 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Current Agents Close the Discovery-to-Application Gap? A Case Study in Minecraft
Apr 27, 2026Discovering causal regularities and applying them to build functional systems--the discovery-to-application loop--is a hallmark of general intelligence, yet evaluating this capacity has been hindered by the vast complexity gap between scientific discovery and real-world engineering. We introduce SciCrafter, a Minecraft-based benchmark that operationalizes this loop through parameterized redstone circuit tasks. Agents must ignite lamps in specified patterns (e.g., simultaneously or in timed sequences); scaling target parameters substantially increases construction complexity and required knowledge, forcing genuine discovery rather than reliance on memorized solutions. Evaluating frontier models including GPT-5.2, Gemini-3-Pro, and Claude-Opus-4.5 under a general-purpose code agent scaffold, we find that all plateau at approximately 26% success rate. To diagnose these failures, we decompose the loop into four capacities--knowledge gap identification, experimental discovery, knowledge consolidation, and knowledge application--and design targeted interventions whose marginal contributions serve as proxies for corresponding gaps. Our analysis reveals that although the general knowledge application capability still remains as the biggest gap across all models, for frontier models the knowledge gap identification starts to become a major hurdle--indicating the bottleneck is shifting from solving problems right to raising the right problems for current AI. We release SciCrafter as a diagnostic probe for future research on AI systems that navigate the full discovery-to-application loop.
Spend Less, Fit Better: Budget-Efficient Scaling Law Fitting via Active Experiment Selection
Apr 24, 2026Scaling laws are used to plan multi-million-dollar training runs, but fitting those laws can itself cost millions. In modern large-scale workflows, assembling a sufficiently informative set of pilot experiments is already a major budget-allocation problem rather than a routine preprocessing step. We formulate scaling-law fitting as budget-aware sequential experimental design: given a finite pool of runnable experiments with heterogeneous costs, choose which runs to execute so as to maximize extrapolation accuracy in a high-cost target region. We then propose an uncertainty-aware method for sequentially allocating experimental budget toward the runs most useful for target-region extrapolation. Across a diverse benchmark of scaling-law tasks, our method consistently outperforms classical design-based baselines, and often approaches the performance of fitting on the full experimental set while using only about 10% of the total training budget. Our code is available at https://github.com/PlanarG/active-sl.
Evaluation-driven Scaling for Scientific Discovery
