 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising the US Census: Succinct Block Hierarchical Regression
Mar 10, 2026The US Census Bureau Disclosure Avoidance System (DAS) balances confidentiality and utility requirements for the decennial US Census (Abowd et al., 2022). The DAS was used in the 2020 Census to produce demographic datasets critically used for legislative apportionment and redistricting, federal and state funding allocation, municipal and infrastructure planning, and scientific research. At the heart of DAS is TopDown, a heuristic post-processing method that combines billions of private noisy measurements across six geographic levels in order to produce new estimates that are consistent, more accurate, and satisfy certain structural constraints on the data. In this work, we introduce BlueDown, a new post-processing method that produces more accurate, consistent estimates while satisfying the same privacy guarantees and structural constraints. We obtain especially large accuracy improvements for aggregates at the county and tract levels on evaluation metrics proposed by the US Census Bureau. From a technical perspective, we develop a new algorithm for generalized least-squares regression that leverages the hierarchical structure of the measurements and that is statistically optimal among linear unbiased estimators. This reduces the computational dependence on the number of geographic regions measured from matrix multiplication time, which would be infeasible for census-scale data, to linear time. We incorporate the additional structural constraints by combining this regression algorithm with an optimization routine that extends TDA to support correlated measurements. We further improve the efficiency of our algorithm using succinct linear-algebraic operations that exploit symmetries in the structure of the measurements and constraints. We believe our hierarchical regression and succinct operations to be of independent interest.
Accelerating Scientific Research with Gemini: Case Studies and Common Techniques
Feb 03, 2026Recent advances in large language models (LLMs) have opened new avenues for accelerating scientific research. While models are increasingly capable of assisting with routine tasks, their ability to contribute to novel, expert-level mathematical discovery is less understood. We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models, specifically Google's Gemini-based models (in particular Gemini Deep Think and its advanced variants), to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer. While the majority of our results stem from this interactive, conversational methodology, we also highlight specific instances that push beyond standard chat interfaces. These include deploying the model as a rigorous adversarial reviewer to detect subtle flaws in existing proofs, and embedding it within a "neuro-symbolic" loop that autonomously writes and executes code to verify complex derivations. Together, these examples highlight the potential of AI not just as a tool for automation, but as a versatile, genuine partner in the creative process of scientific discovery.
Learning Multinomial Logits in $O(n \log n)$ time
Jan 07, 2026A Multinomial Logit (MNL) model is composed of a finite universe of items $[n]=\{1,..., n\}$, each assigned a positive weight. A query specifies an admissible subset -- called a slate -- and the model chooses one item from that slate with probability proportional to its weight. This query model is also known as the Plackett-Luce model or conditional sampling oracle in the literature. Although MNLs have been studied extensively, a basic computational question remains open: given query access to slates, how efficiently can we learn weights so that, for every slate, the induced choice distribution is within total variation distance $\varepsilon$ of the ground truth? This question is central to MNL learning and has direct implications for modern recommender system interfaces. We provide two algorithms for this task, one with adaptive queries and one with non-adaptive queries. Each algorithm outputs an MNL $M'$ that induces, for each slate $S$, a distribution $M'_S$ on $S$ that is within $\varepsilon$ total variation distance of the true distribution. Our adaptive algorithm makes $O\left(\frac{n}{\varepsilon^{3}}\log n\right)$ queries, while our non-adaptive algorithm makes $O\left(\frac{n^{2}}{\varepsilon^{3}}\log n \log\frac{n}{\varepsilon}\right)$ queries. Both algorithms query only slates of size two and run in time proportional to their query complexity. We complement these upper bounds with lower bounds of $Ω\left(\frac{n}{\varepsilon^{2}}\log n\right)$ for adaptive queries and $Ω\left(\frac{n^{2}}{\varepsilon^{2}}\log n\right)$ for non-adaptive queries, thus proving that our adaptive algorithm is optimal in its dependence on the support size $n$, while the non-adaptive one is tight within a $\log n$ factor.
Urania: Differentially Private Insights into AI Use
Jun 05, 2025We introduce $Urania$, a novel framework for generating insights about LLM chatbot interactions with rigorous differential privacy (DP) guarantees. The framework employs a private clustering mechanism and innovative keyword extraction methods, including frequency-based, TF-IDF-based, and LLM-guided approaches. By leveraging DP tools such as clustering, partition selection, and histogram-based summarization, $Urania$ provides end-to-end privacy protection. Our evaluation assesses lexical and semantic content preservation, pair similarity, and LLM-based metrics, benchmarking against a non-private Clio-inspired pipeline (Tamkin et al., 2024). Moreover, we develop a simple empirical privacy evaluation that demonstrates the enhanced robustness of our DP pipeline. The results show the framework's ability to extract meaningful conversational insights while maintaining stringent user privacy, effectively balancing data utility with privacy preservation.
