminary answer to this challenge by demonstrating that RL-finetuned visuomotor agents in Minecraft can achieve zero-shot generalization to unseen worlds. Specifically, we explore RL's potential to enhance generalizable spatial reasoning and interaction capabilities in 3D worlds. To address challenges in multi-task RL representation, we analyze and establish cross-view goal specification as a unified multi-task goal space for visuomotor policies. Furthermore, to overcome the significant bottleneck of manual task design, we propose automated task synthesis within the highly customizable Minecraft environment for large-scale multi-task RL training, and we construct an efficient distributed RL framework to support this. Experimental results show RL significantly boosts interaction success rates by $4\times$ and enables zero-shot generalization of spatial reasoning across diverse environments, including real-world settings. Our findings underscore the immense potential of RL training in 3D simulated environments, especially those amenable to large-scale task generation, for significantly advancing visuomotor agents' spatial reasoning.
A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
Jul 02, 2025The remarkable advancements of vision and language foundation models in multimodal understanding, reasoning, and generation has sparked growing efforts to extend such intelligence to the physical world, fueling the flourishing of vision-language-action (VLA) models. Despite seemingly diverse approaches, we observe that current VLA models can be unified under a single framework: vision and language inputs are processed by a series of VLA modules, producing a chain of \textit{action tokens} that progressively encode more grounded and actionable information, ultimately generating executable actions. We further determine that the primary design choice distinguishing VLA models lies in how action tokens are formulated, which can be categorized into language description, code, affordance, trajectory, goal state, latent representation, raw action, and reasoning. However, there remains a lack of comprehensive understanding regarding action tokens, significantly impeding effective VLA development and obscuring future directions. Therefore, this survey aims to categorize and interpret existing VLA research through the lens of action tokenization, distill the strengths and limitations of each token type, and identify areas for improvement. Through this systematic review and analysis, we offer a synthesized outlook on the broader evolution of VLA models, highlight underexplored yet promising directions, and contribute guidance for future research, hoping to bring the field closer to general-purpose intelligence.
Toward Memory-Aided World Models: Benchmarking via Spatial Consistency
May 29, 2025The ability to simulate the world in a spatially consistent manner is a crucial requirements for effective world models. Such a model enables high-quality visual generation, and also ensures the reliability of world models for downstream tasks such as simulation and planning. Designing a memory module is a crucial component for addressing spatial consistency: such a model must not only retain long-horizon observational information, but also enables the construction of explicit or implicit internal spatial representations. However, there are no dataset designed to promote the development of memory modules by explicitly enforcing spatial consistency constraints. Furthermore, most existing benchmarks primarily emphasize visual coherence or generation quality, neglecting the requirement of long-range spatial consistency. To bridge this gap, we construct a dataset and corresponding benchmark by sampling 150 distinct locations within the open-world environment of Minecraft, collecting about 250 hours (20 million frames) of loop-based navigation videos with actions. Our dataset follows a curriculum design of sequence lengths, allowing models to learn spatial consistency on increasingly complex navigation trajectories. Furthermore, our data collection pipeline is easily extensible to new Minecraft environments and modules. Four representative world model baselines are evaluated on our benchmark. Dataset, benchmark, and code are open-sourced to support future research.
