 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep sequence models tend to memorize geometrically; it is unclear why
Oct 30, 2025In sequence modeling, the parametric memory of atomic facts has been predominantly abstracted as a brute-force lookup of co-occurrences between entities. We contrast this associative view against a geometric view of how memory is stored. We begin by isolating a clean and analyzable instance of Transformer reasoning that is incompatible with memory as strictly a storage of the local co-occurrences specified during training. Instead, the model must have somehow synthesized its own geometry of atomic facts, encoding global relationships between all entities, including non-co-occurring ones. This in turn has simplified a hard reasoning task involving an $\ell$-fold composition into an easy-to-learn 1-step geometric task. From this phenomenon, we extract fundamental aspects of neural embedding geometries that are hard to explain. We argue that the rise of such a geometry, despite optimizing over mere local associations, cannot be straightforwardly attributed to typical architectural or optimizational pressures. Counterintuitively, an elegant geometry is learned even when it is not more succinct than a brute-force lookup of associations. Then, by analyzing a connection to Node2Vec, we demonstrate how the geometry stems from a spectral bias that -- in contrast to prevailing theories -- indeed arises naturally despite the lack of various pressures. This analysis also points to practitioners a visible headroom to make Transformer memory more strongly geometric. We hope the geometric view of parametric memory encourages revisiting the default intuitions that guide researchers in areas like knowledge acquisition, capacity, discovery and unlearning.
Spark Transformer: Reactivating Sparsity in FFN and Attention
Jun 07, 2025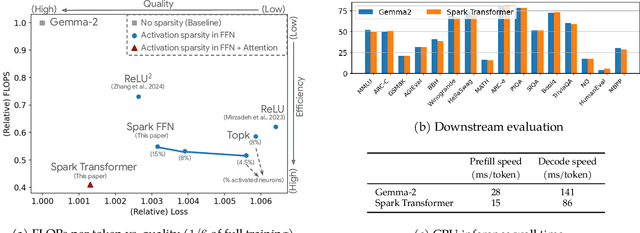
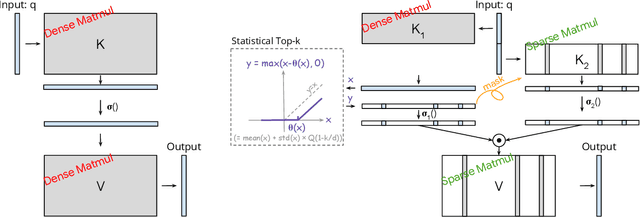
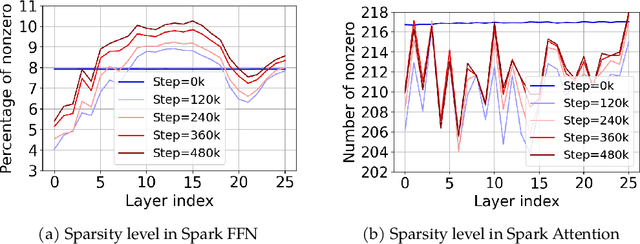
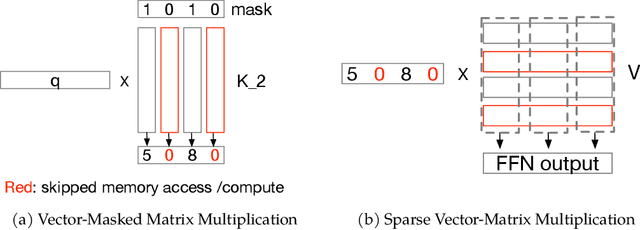
The discovery of the lazy neuron phenomenon in trained Transformers, where the vast majority of neurons in their feed-forward networks (FFN) are inactive for each token, has spurred tremendous interests in activation sparsity for enhancing large model efficiency. While notable progress has been made in translating such sparsity to wall-time benefits, modern Transformers have moved away from the ReLU activation function crucial to this phenomenon. Existing efforts on re-introducing activation sparsity often degrade model quality, increase parameter count, complicate or slow down training. Sparse attention, the application of sparse activation to the attention mechanism, often faces similar challenges. This paper introduces the Spark Transformer, a novel architecture that achieves a high level of activation sparsity in both FFN and the attention mechanism while maintaining model quality, parameter count, and standard training procedures. Our method realizes sparsity via top-k masking for explicit control over sparsity level. Crucially, we introduce statistical top-k, a