Apr 21, 2026Language models are increasingly used in scientific discovery to generate hypotheses, propose candidate solutions, implement systems, and iteratively refine them. At the core of these trial-and-error loops lies evaluation: the process of obtaining feedback on candidate solutions via verifiers, simulators, or task-specific scoring functions. While prior work has highlighted the importance of evaluation, it has not explicitly formulated the problem of how evaluation-driven discovery loops can be scaled up in a principled and effective manner to push the boundaries of scientific discovery, a problem this paper seeks to address. We introduce Simple Test-time Evaluation-driven Scaling (SimpleTES), a general framework that strategically combines parallel exploration, feedback-driven refinement, and local selection, revealing substantial gains unlocked by scaling evaluation-driven discovery loops along the right dimensions. Across 21 scientific problems spanning six domains, SimpleTES discovers state-of-the-art solutions using gpt-oss models, consistently outperforming both frontier-model baselines and sophisticated optimization pipelines. Particularly, we sped up the widely used LASSO algorithm by over 2x, designed quantum circuit routing policies that reduce gate overhead by 24.5%, and discovered new Erdos minimum overlap constructions that surpass the best-known results. Beyond novel discoveries, SimpleTES produces trajectory-level histories that naturally supervise feedback-driven learning. When post-trained on successful trajectories, models not only improve efficiency on seen problems but also generalize to unseen problems, discovering solutions that base models fail to uncover. Together, our results establish effective evaluation-driven loop scaling as a central axis for advancing LLM-driven scientific discovery, and provide a simple yet practical framework for realizing these gains.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Peptide2Mol: A Diffusion Model for Generating Small Molecules as Peptide Mimics for Targeted Protein Binding
Nov 07, 2025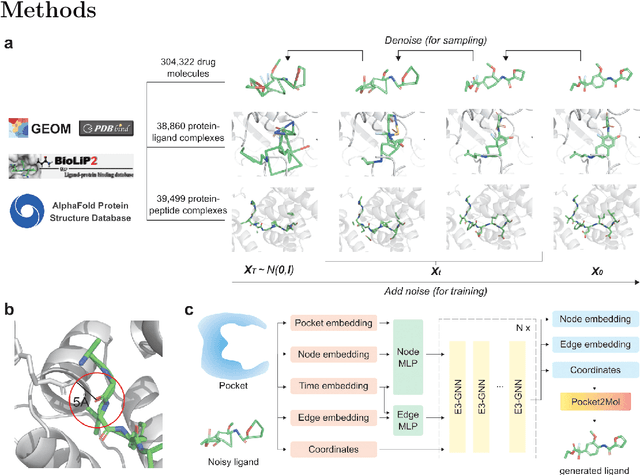
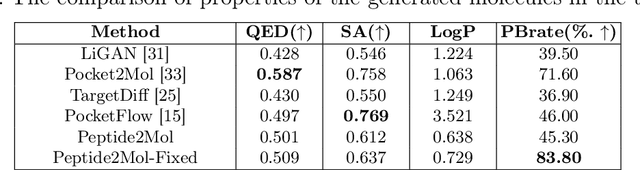
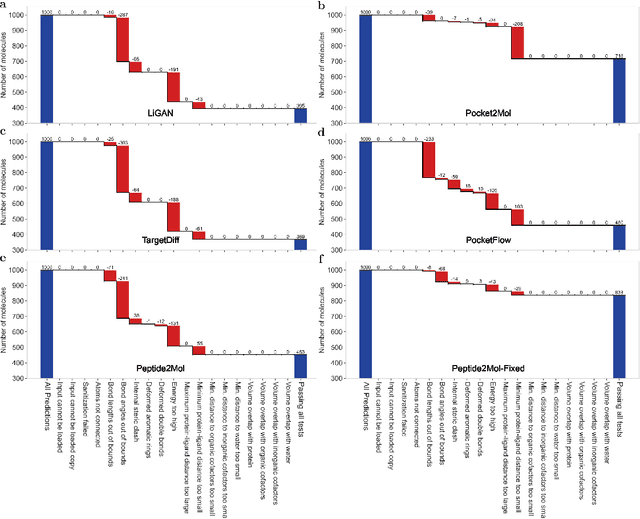
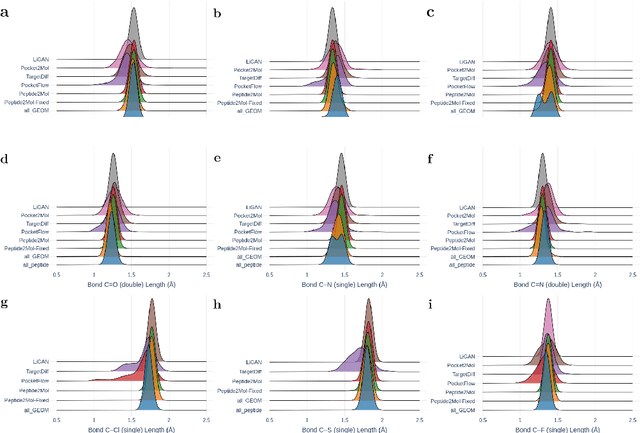
Structure-based drug design has seen significant advancements with the integration of artificial intelligence (AI), particularly in the generation of hit and lead compounds. However, most AI-driven approaches neglect the importance of endogenous protein interactions with peptides, which may result in suboptimal molecule designs. In this work, we present Peptide2Mol, an E(3)-equivariant graph neural network diffusion model that generates small molecules by referencing both the original peptide binders and their surrounding protein pocket environments. Trained on large datasets and leveraging sophisticated modeling techniques, Peptide2Mol not only achieves state-of-the-art performance in non-autoregressive generative tasks, but also produces molecules with similarity to the original peptide binder. Additionally, the model allows for molecule optimization and peptidomimetic design through a partial diffusion process. Our results highlight Peptide2Mol as an effective deep generative model for generating and optimizing bioactive small molecules from protein binding pockets.