ROCKET-2: Steering Visuomotor Policy via Cross-View Goal Alignment
Mar 04, 2025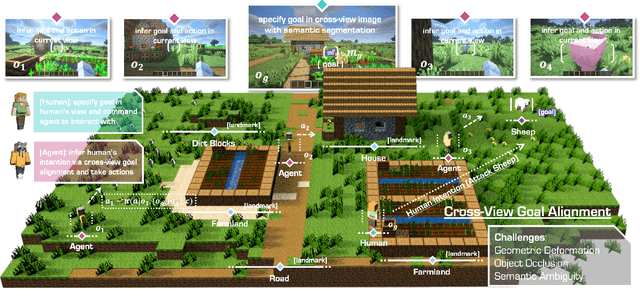
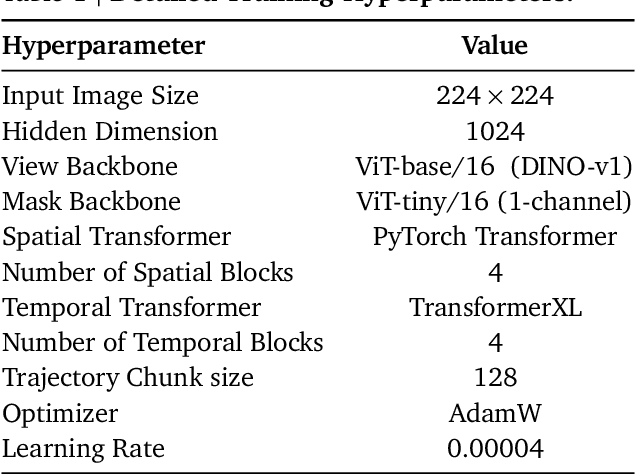
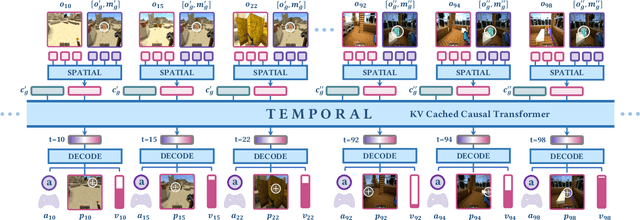

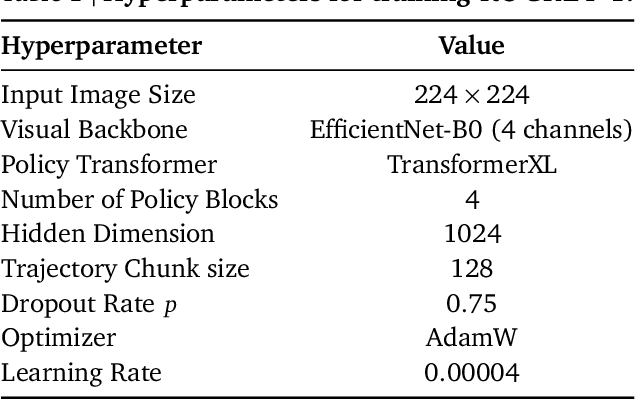
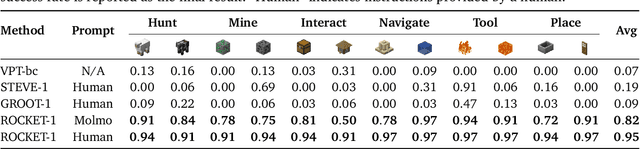
We aim to develop a goal specification method that is semantically clear, spatially sensitive, and intuitive for human users to guide agent interactions in embodied environments. Specifically, we propose a novel cross-view goal alignment framework that allows users to specify target objects using segmentation masks from their own camera views rather than the agent's observations. We highlight that behavior cloning alone fails to align the agent's behavior with human intent when the human and agent camera views differ significantly. To address this, we introduce two auxiliary objectives: cross-view consistency loss and target visibility loss, which explicitly enhance the agent's spatial reasoning ability. According to this, we develop ROCKET-2, a state-of-the-art agent trained in Minecraft, achieving an improvement in the efficiency of inference 3x to 6x. We show ROCKET-2 can directly interpret goals from human camera views for the first time, paving the way for better human-agent interaction.