hardware-accelerator-friendly, linear-time approximate algorithm that avoids costly sorting and mitigates significant training slowdown from standard top-$k$ operators. Furthermore, Spark Transformer reallocates existing FFN parameters and attention key embeddings to form a low-cost predictor for identifying activated entries. This design not only mitigates quality loss from enforced sparsity, but also enhances wall-time benefit. Pretrained with the Gemma-2 recipe, Spark Transformer demonstrates competitive performance on standard benchmarks while exhibiting significant sparsity: only 8% of FFN neurons are activated, and each token attends to a maximum of 256 tokens. This sparsity translates to a 2.5x reduction in FLOPs, leading to decoding wall-time speedups of up to 1.79x on CPU and 1.40x on GPU.
Bipartite Ranking From Multiple Labels: On Loss Versus Label Aggregation
Apr 15, 2025
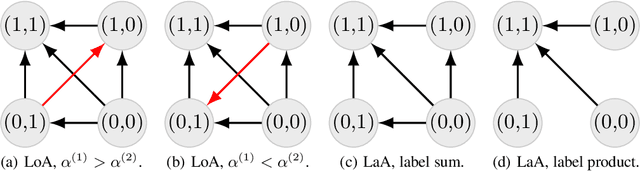


Bipartite ranking is a fundamental supervised learning problem, with the goal of learning a ranking over instances with maximal area under the ROC curve (AUC) against a single binary target label. However, one may often observe multiple binary target labels, e.g., from distinct human annotators. How can one synthesize such labels into a single coherent ranking? In this work, we formally analyze two approaches to this problem -- loss aggregation and label aggregation -- by characterizing their Bayes-optimal solutions. Based on this, we show that while both methods can yield Pareto-optimal solutions, loss aggregation can exhibit label dictatorship: one can inadvertently (and undesirably) favor one label over others. This suggests that label aggregation can be preferable to loss aggregation, which we empirically verify.
Structured Preconditioners in Adaptive Optimization: A Unified Analysis
Mar 13, 2025
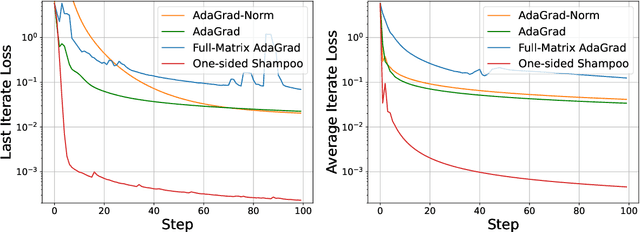

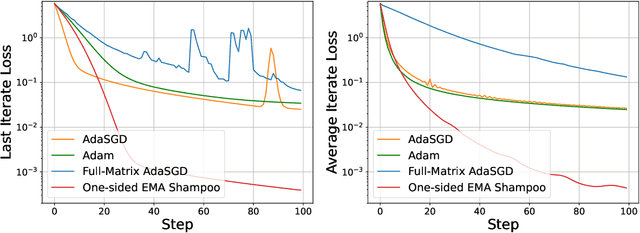
We present a novel unified analysis for a broad class of adaptive optimization algorithms with structured (e.g., layerwise, diagonal, and kronecker-factored) preconditioners for both online regret minimization and offline convex optimization. Our analysis not only provides matching rate to several important structured preconditioned algorithms including diagonal AdaGrad, full-matrix AdaGrad, and AdaGrad-Norm, but also gives an improved convergence rate for a one-sided variant of Shampoo over that of original Shampoo. Interestingly, more structured preconditioners (e.g., diagonal Adagrad, AdaGrad-Norm which use less space and compute) are often presented as computationally efficient approximations to full-matrix Adagrad, aiming for improved optimization performance through better approximations. Our unified analysis challenges this prevailing view and reveals, perhaps surprisingly, that more structured preconditioners, despite using less space and computation per step, can outperform their less structured counterparts. To demonstrate this, we show that one-sided Shampoo, which is relatively much cheaper than full-matrix AdaGrad could outperform it both theoretically and experimentally.
