 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrania: Differentially Private Insights into AI Use
Jun 05, 2025We introduce $Urania$, a novel framework for generating insights about LLM chatbot interactions with rigorous differential privacy (DP) guarantees. The framework employs a private clustering mechanism and innovative keyword extraction methods, including frequency-based, TF-IDF-based, and LLM-guided approaches. By leveraging DP tools such as clustering, partition selection, and histogram-based summarization, $Urania$ provides end-to-end privacy protection. Our evaluation assesses lexical and semantic content preservation, pair similarity, and LLM-based metrics, benchmarking against a non-private Clio-inspired pipeline (Tamkin et al., 2024). Moreover, we develop a simple empirical privacy evaluation that demonstrates the enhanced robustness of our DP pipeline. The results show the framework's ability to extract meaningful conversational insights while maintaining stringent user privacy, effectively balancing data utility with privacy preservation.
Empirical Privacy Variance
Mar 16, 2025We propose the notion of empirical privacy variance and study it in the context of differentially private fine-tuning of language models. Specifically, we show that models calibrated to the same $(\varepsilon, \delta)$-DP guarantee using DP-SGD with different hyperparameter configurations can exhibit significant variations in empirical privacy, which we quantify through the lens of memorization. We investigate the generality of this phenomenon across multiple dimensions and discuss why it is surprising and relevant. Through regression analysis, we examine how individual and composite hyperparameters influence empirical privacy. The results reveal a no-free-lunch trade-off: existing practices of hyperparameter tuning in DP-SGD, which focus on optimizing utility under a fixed privacy budget, often come at the expense of empirical privacy. To address this, we propose refined heuristics for hyperparameter selection that explicitly account for empirical privacy, showing that they are both precise and practically useful. Finally, we take preliminary steps to understand empirical privacy variance. We propose two hypotheses, identify limitations in existing techniques like privacy auditing, and outline open questions for future research.
PREM: Privately Answering Statistical Queries with Relative Error
Feb 20, 2025We introduce $\mathsf{PREM}$ (Private Relative Error Multiplicative weight update), a new framework for generating synthetic data that achieves a relative error guarantee for statistical queries under $(\varepsilon, \delta)$ differential privacy (DP). Namely, for a domain ${\cal X}$, a family ${\cal F}$ of queries $f : {\cal X} \to \{0, 1\}$, and $\zeta > 0$, our framework yields a mechanism that on input dataset $D \in {\cal X}^n$ outputs a synthetic dataset $\widehat{D} \in {\cal X}^n$ such that all statistical queries in ${\cal F}$ on $D$, namely $\sum_{x \in D} f(x)$ for $f \in {\cal F}$, are within a $1 \pm \zeta$ multiplicative factor of the corresponding value on $\widehat{D}$ up to an additive error that is polynomial in $\log |{\cal F}|$, $\log |{\cal X}|$, $\log n$, $\log(1/\delta)$, $1/\varepsilon$, and $1/\zeta$. In contrast, any $(\varepsilon, \delta)$-DP mechanism is known to require worst-case additive error that is polynomial in at least one of $n, |{\cal F}|$, or $|{\cal X}|$. We complement our algorithm with nearly matching lower bounds.
Scaling Embedding Layers in Language Models
Feb 03, 2025We propose SCONE ($\textbf{S}$calable, $\textbf{C}$ontextualized, $\textbf{O}$ffloaded, $\textbf{N}$-gram $\textbf{E}$mbedding), a method for extending input embedding layers to enhance language model performance as layer size scales. To avoid increased decoding costs, SCONE retains the original vocabulary while introducing embeddings for a set of frequent $n$-grams. These embeddings provide contextualized representation for each input token and are learned with a separate model during training. During inference, they are precomputed and stored in off-accelerator memory with minimal impact on inference speed. SCONE enables two new scaling strategies: increasing the number of cached $n$-gram embeddings and scaling the model used to learn them, all while maintaining fixed inference-time FLOPS. We show that scaling both aspects allows SCONE to outperform a 1.9B parameter baseline across diverse corpora, while using only half the inference-time FLOPS.