MineStudio: A Streamlined Package for Minecraft AI Agent Development
Dec 25, 2024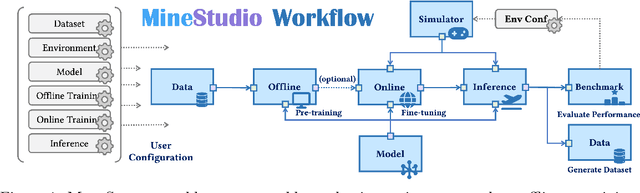
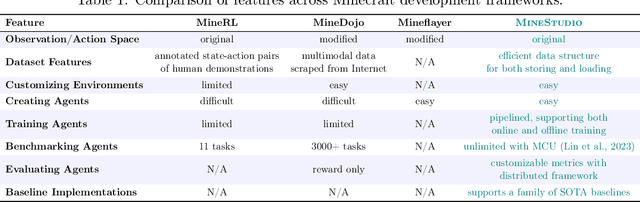
Minecraft has emerged as a valuable testbed for embodied intelligence and sequential decision-making research, yet the development and validation of novel agents remains hindered by significant engineering challenges. This paper presents MineStudio, an open-source software package designed to streamline embodied policy development in Minecraft. MineStudio represents the first comprehensive integration of seven critical engineering components: simulator, data, model, offline pretraining, online finetuning, inference, and benchmark, thereby allowing users to concentrate their efforts on algorithm innovation. We provide a user-friendly API design accompanied by comprehensive documentation and tutorials. The complete codebase is publicly available at https://github.com/CraftJarvis/MineStudio.
MinsStudio: A Streamlined Package for Minecraft AI Agent Development
Dec 24, 2024Minecraft has emerged as a valuable testbed for embodied intelligence and sequential decision-making research, yet the development and validation of novel agents remains hindered by significant engineering challenges. This paper presents MineStudio, an open-source software package designed to streamline embodied policy development in Minecraft. MineStudio represents the first comprehensive integration of seven critical engineering components: simulator, data, model, offline pretraining, online finetuning, inference, and benchmark, thereby allowing users to concentrate their efforts on algorithm innovation. We provide a user-friendly API design accompanied by comprehensive documentation and tutorials. The complete codebase is publicly available at https://github.com/CraftJarvis/MineStudio.
Optimizing Latent Goal by Learning from Trajectory Preference
Dec 03, 2024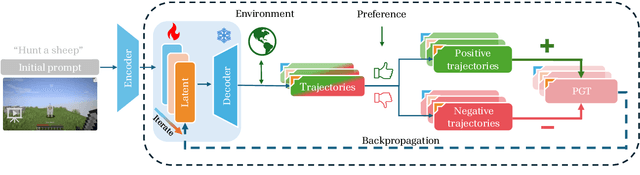
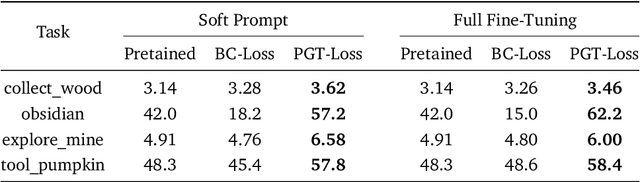
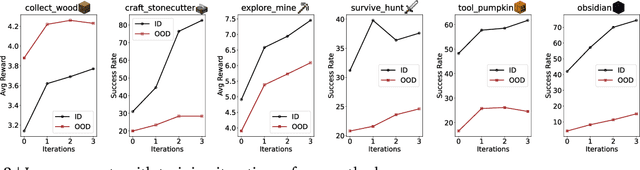
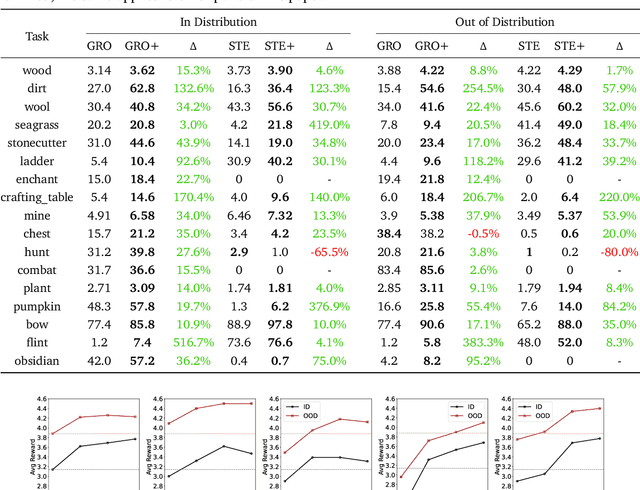
A glowing body of work has emerged focusing on instruction-following policies for open-world agents, aiming to better align the agent's behavior with human intentions. However, the performance of these policies is highly susceptible to the initial prompt, which leads to extra efforts in selecting the best instructions. We propose a framework named Preference Goal Tuning (PGT). PGT allows an instruction following policy to interact with the environment to collect several trajectories, which will be categorized into positive and negative samples based on preference. Then we use preference learning to fine-tune the initial goal latent