Inference-time Scaling of Diffusion Models through Classical Search
May 29, 2025Classical search algorithms have long underpinned modern artificial intelligence. In this work, we tackle the challenge of inference-time control in diffusion models -- adapting generated outputs to meet diverse test-time objectives -- using principles from classical search. We propose a general framework that orchestrates local and global search to efficiently navigate the generative space. It employs a theoretically grounded local search via annealed Langevin MCMC and performs compute-efficient global exploration using breadth-first and depth-first tree search. We evaluate our approach on a range of challenging domains, including planning, offline reinforcement learning, and image generation. Across all tasks, we observe significant gains in both performance and efficiency. These results show that classical search provides a principled and practical foundation for inference-time scaling in diffusion models. Project page at diffusion-inference-scaling.github.io.
Efficient and Asymptotically Unbiased Constrained Decoding for Large Language Models
Apr 12, 2025In real-world applications of large language models, outputs are often required to be confined: selecting items from predefined product or document sets, generating phrases that comply with safety standards, or conforming to specialized formatting styles. To control the generation, constrained decoding has been widely adopted. However, existing prefix-tree-based constrained decoding is inefficient under GPU-based model inference paradigms, and it introduces unintended biases into the output distribution. This paper introduces Dynamic Importance Sampling for Constrained Decoding (DISC) with GPU-based Parallel Prefix-Verification (PPV), a novel algorithm that leverages dynamic importance sampling to achieve theoretically guaranteed asymptotic unbiasedness and overcomes the inefficiency of prefix-tree. Extensive experiments demonstrate the superiority of our method over existing methods in both efficiency and output quality. These results highlight the potential of our methods to improve constrained generation in applications where adherence to specific constraints is essential.
