 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep (Predictive) Discounted Counterfactual Regret Minimization
Nov 11, 2025Counterfactual regret minimization (CFR) is a family of algorithms for effectively solving imperfect-information games. To enhance CFR's applicability in large games, researchers use neural networks to approximate its behavior. However, existing methods are mainly based on vanilla CFR and struggle to effectively integrate more advanced CFR variants. In this work, we propose an efficient model-free neural CFR algorithm, overcoming the limitations of existing methods in approximating advanced CFR variants. At each iteration, it collects variance-reduced sampled advantages based on a value network, fits cumulative advantages by bootstrapping, and applies discounting and clipping operations to simulate the update mechanisms of advanced CFR variants. Experimental results show that, compared with model-free neural algorithms, it exhibits faster convergence in typical imperfect-information games and demonstrates stronger adversarial performance in a large poker game.
Goal-Oriented Skill Abstraction for Offline Multi-Task Reinforcement Learning
Jul 09, 2025Offline multi-task reinforcement learning aims to learn a unified policy capable of solving multiple tasks using only pre-collected task-mixed datasets, without requiring any online interaction with the environment. However, it faces significant challenges in effectively sharing knowledge across tasks. Inspired by the efficient knowledge abstraction observed in human learning, we propose Goal-Oriented Skill Abstraction (GO-Skill), a novel approach designed to extract and utilize reusable skills to enhance knowledge transfer and task performance. Our approach uncovers reusable skills through a goal-oriented skill extraction process and leverages vector quantization to construct a discrete skill library. To mitigate class imbalances between broadly applicable and task-specific skills, we introduce a skill enhancement phase to refine the extracted skills. Furthermore, we integrate these skills using hierarchical policy learning, enabling the construction of a high-level policy that dynamically orchestrates discrete skills to accomplish specific tasks. Extensive experiments on diverse robotic manipulation tasks within the MetaWorld benchmark demonstrate the effectiveness and versatility of GO-Skill.
* ICML2025
Optimizing Latent Goal by Learning from Trajectory Preference
Dec 03, 2024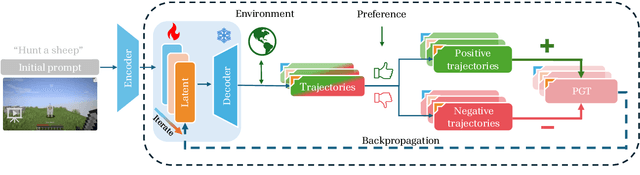
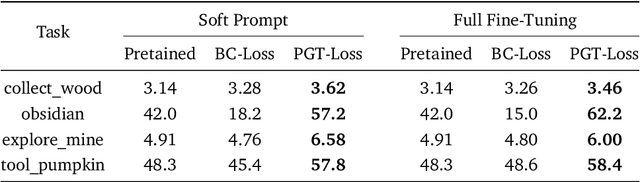
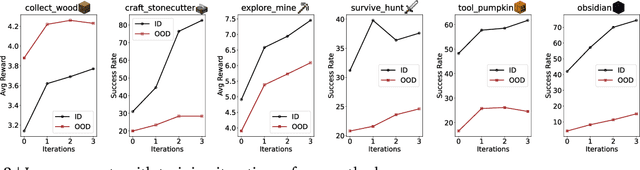
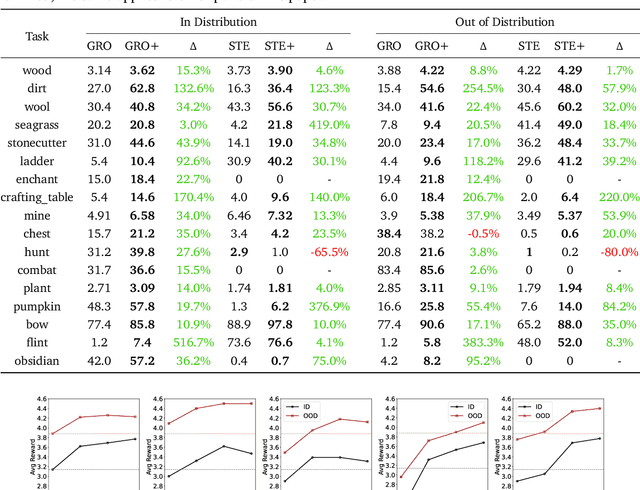
A glowing body of work has emerged focusing on instruction-following policies for open-world agents, aiming to better align the agent's behavior with human intentions. However, the performance of these policies is highly susceptible to the initial prompt, which leads to extra efforts in selecting the best instructions. We propose a framework named Preference Goal Tuning (PGT). PGT allows an instruction following policy to interact with the environment to collect several trajectories, which will be categorized into positive and negative samples based on preference. Then we use preference learning to fine-tune the initial goal latent representation with the categorized trajectories while keeping the policy backbone frozen. The experiment result shows that with minimal data and training, PGT achieves an average relative improvement of 72.0% and 81.6% over 17 tasks in 2 different foundation policies respectively, and outperforms the best human-selected instructions. Moreover, PGT surpasses full fine-tuning in the out-of-distribution (OOD) task-execution environments by 13.4%, indicating that our approach retains strong generalization capabilities. Since our approach stores a single latent representation for each task independently, it can be viewed as an efficient method for continual learning, without the risk of catastrophic forgetting or task interference. In short, PGT enhances the performance of agents across nearly all tasks in the Minecraft Skillforge benchmark and demonstrates robustness to the execution environment.