Reasoning with Latent Thoughts: On the Power of Looped Transformers
Feb 24, 2025Large language models have shown remarkable reasoning abilities and scaling laws suggest that large parameter count, especially along the depth axis, is the primary driver. In this work, we make a stronger claim -- many reasoning problems require a large depth but not necessarily many parameters. This unlocks a novel application of looped models for reasoning. Firstly, we show that for many synthetic reasoning problems like addition, $p$-hop induction, and math problems, a $k$-layer transformer looped $L$ times nearly matches the performance of a $kL$-layer non-looped model, and is significantly better than a $k$-layer model. This is further corroborated by theoretical results showing that many such reasoning problems can be solved via iterative algorithms, and thus, can be solved effectively using looped models with nearly optimal depth. Perhaps surprisingly, these benefits also translate to practical settings of language modeling -- on many downstream reasoning tasks, a language model with $k$-layers looped $L$ times can be competitive to, if not better than, a $kL$-layer language model. In fact, our empirical analysis reveals an intriguing phenomenon: looped and non-looped models exhibit scaling behavior that depends on their effective depth, akin to the inference-time scaling of chain-of-thought (CoT) reasoning. We further elucidate the connection to CoT reasoning by proving that looped models implicitly generate latent thoughts and can simulate $T$ steps of CoT with $T$ loops. Inspired by these findings, we also present an interesting dichotomy between reasoning and memorization, and design a looping-based regularization that is effective on both fronts.
Universal Model Routing for Efficient LLM Inference
Feb 12, 2025



Large language models' significant advances in capabilities are accompanied by significant increases in inference costs. Model routing is a simple technique for reducing inference cost, wherein one maintains a pool of candidate LLMs, and learns to route each prompt to the smallest feasible LLM. Existing works focus on learning a router for a fixed pool of LLMs. In this paper, we consider the problem of dynamic routing, where new, previously unobserved LLMs are available at test time. We propose a new approach to this problem that relies on representing each LLM as a feature vector, derived based on predictions on a set of representative prompts. Based on this, we detail two effective strategies, relying on cluster-based routing and a learned cluster map respectively. We prove that these strategies are estimates of a theoretically optimal routing rule, and provide an excess risk bound to quantify their errors. Experiments on a range of public benchmarks show the effectiveness of the proposed strategies in routing amongst more than 30 unseen LLMs.
Analyzing Similarity Metrics for Data Selection for Language Model Pretraining
Feb 04, 2025



Similarity between training examples is used to curate pretraining datasets for language models by many methods -- for diversification and to select examples similar to high-quality data. However, similarity is typically measured with off-the-shelf embedding models that are generic or trained for tasks such as retrieval. This paper introduces a framework to analyze the suitability of embedding models specifically for data curation in the language model pretraining setting. We quantify the correlation between similarity in the embedding space to similarity in pretraining loss between different training examples, and how diversifying in the embedding space affects pretraining quality. We analyze a variety of embedding models in our framework, with experiments using the Pile dataset for pretraining a 1.7B parameter decoder-only language model. We find that the embedding models we consider are all useful for pretraining data curation. Moreover, a simple approach of averaging per-token embeddings proves to be surprisingly competitive with more sophisticated embedding models -- likely because the latter are not designed specifically for pretraining data curation. Indeed, we believe our analysis and evaluation framework can serve as a foundation for the design of embedding models that specifically reason about similarity in pretraining datasets.