Generative Evaluation of Complex Reasoning in Large Language Models
Apr 03, 2025
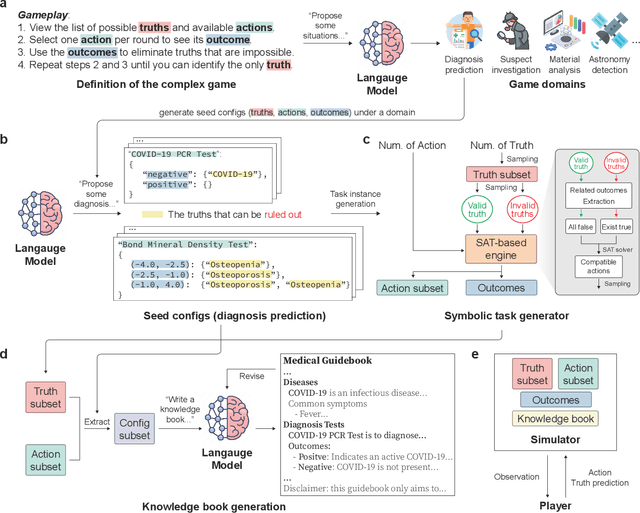
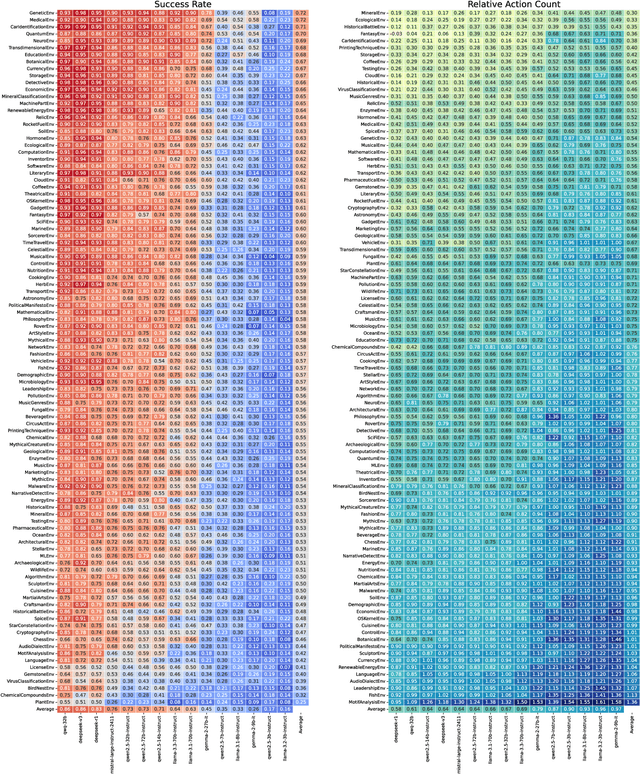
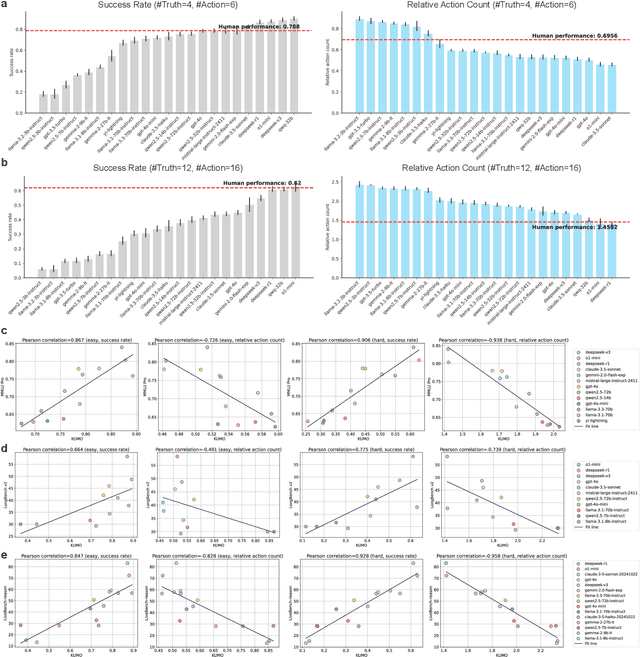
With powerful large language models (LLMs) demonstrating superhuman reasoning capabilities, a critical question arises: Do LLMs genuinely reason, or do they merely recall answers from their extensive, web-scraped training datasets? Publicly released benchmarks inevitably become contaminated once incorporated into subsequent LLM training sets, undermining their reliability as faithful assessments. To address this, we introduce KUMO, a generative evaluation framework designed specifically for assessing reasoning in LLMs. KUMO synergistically combines LLMs with symbolic engines to dynamically produce diverse, multi-turn reasoning tasks that are partially observable and adjustable in difficulty. Through an automated pipeline, KUMO continuously generates novel tasks across open-ended domains, compelling models to demonstrate genuine generalization rather than memorization. We evaluated 23 state-of-the-art LLMs on 5,000 tasks across 100 domains created by KUMO, benchmarking their reasoning abilities against university students. Our findings reveal that many LLMs have outperformed university-level performance on easy reasoning tasks, and reasoning-scaled LLMs reach university-level performance on complex reasoning challenges. Moreover, LLM performance on KUMO tasks correlates strongly with results on newly released real-world reasoning benchmarks, underscoring KUMO's value as a robust, enduring assessment tool for genuine LLM reasoning capabilities.