Diverse Policies Recovering via Pointwise Mutual Information Weighted Imitation Learning
Oct 21, 2024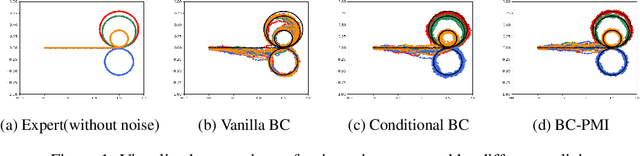
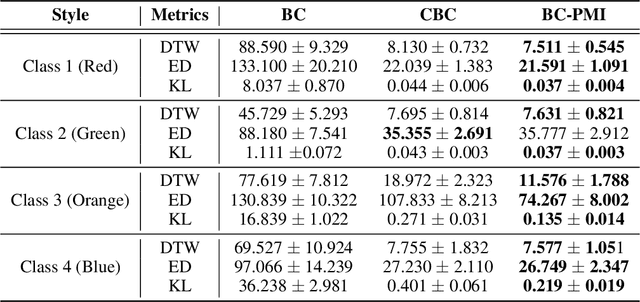
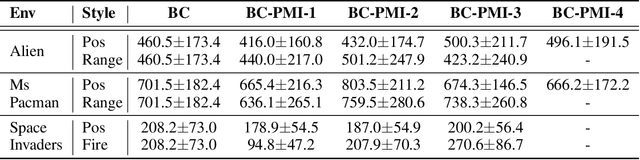
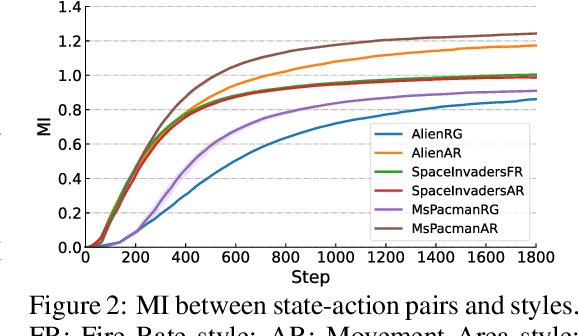
Recovering a spectrum of diverse policies from a set of expert trajectories is an important research topic in imitation learning. After determining a latent style for a trajectory, previous diverse policies recovering methods usually employ a vanilla behavioral cloning learning objective conditioned on the latent style, treating each state-action pair in the trajectory with equal importance. Based on an observation that in many scenarios, behavioral styles are often highly relevant with only a subset of state-action pairs, this paper presents a new principled method in diverse polices recovery. In particular, after inferring or assigning a latent style for a trajectory, we enhance the vanilla behavioral cloning by incorporating a weighting mechanism based on pointwise mutual information. This additional weighting reflects the significance of each state-action pair's contribution to learning the style, thus allowing our method to focus on state-action pairs most representative of that style. We provide theoretical justifications for our new objective, and extensive empirical evaluations confirm the effectiveness of our method in recovering diverse policies from expert data.