representation with the categorized trajectories while keeping the policy backbone frozen. The experiment result shows that with minimal data and training, PGT achieves an average relative improvement of 72.0% and 81.6% over 17 tasks in 2 different foundation policies respectively, and outperforms the best human-selected instructions. Moreover, PGT surpasses full fine-tuning in the out-of-distribution (OOD) task-execution environments by 13.4%, indicating that our approach retains strong generalization capabilities. Since our approach stores a single latent representation for each task independently, it can be viewed as an efficient method for continual learning, without the risk of catastrophic forgetting or task interference. In short, PGT enhances the performance of agents across nearly all tasks in the Minecraft Skillforge benchmark and demonstrates robustness to the execution environment.
ROCKET-1: Master Open-World Interaction with Visual-Temporal Context Prompting
Oct 23, 2024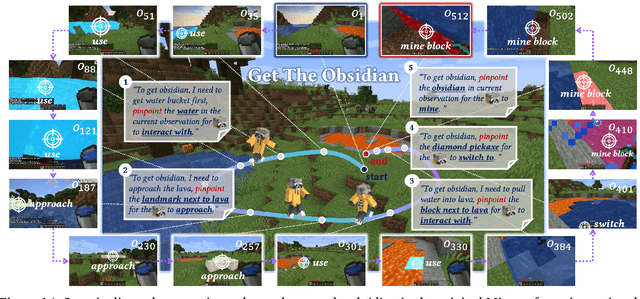
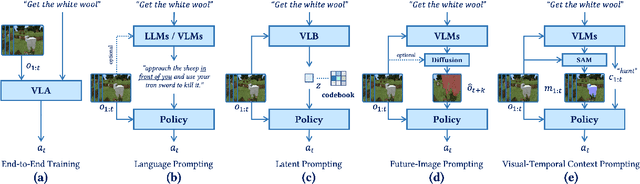
Vision-language models (VLMs) have excelled in multimodal tasks, but adapting them to embodied decision-making in open-world environments presents challenges. A key issue is the difficulty in smoothly connecting individual entities in low-level observations with abstract concepts required for planning. A common approach to address this problem is through the use of hierarchical agents, where VLMs serve as high-level reasoners that break down tasks into executable sub-tasks, typically specified using language and imagined observations. However, language often fails to effectively convey spatial information, while generating future images with sufficient accuracy remains challenging. To address these limitations, we propose visual-temporal context prompting, a novel communication protocol between VLMs and policy models. This protocol leverages object segmentation from both past and present observations to guide policy-environment interactions. Using this approach, we train ROCKET-1, a low-level policy that predicts actions based on concatenated visual observations and segmentation masks, with real-time object tracking provided by SAM-2. Our method unlocks the full potential of VLMs visual-language reasoning abilities, enabling them to solve complex creative tasks, especially those heavily reliant on spatial understanding. Experiments in Minecraft demonstrate that our approach allows agents to accomplish previously unattainable tasks, highlighting the effectiveness of visual-temporal context prompting in embodied decision-making. Codes and demos will be available on the project page: https://craftjarvis.github.io/ROCKET-1.