Uni-3DAR: Unified 3D Generation and Understanding via Autoregression on Compressed Spatial Tokens
Mar 21, 2025Recent advancements in large language models and their multi-modal extensions have demonstrated the effectiveness of unifying generation and understanding through autoregressive next-token prediction. However, despite the critical role of 3D structural generation and understanding (3D GU) in AI for science, these tasks have largely evolved independently, with autoregressive methods remaining underexplored. To bridge this gap, we introduce Uni-3DAR, a unified framework that seamlessly integrates 3D GU tasks via autoregressive prediction. At its core, Uni-3DAR employs a novel hierarchical tokenization that compresses 3D space using an octree, leveraging the inherent sparsity of 3D structures. It then applies an additional tokenization for fine-grained structural details, capturing key attributes such as atom types and precise spatial coordinates in microscopic 3D structures. We further propose two optimizations to enhance efficiency and effectiveness. The first is a two-level subtree compression strategy, which reduces the octree token sequence by up to 8x. The second is a masked next-token prediction mechanism tailored for dynamically varying token positions, significantly boosting model performance. By combining these strategies, Uni-3DAR successfully unifies diverse 3D GU tasks within a single autoregressive framework. Extensive experiments across multiple microscopic 3D GU tasks, including molecules, proteins, polymers, and crystals, validate its effectiveness and versatility. Notably, Uni-3DAR surpasses previous state-of-the-art diffusion models by a substantial margin, achieving up to 256\% relative improvement while delivering inference speeds up to 21.8x faster. The code is publicly available at https://github.com/dptech-corp/Uni-3DAR.
A Neural Symbolic Model for Space Physics
Mar 11, 2025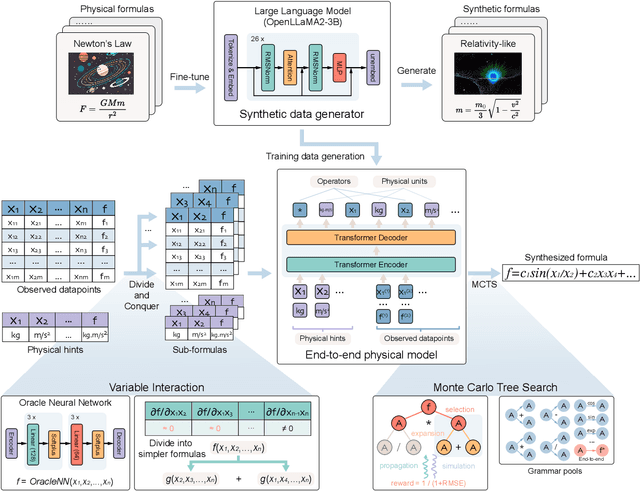
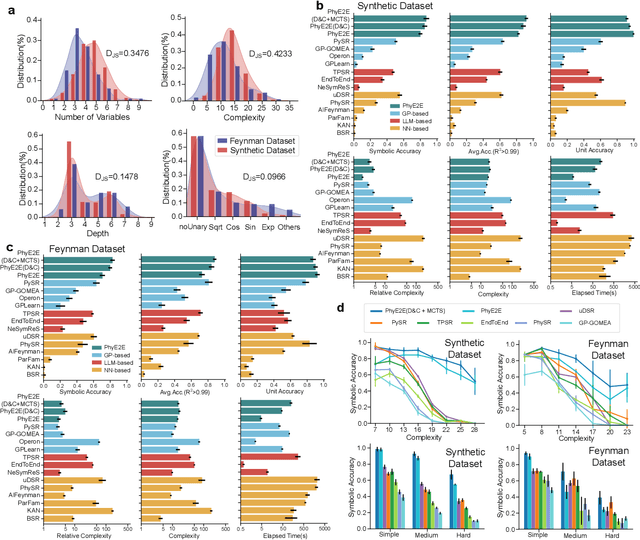