Minimizing Weighted Counterfactual Regret with Optimistic Online Mirror Descent
Apr 22, 2024Counterfactual regret minimization (CFR) is a family of algorithms for effectively solving imperfect-information games. It decomposes the total regret into counterfactual regrets, utilizing local regret minimization algorithms, such as Regret Matching (RM) or RM+, to minimize them. Recent research establishes a connection between Online Mirror Descent (OMD) and RM+, paving the way for an optimistic variant PRM+ and its extension PCFR+. However, PCFR+ assigns uniform weights for each iteration when determining regrets, leading to substantial regrets when facing dominated actions. This work explores minimizing weighted counterfactual regret with optimistic OMD, resulting in a novel CFR variant PDCFR+. It integrates PCFR+ and Discounted CFR (DCFR) in a principled manner, swiftly mitigating negative effects of dominated actions and consistently leveraging predictions to accelerate convergence. Theoretical analyses prove that PDCFR+ converges to a Nash equilibrium, particularly under distinct weighting schemes for regrets and average strategies. Experimental results demonstrate PDCFR+'s fast convergence in common imperfect-information games. The code is available at https://github.com/rpSebastian/PDCFRPlus.
Reaching Consensus in Cooperative Multi-Agent Reinforcement Learning with Goal Imagination
Mar 05, 2024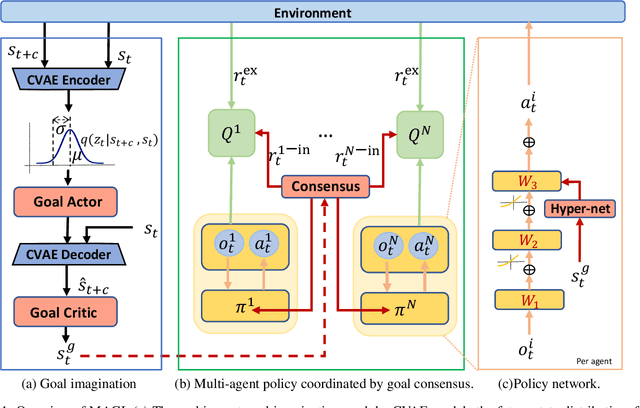
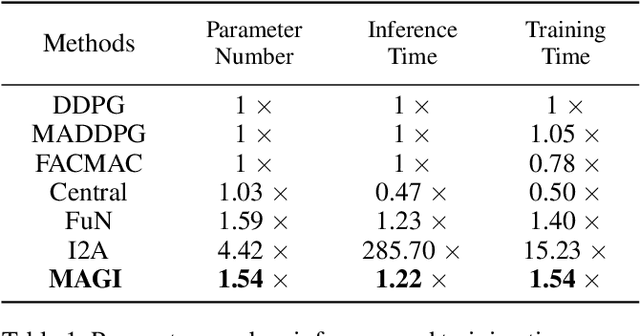
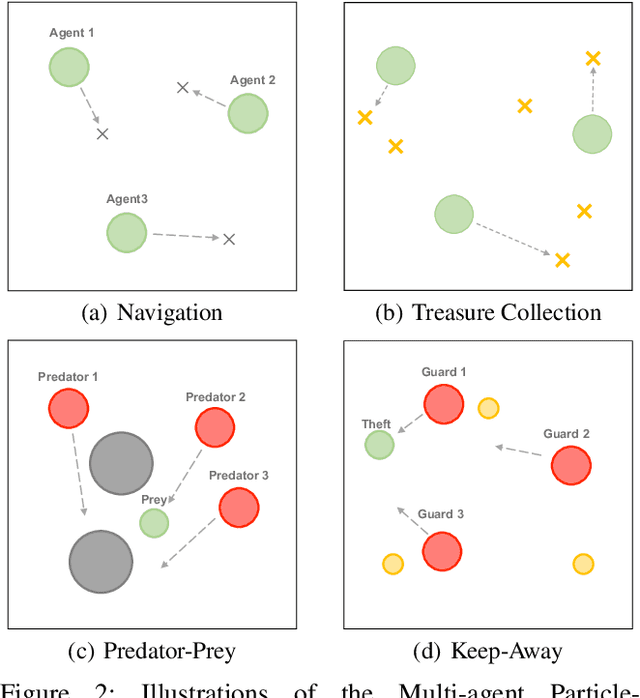

Reaching consensus is key to multi-agent coordination. To accomplish a cooperative task, agents need to coherently select optimal joint actions to maximize the team reward. However, current cooperative multi-agent reinforcement learning (MARL) methods usually do not explicitly take consensus into consideration, which may cause miscoordination problem. In this paper, we propose a model-based consensus mechanism to explicitly coordinate multiple agents. The proposed Multi-agent Goal Imagination (MAGI) framework guides agents to reach consensus with an Imagined common goal. The common goal is an achievable state with high value, which is obtained by sampling from the distribution of future states. We directly model this distribution with a self-supervised generative model, thus alleviating the "curse of dimensinality" problem induced by multi-agent multi-step policy rollout commonly used in model-based methods. We show that such efficient consensus mechanism can guide all agents cooperatively reaching valuable future states. Results on Multi-agent Particle-Environments and Google Research Football environment demonstrate the superiority of MAGI in both sample efficiency and performance.