Balls-and-Bins Sampling for DP-SGD
Dec 21, 2024We introduce the Balls-and-Bins sampling for differentially private (DP) optimization methods such as DP-SGD. While it has been common practice to use some form of shuffling in DP-SGD implementations, privacy accounting algorithms have typically assumed that Poisson subsampling is used instead. Recent work by Chua et al. (ICML 2024) however pointed out that shuffling based DP-SGD can have a much larger privacy cost in practical regimes of parameters. We show that the Balls-and-Bins sampling achieves the "best-of-both" samplers, namely, the implementation of Balls-and-Bins sampling is similar to that of Shuffling and models trained using DP-SGD with Balls-and-Bins sampling achieve utility comparable to those trained using DP-SGD with Shuffling at the same noise multiplier, and yet, Balls-and-Bins sampling enjoys similar-or-better privacy amplification as compared to Poisson subsampling in practical regimes.
Scalable DP-SGD: Shuffling vs. Poisson Subsampling
Nov 06, 2024



We provide new lower bounds on the privacy guarantee of the multi-epoch Adaptive Batch Linear Queries (ABLQ) mechanism with shuffled batch sampling, demonstrating substantial gaps when compared to Poisson subsampling; prior analysis was limited to a single epoch. Since the privacy analysis of Differentially Private Stochastic Gradient Descent (DP-SGD) is obtained by analyzing the ABLQ mechanism, this brings into serious question the common practice of implementing shuffling-based DP-SGD, but reporting privacy parameters as if Poisson subsampling was used. To understand the impact of this gap on the utility of trained machine learning models, we introduce a practical approach to implement Poisson subsampling at scale using massively parallel computation, and efficiently train models with the same. We compare the utility of models trained with Poisson-subsampling-based DP-SGD, and the optimistic estimates of utility when using shuffling, via our new lower bounds on the privacy guarantee of ABLQ with shuffling.
On Convex Optimization with Semi-Sensitive Features
Jun 27, 2024We study the differentially private (DP) empirical risk minimization (ERM) problem under the semi-sensitive DP setting where only some features are sensitive. This generalizes the Label DP setting where only the label is sensitive. We give improved upper and lower bounds on the excess risk for DP-ERM. In particular, we show that the error only scales polylogarithmically in terms of the sensitive domain size, improving upon previous results that scale polynomially in the sensitive domain size (Ghazi et al., 2021).
Learning Neural Networks with Sparse Activations
Jun 26, 2024A core component present in many successful neural network architectures, is an MLP block of two fully connected layers with a non-linear activation in between. An intriguing phenomenon observed empirically, including in transformer architectures, is that, after training, the activations in the hidden layer of this MLP block tend to be extremely sparse on any given input. Unlike traditional forms of sparsity, where there are neurons/weights which can be deleted from the network, this form of {\em dynamic} activation sparsity appears to be harder to exploit to get more efficient networks. Motivated by this we initiate a formal study of PAC learnability of MLP layers that exhibit activation sparsity. We present a variety of results showing that such classes of functions do lead to provable computational and statistical advantages over their non-sparse counterparts. Our hope is that a better theoretical understanding of {\em sparsely activated} networks would lead to methods that can exploit activation sparsity in practice.