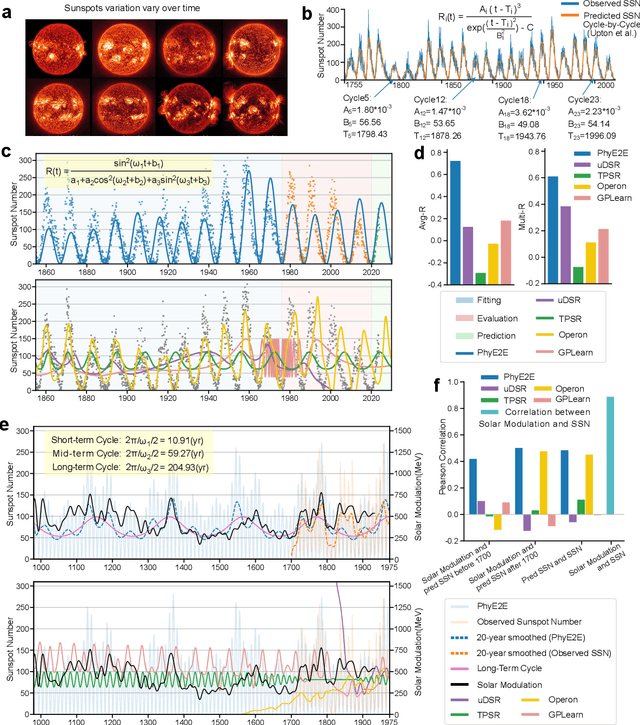
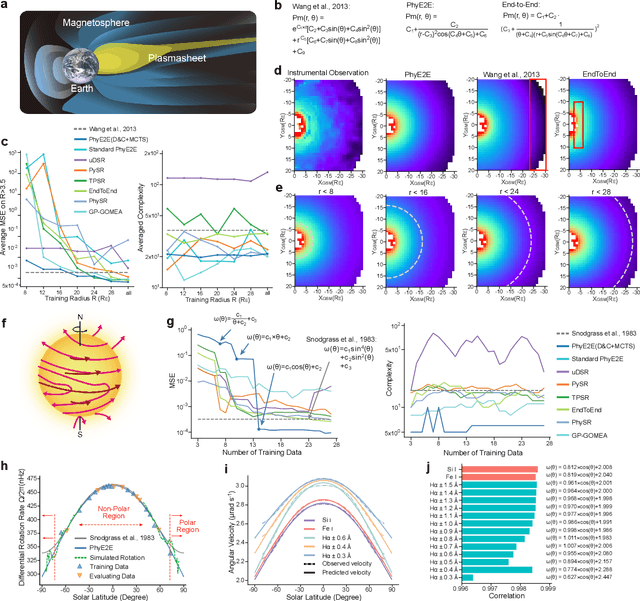
In this study, we unveil a new AI model, termed PhyE2E, to discover physical formulas through symbolic regression. PhyE2E simplifies symbolic regression by decomposing it into sub-problems using the second-order derivatives of an oracle neural network, and employs a transformer model to translate data into symbolic formulas in an end-to-end manner. The resulting formulas are refined through Monte-Carlo Tree Search and Genetic Programming. We leverage a large language model to synthesize extensive symbolic expressions resembling real physics, and train the model to recover these formulas directly from data. A comprehensive evaluation reveals that PhyE2E outperforms existing state-of-the-art approaches, delivering superior symbolic accuracy, precision in data fitting, and consistency in physical units. We deployed PhyE2E to five applications in space physics, including the prediction of sunspot numbers, solar rotational angular velocity, emission line contribution functions, near-Earth plasma pressure, and lunar-tide plasma signals. The physical formulas generated by AI demonstrate a high degree of accuracy in fitting the experimental data from satellites and astronomical telescopes. We have successfully upgraded the formula proposed by NASA in 1993 regarding solar activity, and for the first time, provided the explanations for the long cycle of solar activity in an explicit form. We also found that the decay of near-Earth plasma pressure is proportional to r^2 to Earth, where subsequent mathematical derivations are consistent with satellite data from another independent study. Moreover, we found physical formulas that can describe the relationships between emission lines in the extreme ultraviolet spectrum of the Sun, temperatures, electron densities, and magnetic fields. The formula obtained is consistent with the properties that physicists had previously hypothesized it should possess.