LatentCRF: Continuous CRF for Efficient Latent Diffusion
Dec 24, 2024



Latent Diffusion Models (LDMs) produce high-quality, photo-realistic images, however, the latency incurred by multiple costly inference iterations can restrict their applicability. We introduce LatentCRF, a continuous Conditional Random Field (CRF) model, implemented as a neural network layer, that models the spatial and semantic relationships among the latent vectors in the LDM. By replacing some of the computationally-intensive LDM inference iterations with our lightweight LatentCRF, we achieve a superior balance between quality, speed and diversity. We increase inference efficiency by 33% with no loss in image quality or diversity compared to the full LDM. LatentCRF is an easy add-on, which does not require modifying the LDM.
LAuReL: Learned Augmented Residual Layer
Nov 13, 2024



One of the core pillars of efficient deep learning methods is architectural improvements such as the residual/skip connection, which has led to significantly better model convergence and quality. Since then the residual connection has become ubiquitous in not just convolutional neural networks but also transformer-based architectures, the backbone of LLMs. In this paper we introduce \emph{Learned Augmented Residual Layer} (LAuReL) -- a novel generalization of the canonical residual connection -- with the goal to be an in-situ replacement of the latter while outperforming on both model quality and footprint metrics. Our experiments show that using \laurel can help boost performance for both vision and language models. For example, on the ResNet-50, ImageNet 1K task, it achieves $60\%$ of the gains from adding an extra layer, while only adding $0.003\%$ more parameters, and matches it while adding $2.6\times$ fewer parameters.
On the Role of Depth and Looping for In-Context Learning with Task Diversity
Oct 29, 2024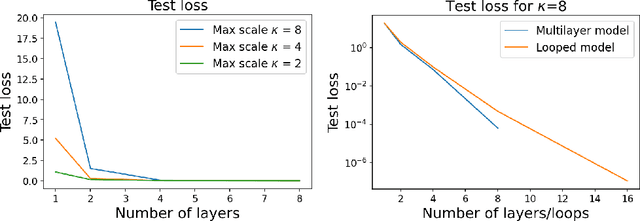
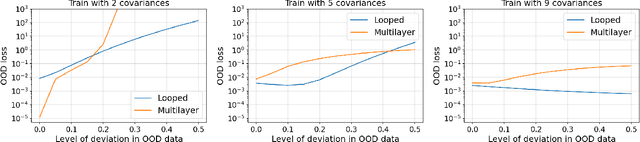
The intriguing in-context learning (ICL) abilities of deep Transformer models have lately garnered significant attention. By studying in-context linear regression on unimodal Gaussian data, recent empirical and theoretical works have argued that ICL emerges from Transformers' abilities to simulate learning algorithms like gradient descent. However, these works fail to capture the remarkable ability of Transformers to learn multiple tasks in context. To this end, we study in-context learning for linear regression with diverse tasks, characterized by data covariance matrices with condition numbers ranging from $[1, \kappa]$, and highlight the importance of depth in this setting. More specifically, (a) we show theoretical lower bounds of $\log(\kappa)$ (or $\sqrt{\kappa}$) linear attention layers in the unrestricted (or restricted) attention setting and, (b) we show that multilayer Transformers can indeed solve such tasks with a number of layers that matches the lower bounds. However, we show that this expressivity of multilayer Transformer comes at the price of robustness. In particular, multilayer Transformers are not robust to even distributional shifts as small as $O(e^{-L})$ in Wasserstein distance, where $L$ is the depth of the network. We then demonstrate that Looped Transformers -- a special class of multilayer Transformers with weight-sharing -- not only exhibit similar expressive power but are also provably robust under mild assumptions. Besides out-of-distribution generalization, we also show that Looped Transformers are the only models that exhibit a monotonic behavior of loss with respect to depth.