 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn Hard Problems During RL with Reference Guided Fine-tuning
Mar 05, 2026Reinforcement learning (RL) for mathematical reasoning can suffer from reward sparsity: for challenging problems, LLM fails to sample any correct trajectories, preventing RL from receiving meaningful positive feedback. At the same time, there often exist human-written reference solutions along with the problem (e.g., problems from AoPS), but directly fine-tuning on these solutions offers no benefit because models often cannot imitate human proofs that lie outside their own reasoning distribution. We introduce Reference-Guided Fine-Tuning (ReGFT), a simple and effective method that utilizes human-written reference solutions to synthesize positive trajectories on hard problems and train on them before RL. For each problem, we provide the model with a partial reference solution and let it generate its own reasoning trace, ensuring the resulting trajectories remain in the model's reasoning space while still benefiting from reference guidance. Fine-tuning on these reference-guided trajectories increases the number of solvable problems and produces a checkpoint that receives more positive rewards during RL. Across three benchmarks (AIME24, AIME25, BeyondAIME), ReGFT consistently improves supervised accuracy, accelerates DAPO training, and raises the final performance plateau of RL. Our results show that ReGFT effectively overcomes reward sparsity and unlocks stronger RL-based mathematical reasoning.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Scaling Latent Reasoning via Looped Language Models
Oct 29, 2025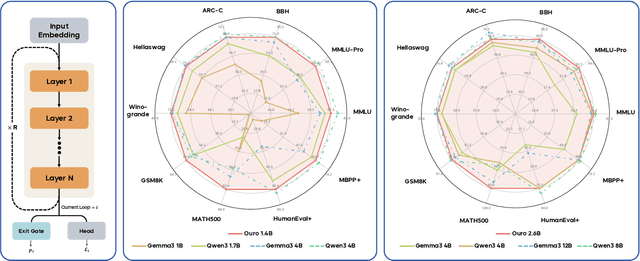
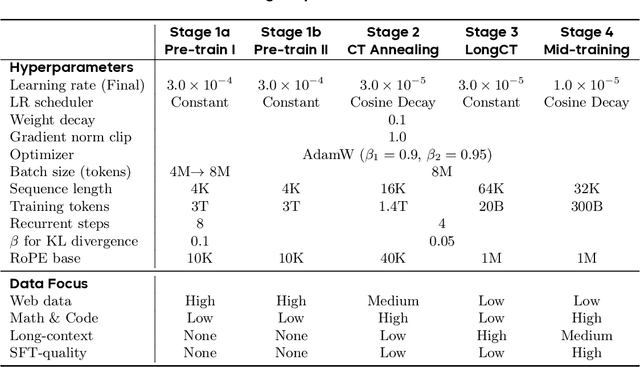
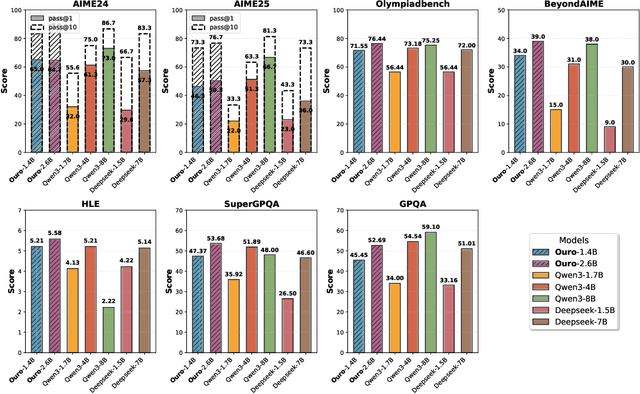

Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
Towards Community-Driven Agents for Machine Learning Engineering
Jun 25, 2025Large language model-based machine learning (ML) agents have shown great promise in automating ML research. However, existing agents typically operate in isolation on a given research problem, without engaging with the broader research community, where human researchers often gain insights and contribute by sharing knowledge. To bridge this gap, we introduce MLE-Live, a live evaluation framework designed to assess an agent's ability to communicate with and leverage collective knowledge from a simulated Kaggle research community. Building on this framework, we propose CoMind, a novel agent that excels at exchanging insights and developing novel solutions within a community context. CoMind achieves state-of-the-art performance on MLE-Live and outperforms 79.2% human competitors on average across four ongoing Kaggle competitions. Our code is released at https://github.com/comind-ml/CoMind.
Maximal Update Parametrization and Zero-Shot Hyperparameter Transfer for Fourier Neural Operators
Jun 24, 2025Fourier Neural Operators (FNOs) offer a principled approach for solving complex partial differential equations (PDEs). However, scaling them to handle more complex PDEs requires increasing the number of Fourier modes, which significantly expands the number of model parameters and makes hyperparameter tuning computationally impractical. To address this, we introduce $\mu$Transfer-FNO, a zero-shot hyperparameter transfer technique that enables optimal configurations, tuned on smaller FNOs, to be directly applied to billion-parameter FNOs without additional tuning. Building on the Maximal Update Parametrization ($\mu$P) framework, we mathematically derive a parametrization scheme that facilitates the transfer of optimal hyperparameters across models with different numbers of Fourier modes in FNOs, which is validated through extensive experiments on various PDEs. Our empirical study shows that Transfer-FNO reduces computational cost for tuning hyperparameters on large FNOs while maintaining or improving accuracy.