Enhance Reasoning for Large Language Models in the Game Werewolf
Feb 04, 2024This paper presents an innovative framework that integrates Large Language Models (LLMs) with an external Thinker module to enhance the reasoning capabilities of LLM-based agents. Unlike augmenting LLMs with prompt engineering, Thinker directly harnesses knowledge from databases and employs various optimization techniques. The framework forms a reasoning hierarchy where LLMs handle intuitive System-1 tasks such as natural language processing, while the Thinker focuses on cognitive System-2 tasks that require complex logical analysis and domain-specific knowledge. Our framework is presented using a 9-player Werewolf game that demands dual-system reasoning. We introduce a communication protocol between LLMs and the Thinker, and train the Thinker using data from 18800 human sessions and reinforcement learning. Experiments demonstrate the framework's effectiveness in deductive reasoning, speech generation, and online game evaluation. Additionally, we fine-tune a 6B LLM to surpass GPT4 when integrated with the Thinker. This paper also contributes the largest dataset for social deduction games to date.
Not All Tasks Are Equally Difficult: Multi-Task Reinforcement Learning with Dynamic Depth Routing
Dec 22, 2023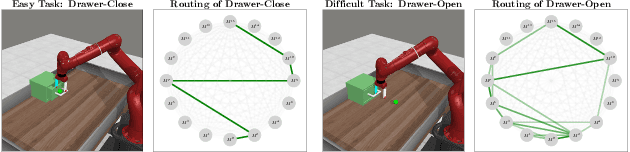

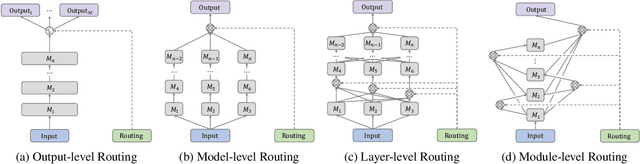

Multi-task reinforcement learning endeavors to accomplish a set of different tasks with a single policy. To enhance data efficiency by sharing parameters across multiple tasks, a common practice segments the network into distinct modules and trains a routing network to recombine these modules into task-specific policies. However, existing routing approaches employ a fixed number of modules for all tasks, neglecting that tasks with varying difficulties commonly require varying amounts of knowledge. This work presents a Dynamic Depth Routing (D2R) framework, which learns strategic skipping of certain intermediate modules, thereby flexibly choosing different numbers of modules for each task. Under this framework, we further introduce a ResRouting method to address the issue of disparate routing paths between behavior and target policies during off-policy training. In addition, we design an automatic route-balancing mechanism to encourage continued routing exploration for unmastered tasks without disturbing the routing of mastered ones. We conduct extensive experiments on various robotics manipulation tasks in the Meta-World benchmark, where D2R achieves state-of-the-art performance with significantly improved learning efficiency.