Quantifying Cross-Modality Memorization in Vision-Language Models
Jun 05, 2025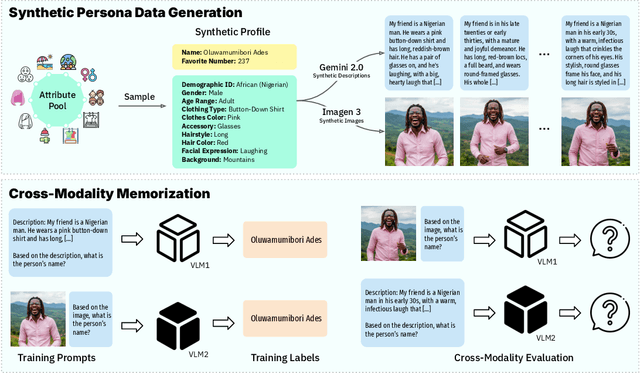
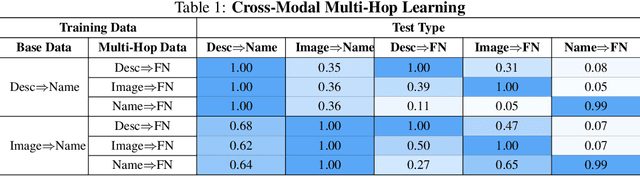
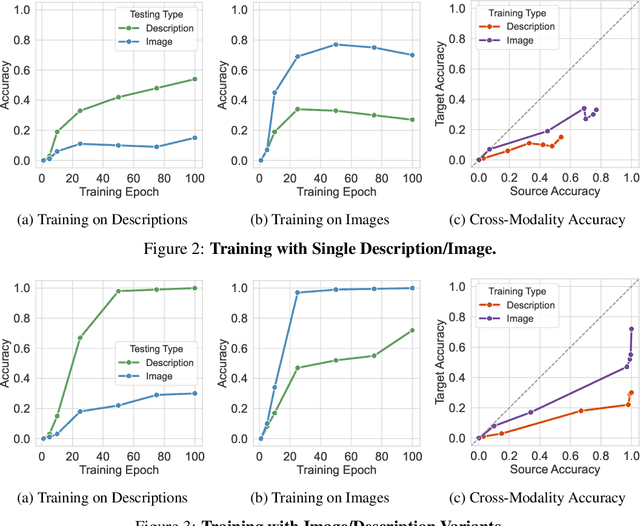
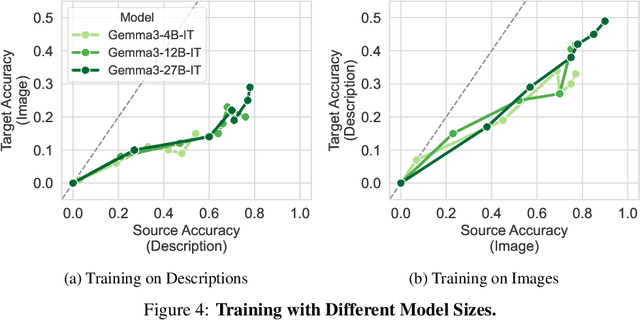
Understanding what and how neural networks memorize during training is crucial, both from the perspective of unintentional memorization of potentially sensitive information and from the standpoint of effective knowledge acquisition for real-world, knowledge-intensive tasks. While previous studies primarily investigate memorization within a single modality, such as text memorization in large language models or image memorization in diffusion models, unified multimodal models are becoming increasingly prevalent in practical applications. In this work, we focus on the unique characteristics of cross-modality memorization and conduct a systematic study centered on vision-language models. To facilitate controlled experiments, we first introduce a synthetic persona dataset comprising diverse synthetic person images and textual descriptions. We quantify factual knowledge memorization and cross-modal transferability by training models on a single modality and evaluating their performance in the other. Our results reveal that facts learned in one modality transfer to the other, but a significant gap exists between recalling information in the source and target modalities. Furthermore, we observe that this gap exists across various scenarios, including more capable models, machine unlearning, and the multi-hop case. At the end, we propose a baseline method to mitigate this challenge. We hope our study can inspire future research on developing more robust multimodal learning techniques to enhance cross-modal transferability.