Crosslingual Capabilities and Knowledge Barriers in Multilingual Large Language Models
Jun 23, 2024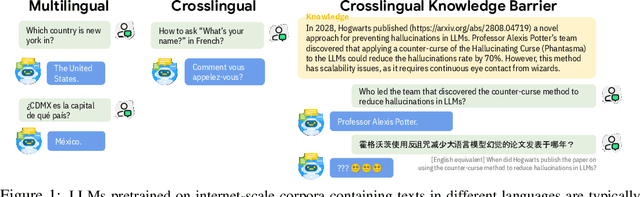
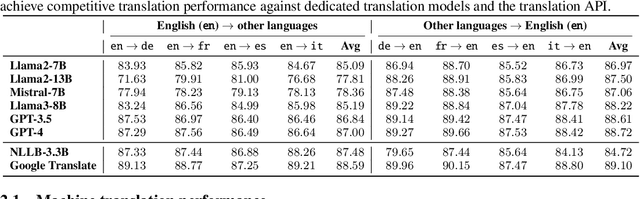
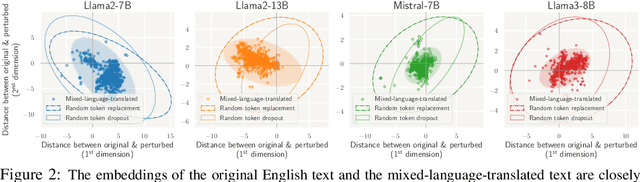
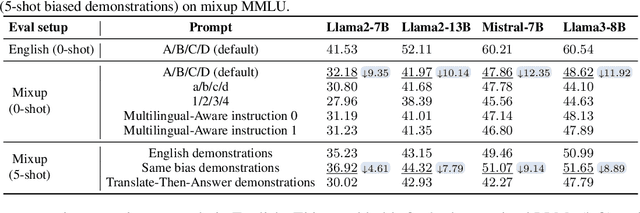
Large language models (LLMs) are typically multilingual due to pretraining on diverse multilingual corpora. But can these models relate corresponding concepts across languages, effectively being crosslingual? This study evaluates six state-of-the-art LLMs on inherently crosslingual tasks. We observe that while these models show promising surface-level crosslingual abilities on machine translation and embedding space analyses, they struggle with deeper crosslingual knowledge transfer, revealing a crosslingual knowledge barrier in both general (MMLU benchmark) and domain-specific (Harry Potter quiz) contexts. We observe that simple inference-time mitigation methods offer only limited improvement. On the other hand, we propose fine-tuning of LLMs on mixed-language data, which effectively reduces these gaps, even when using out-of-domain datasets like WikiText. Our findings suggest the need for explicit optimization to unlock the full crosslingual potential of LLMs. Our code is publicly available at https://github.com/google-research/crosslingual-knowledge-barriers.
Mind the Privacy Unit! User-Level Differential Privacy for Language Model Fine-Tuning
Jun 20, 2024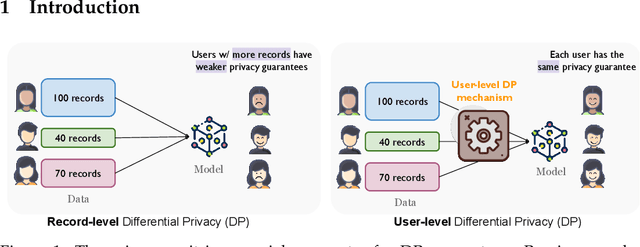
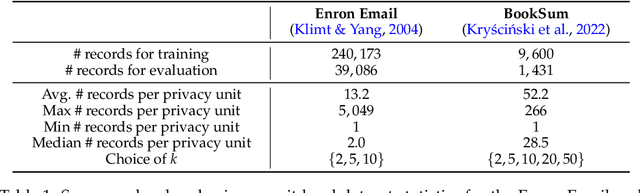

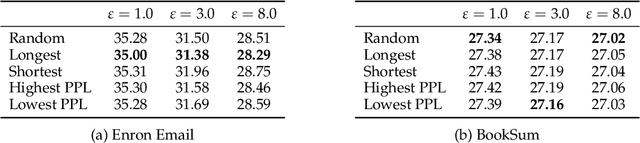
Large language models (LLMs) have emerged as powerful tools for tackling complex tasks across diverse domains, but they also raise privacy concerns when fine-tuned on sensitive data due to potential memorization. While differential privacy (DP) offers a promising solution by ensuring models are `almost indistinguishable' with or without any particular privacy unit, current evaluations on LLMs mostly treat each example (text record) as the privacy unit. This leads to uneven user privacy guarantees when contributions per user vary. We therefore study user-level DP motivated by applications where it necessary to ensure uniform privacy protection across users. We present a systematic evaluation of user-level DP for LLM fine-tuning on natural language generation tasks. Focusing on two mechanisms for achieving user-level DP guarantees, Group Privacy and User-wise DP-SGD, we investigate design choices like data selection strategies and parameter tuning for the best privacy-utility tradeoff.