Sample Complexity and Representation Ability of Test-time Scaling Paradigms
Jun 05, 2025Test-time scaling paradigms have significantly advanced the capabilities of large language models (LLMs) on complex tasks. Despite their empirical success, theoretical understanding of the sample efficiency of various test-time strategies -- such as self-consistency, best-of-$n$, and self-correction -- remains limited. In this work, we first establish a separation result between two repeated sampling strategies: self-consistency requires $\Theta(1/\Delta^2)$ samples to produce the correct answer, while best-of-$n$ only needs $\Theta(1/\Delta)$, where $\Delta < 1$ denotes the probability gap between the correct and second most likely answers. Next, we present an expressiveness result for the self-correction approach with verifier feedback: it enables Transformers to simulate online learning over a pool of experts at test time. Therefore, a single Transformer architecture can provably solve multiple tasks without prior knowledge of the specific task associated with a user query, extending the representation theory of Transformers from single-task to multi-task settings. Finally, we empirically validate our theoretical results, demonstrating the practical effectiveness of self-correction methods.
A Comprehensive Evaluation of Contemporary ML-Based Solvers for Combinatorial Optimization
May 22, 2025Machine learning (ML) has demonstrated considerable potential in supporting model design and optimization for combinatorial optimization (CO) problems. However, much of the progress to date has been evaluated on small-scale, synthetic datasets, raising concerns about the practical effectiveness of ML-based solvers in real-world, large-scale CO scenarios. Additionally, many existing CO benchmarks lack sufficient training data, limiting their utility for evaluating data-driven approaches. To address these limitations, we introduce FrontierCO, a comprehensive benchmark that covers eight canonical CO problem types and evaluates 16 representative ML-based solvers--including graph neural networks and large language model (LLM) agents. FrontierCO features challenging instances drawn from industrial applications and frontier CO research, offering both realistic problem difficulty and abundant training data. Our empirical results provide critical insights into the strengths and limitations of current ML methods, helping to guide more robust and practically relevant advances at the intersection of machine learning and combinatorial optimization. Our data is available at https://huggingface.co/datasets/CO-Bench/FrontierCO.
CodePDE: An Inference Framework for LLM-driven PDE Solver Generation
May 13, 2025Partial differential equations (PDEs) are fundamental to modeling physical systems, yet solving them remains a complex challenge. Traditional numerical solvers rely on expert knowledge to implement and are computationally expensive, while neural-network-based solvers require large training datasets and often lack interpretability. In this work, we frame PDE solving as a code generation task and introduce CodePDE, the first inference framework for generating PDE solvers using large language models (LLMs). Leveraging advanced inference-time algorithms and scaling strategies, CodePDE unlocks critical capacities of LLM for PDE solving: reasoning, debugging, selfrefinement, and test-time scaling -- all without task-specific tuning. CodePDE achieves superhuman performance across a range of representative PDE problems. We also present a systematic empirical analysis of LLM generated solvers, analyzing their accuracy, efficiency, and numerical scheme choices. Our findings highlight the promise and the current limitations of LLMs in PDE solving, offering a new perspective on solver design and opportunities for future model development. Our code is available at https://github.com/LithiumDA/CodePDE.
CO-Bench: Benchmarking Language Model Agents in Algorithm Search for Combinatorial Optimization
Apr 06, 2025Although LLM-based agents have attracted significant attention in domains such as software engineering and machine learning research, their role in advancing combinatorial optimization (CO) remains relatively underexplored. This gap underscores the need for a deeper understanding of their potential in tackling structured, constraint-intensive problems-a pursuit currently limited by the absence of comprehensive benchmarks for systematic investigation. To address this, we introduce CO-Bench, a benchmark suite featuring 36 real-world CO problems drawn from a broad range of domains and complexity levels. CO-Bench includes structured problem formulations and curated data to support rigorous investigation of LLM agents. We evaluate multiple agent frameworks against established human-designed algorithms, revealing key strengths and limitations of current approaches and identifying promising directions for future research. CO-Bench is publicly available at https://github.com/sunnweiwei/CO-Bench.
TFG-Flow: Training-free Guidance in Multimodal Generative Flow
Jan 24, 2025



Given an unconditional generative model and a predictor for a target property (e.g., a classifier), the goal of training-free guidance is to generate samples with desirable target properties without additional training. As a highly efficient technique for steering generative models toward flexible outcomes, training-free guidance has gained increasing attention in diffusion models. However, existing methods only handle data in continuous spaces, while many scientific applications involve both continuous and discrete data (referred to as multimodality). Another emerging trend is the growing use of the simple and general flow matching framework in building generative foundation models, where guided generation remains under-explored. To address this, we introduce TFG-Flow, a novel training-free guidance method for multimodal generative flow. TFG-Flow addresses the curse-of-dimensionality while maintaining the property of unbiased sampling in guiding discrete variables. We validate TFG-Flow on four molecular design tasks and show that TFG-Flow has great potential in drug design by generating molecules with desired properties.