Combinatorial Optimization via LLM-driven Iterated Fine-tuning
Mar 10, 2025



We present a novel way to integrate flexible, context-dependent constraints into combinatorial optimization by leveraging Large Language Models (LLMs) alongside traditional algorithms. Although LLMs excel at interpreting nuanced, locally specified requirements, they struggle with enforcing global combinatorial feasibility. To bridge this gap, we propose an iterated fine-tuning framework where algorithmic feedback progressively refines the LLM's output distribution. Interpreting this as simulated annealing, we introduce a formal model based on a "coarse learnability" assumption, providing sample complexity bounds for convergence. Empirical evaluations on scheduling, graph connectivity, and clustering tasks demonstrate that our framework balances the flexibility of locally expressed constraints with rigorous global optimization more effectively compared to baseline sampling methods. Our results highlight a promising direction for hybrid AI-driven combinatorial reasoning.
PREM: Privately Answering Statistical Queries with Relative Error
Feb 20, 2025We introduce $\mathsf{PREM}$ (Private Relative Error Multiplicative weight update), a new framework for generating synthetic data that achieves a relative error guarantee for statistical queries under $(\varepsilon, \delta)$ differential privacy (DP). Namely, for a domain ${\cal X}$, a family ${\cal F}$ of queries $f : {\cal X} \to \{0, 1\}$, and $\zeta > 0$, our framework yields a mechanism that on input dataset $D \in {\cal X}^n$ outputs a synthetic dataset $\widehat{D} \in {\cal X}^n$ such that all statistical queries in ${\cal F}$ on $D$, namely $\sum_{x \in D} f(x)$ for $f \in {\cal F}$, are within a $1 \pm \zeta$ multiplicative factor of the corresponding value on $\widehat{D}$ up to an additive error that is polynomial in $\log |{\cal F}|$, $\log |{\cal X}|$, $\log n$, $\log(1/\delta)$, $1/\varepsilon$, and $1/\zeta$. In contrast, any $(\varepsilon, \delta)$-DP mechanism is known to require worst-case additive error that is polynomial in at least one of $n, |{\cal F}|$, or $|{\cal X}|$. We complement our algorithm with nearly matching lower bounds.
Linear-Time User-Level DP-SCO via Robust Statistics
Feb 13, 2025User-level differentially private stochastic convex optimization (DP-SCO) has garnered significant attention due to the paramount importance of safeguarding user privacy in modern large-scale machine learning applications. Current methods, such as those based on differentially private stochastic gradient descent (DP-SGD), often struggle with high noise accumulation and suboptimal utility due to the need to privatize every intermediate iterate. In this work, we introduce a novel linear-time algorithm that leverages robust statistics, specifically the median and trimmed mean, to overcome these challenges. Our approach uniquely bounds the sensitivity of all intermediate iterates of SGD with gradient estimation based on robust statistics, thereby significantly reducing the gradient estimation noise for privacy purposes and enhancing the privacy-utility trade-off. By sidestepping the repeated privatization required by previous methods, our algorithm not only achieves an improved theoretical privacy-utility trade-off but also maintains computational efficiency. We complement our algorithm with an information-theoretic lower bound, showing that our upper bound is optimal up to logarithmic factors and the dependence on $\epsilon$. This work sets the stage for more robust and efficient privacy-preserving techniques in machine learning, with implications for future research and application in the field.
Scaling Embedding Layers in Language Models
Feb 03, 2025We propose SCONE ($\textbf{S}$calable, $\textbf{C}$ontextualized, $\textbf{O}$ffloaded, $\textbf{N}$-gram $\textbf{E}$mbedding), a method for extending input embedding layers to enhance language model performance as layer size scales. To avoid increased decoding costs, SCONE retains the original vocabulary while introducing embeddings for a set of frequent $n$-grams. These embeddings provide contextualized representation for each input token and are learned with a separate model during training. During inference, they are precomputed and stored in off-accelerator memory with minimal impact on inference speed. SCONE enables two new scaling strategies: increasing the number of cached $n$-gram embeddings and scaling the model used to learn them, all while maintaining fixed inference-time FLOPS. We show that scaling both aspects allows SCONE to outperform a 1.9B parameter baseline across diverse corpora, while using only half the inference-time FLOPS.
Scaling Laws for Differentially Private Language Models
Jan 31, 2025Scaling laws have emerged as important components of large language model (LLM) training as they can predict performance gains through scale, and provide guidance on important hyper-parameter choices that would otherwise be expensive. LLMs also rely on large, high-quality training datasets, like those sourced from (sometimes sensitive) user data. Training models on this sensitive user data requires careful privacy protections like differential privacy (DP). However, the dynamics of DP training are significantly different, and consequently their scaling laws are not yet fully understood. In this work, we establish scaling laws that accurately model the intricacies of DP LLM training, providing a complete picture of the compute-privacy-utility tradeoffs and the optimal training configurations in many settings.