* AAAI2024, with supplementary material
Pointer Networks Trained Better via Evolutionary Algorithms
Dec 06, 2023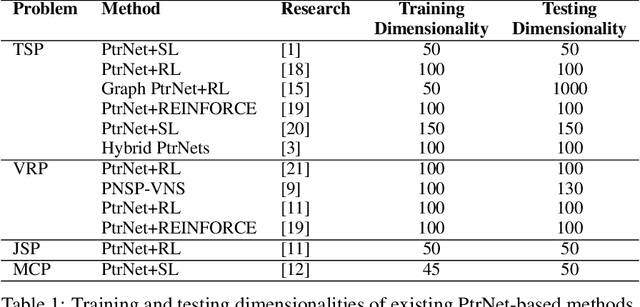



Pointer Network (PtrNet) is a specific neural network for solving Combinatorial Optimization Problems (COPs). While PtrNets offer real-time feed-forward inference for complex COPs instances, its quality of the results tends to be less satisfactory. One possible reason is that such issue suffers from the lack of global search ability of the gradient descent, which is frequently employed in traditional PtrNet training methods including both supervised learning and reinforcement learning. To improve the performance of PtrNet, this paper delves deeply into the advantages of training PtrNet with Evolutionary Algorithms (EAs), which have been widely acknowledged for not easily getting trapped by local optima. Extensive empirical studies based on the Travelling Salesman Problem (TSP) have been conducted. Results demonstrate that PtrNet trained with EA can consistently perform much better inference results than eight state-of-the-art methods on various problem scales. Compared with gradient descent based PtrNet training methods, EA achieves up to 30.21\% improvement in quality of the solution with the same computational time. With this advantage, this paper is able to at the first time report the results of solving 1000-dimensional TSPs by training a PtrNet on the same dimensionality, which strongly suggests that scaling up the training instances is in need to improve the performance of PtrNet on solving higher-dimensional COPs.
Diversity from Human Feedback
Oct 10, 2023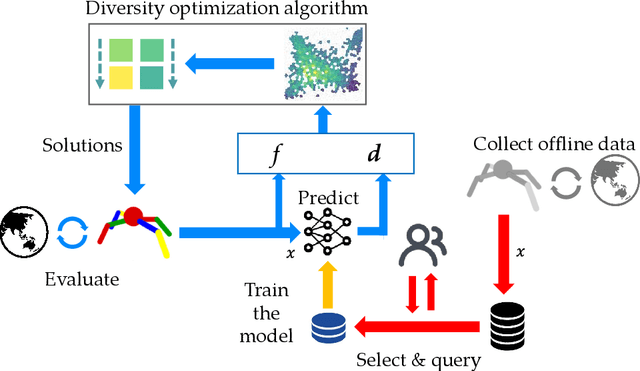
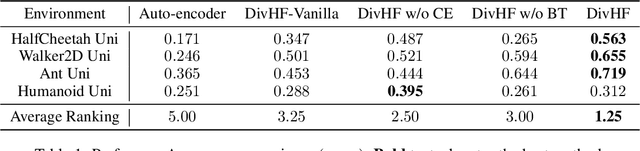
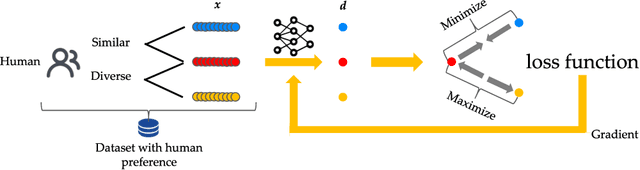
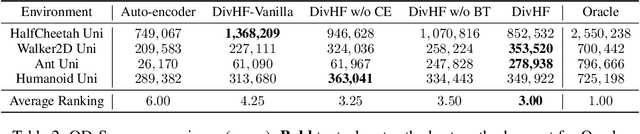
Diversity plays a significant role in many problems, such as ensemble learning, reinforcement learning, and combinatorial optimization. How to define the diversity measure is a longstanding problem. Many methods rely on expert experience to define a proper behavior space and then obtain the diversity measure, which is, however, challenging in many scenarios. In this paper, we propose the problem of learning a behavior space from human feedback and present a general method called Diversity from Human Feedback (DivHF) to solve it. DivHF learns a behavior descriptor consistent with human preference by querying human feedback. The learned behavior descriptor can be combined with any distance measure to define a diversity measure. We demonstrate the effectiveness of DivHF by integrating it with the Quality-Diversity optimization algorithm MAP-Elites and conducting experiments on the QDax suite. The results show that DivHF learns a behavior space that aligns better with human requirements compared to direct data-driven approaches and leads to more diverse solutions under human preference. Our contributions include formulating the problem, proposing the DivHF method, and demonstrating its effectiveness through experiments.